
P Stage 2 : Project Day 1
Day 1 list
- 대회 Data EDA
- NGCF 적용 대비해서 Graph 변형 코드 작성
대회 데이터 EDA
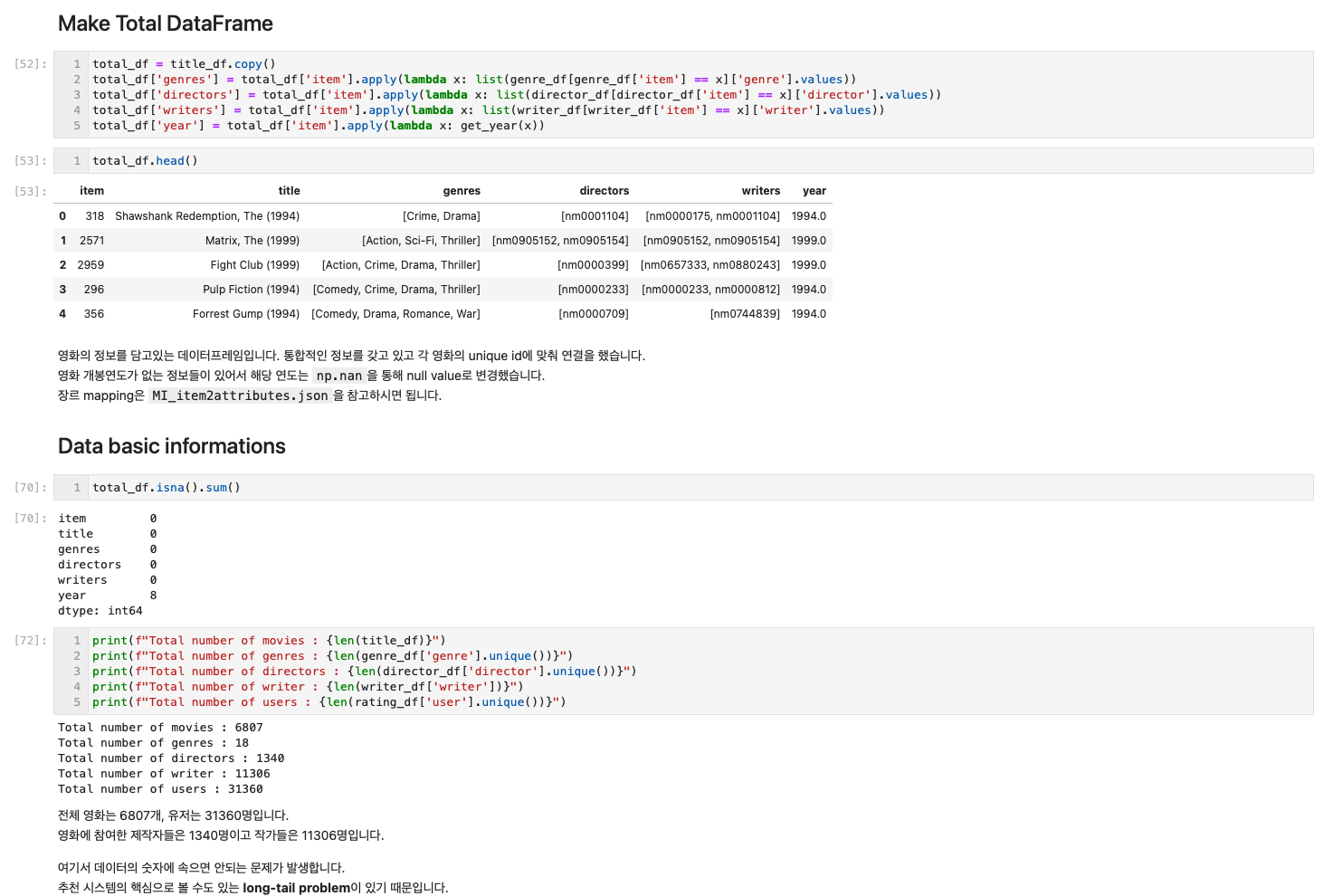
이번에도 저번처럼 대회 데이터 EDA를 진행했습니다. 다른 캠퍼분께서 기본적인 EDA를 제공해주셨으나 좀 더 스토리라인을 잡은 EDA를 작성했기 때문에 이번에도 공유를 진행할 생각입니다.
NGCF Graph 변형 코드
이번 대회에서 Graph Neural Net을 사용할 수도 있을거라 생각했습니다. 그래서 우선 user-items 형태의 text 파일을 생성하는 코드를 작성했습니다.
현재 NGCF 구현 코드도 작성 중이라 구현이 완료되는 대로 깃허브 논문 구현에 업로드도 진행할 예정입니다.
실제 NGCF를 구현한 코드는 기존의 rating matrix -> graph 과정이 없어서 해당 부분도 같이 업로드할 예정입니다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
import os
import pandas as pd
def make_user_item(train=True):
trains = ['u1.base', 'u2.base', 'u3.base', 'u4.base', 'u5.base']
tests = ['u1.test', 'u2.test', 'u3.test', 'u4.test', 'u5.test']
df = pd.DataFrame()
path = '/opt/ml/input/data/lens/'
root = '/opt/ml/input/data/lens/ngcf'
if train:
for train in trains:
tmp = pd.read_csv(os.path.join(path, 'ml-100k', train), sep='\t', encoding='latin-1', header=None)
df = pd.concat([df, tmp], ignore_index=True)
df.columns=['user_id', 'movie_id', 'rating', 'timestamp']
users = df['user_id'].unique()
if 'train.txt' in os.listdir(root): t = 'w'
else: t = 'w+'
with open(os.path.join(root, 'train.txt'), t) as f:
save_txt = ''
for user in users:
save_txt += f'{str(user)} '
items = ' '.join(map(str, df[df['user_id'] == user]['movie_id'].values))
save_txt += items
save_txt += '\n'
f.write(save_txt)
else:
for test in tests:
tmp = pd.read_csv(os.path.join(path, 'ml-100k', test), sep='\t', encoding='latin-1', header=None)
df = pd.concat([df, tmp], ignore_index=True)
df.columns = ['user_id', 'movie_id', 'rating', 'timestamp']
users = df['user_id'].unique()
if 'test.txt' in os.listdir(root): t = 'w'
else: t = 'w+'
with open(os.path.join(root, 'test.txt'), t) as f:
save_txt = ''
for user in users:
save_txt += f'{str(user)} '
items = ' '.join(map(str, df[df['user_id'] == user]['movie_id'].values))
save_txt += items
save_txt += '\n'
f.write(save_txt)
if __name__ == '__main__':
make_user_item(True)
make_user_item(False)
Comments powered by Disqus.