
Final Project : Airflow setting 및 배치 파이프라인 설계
목차
- Airflow setting
- Batch train 파이프라인 설계
Airflow setting
저희 서비스에서 사용하는 추천모델은 크롬 익스텐션을 활용하는 만큼 빠른 반응속도를 보여야 합니다. 따라서 추천 모델들 중 속도가 빠른 편인 VAE 계열의 모델을 사용했습니다. 문제는 VAE 계열의 모델들은 기본적으로 입력을 완선된 형태의 user-item matrix로 사용하므로 신규 유저나 정보의 변화에 대응하기 어렵다는 것입니다. 이를 해결하고자 매시간, 매 2시간마다 주기적으로 배치학습을 진행해서 좋은 성능을 보이는 모델로 새로운 user-item matrix 기반의 학습을 하기로 했습니다.
왜 Airflow 인가?

스케줄링 워크플로 툴들은 다양하게 존재합니다. Luigi, Metaflow, Airflow 등이 있습니다. 그렇다면 왜 Airflow를 선택했을까요? 우선 가장 핵심적인 이유는 Python으로 동작한다는 점입니다. 기본적으로 ML/DL을 활용하는 서비스이다보니 Python 기반의 코드가 많습니다. 이를 고려해서 연동성을 생각하면 Airflow가 좋은 선택지로 보였습니다. 또한 현재 거의 스케줄링 툴의 표준이 된 상황이라 적용해 볼 가치가 있었습니다.
Data 및 BackEnd Architecture
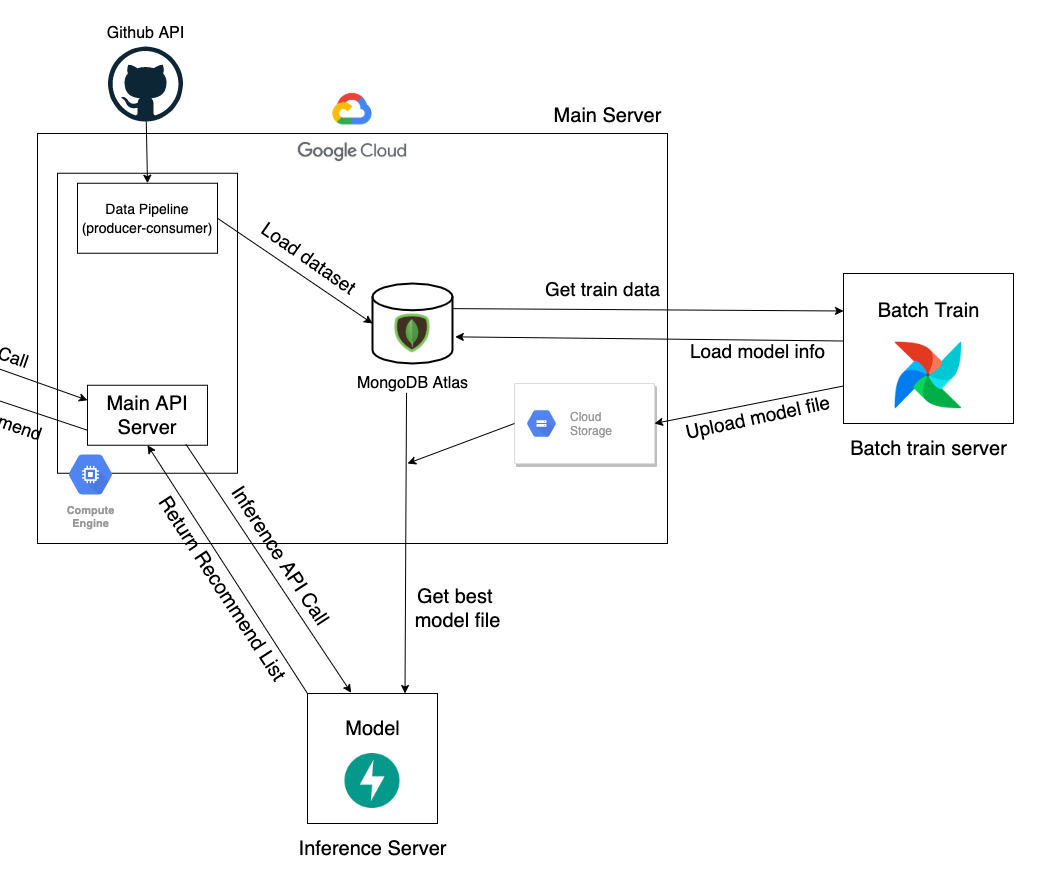
현재 서비스의 백엔드 아키텍처입니다. 전반적인 데이터베이스, 메인 API Server는 GCP를 활용하고 모델 학습 정보를 저장하고자 Cloud storage를 도입했습니다. 관련된 내용은 이전 글을 참고해주세요.
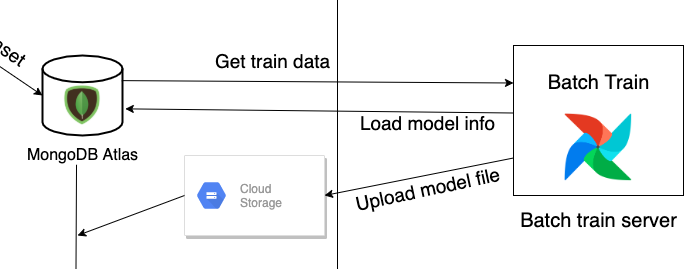
이렇게 배치학습을 하는 부분의 구조는 다음과 같습니다. 기본적으로 RecVAE 코드가 Airflow 서버상에 존재하고 Airflow는 MongoDB Atlas에서 현재 존재하는 repository(item)의 구성을 모두 가져옵니다. 이후 fitering을 거쳐 유의미한 아이템들만 선별하고 RecVAE 학습을 진행합니다.
이렇게 학습이 완료된 모델 정보는 실제 model.pt 파일과 파일이 저장된 cloud storage 정보로 나눠져서 각각 cloud storage와 MongoDB Atlas로 전달됩니다.
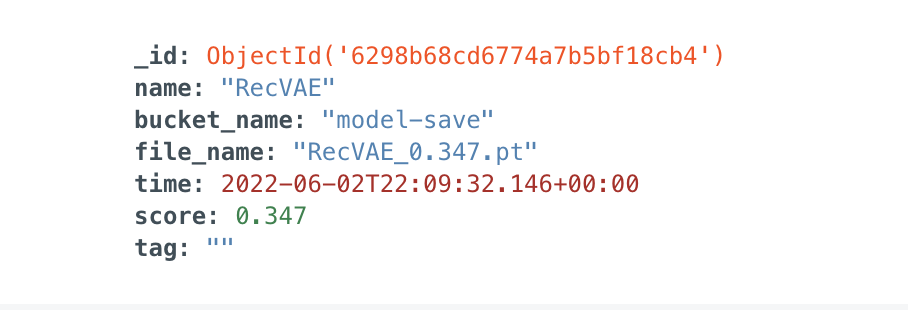
기본적으로 모델 정보를 저장하는 model collection에는 기준 지표가 되는 score와 학습모델, 파일명, 모델이 저장된 버킷명을 저장합니다. 또한 동점 케이스는 최신 모델을 사용하도록 선정했습니다.

실제 cloud storage에는 모델의 정보를 담고 있는 model.pt 파일이 업로드 됩니다. 이 정보들을 활용해서 FastAPI 서버는 주기적으로 모델을 최신, 최고 성능의 모델로 교체합니다.
Batch train 파이프라인 설계

복잡한 구조의 DAG 설계가 필요하지는 않았습니다. 하지만 전처리를 2번 진행해야하는 과정이 있었고 이 과정에서 연속적인 흐름을 진행할 경우 시간 소모의 문제가 있을 수 있었습니다.
따라서 DB에서 repository 정보를 불러와서 user-item matrix를 형성해서 저장하는 preprocessing_base_data task, 실제 RecVAE에 들어가게 되는 데이터로 전처리하는 preprocessing_vae로 구별했습니다.
이후 모델을 학습하고 부산물로 나오는 model.pt 파일에 대한 정보 파싱을 진행했습니다. 모델 정보를 저장하는 규약으로는 학습모델종류_점수.pt로 지정했으므로 이에 맞춰 model 이름과 score로 파싱하여 이후 모델 정보를 저장하기 위해 xcom으로 data context를 전달합니다.
파이프라인 설계 과정의 이슈와 해결과정
Timezone 이슈
Airflow는 일정 시간을 기준으로 반복을 하는 스케줄링 툴입니다. 따라서 어떤 기준 시각이 존재해야하는데, 일반적으로 UTC기준으로 시간을 산정합니다. 따라서 구동하는 서버의 timezone 설정이 되어 있지 않는다면 일단 우선적으로 timezone 설정 이슈를 만납니다.
우분투 기준, 이를 해결하려면 tzselect를 활용해 해당하는 시간대로 설정을 해주시면 원활하게 airflow webserver가 구동됩니다.
DAG의 timezone을 KST로 세팅하기
역시나 airflow의 start_date도 UTC를 기준으로 설정됩니다. 이를 해결하고자 다음과 같은 방식으로 작성하면 KST 기준으로 코드를 작성하고 Airflow는 UTC 기반으로 해석합니다.
1
2
3
4
5
6
7
8
9
10
11
12
import pendulum
from airflow import DAG
kst = pendulum.timezone("Asia/Seoul")
dag = DAG(
dag_id="train_batch",
description="RecVAE batch train dag",
start_date=datetime(2022, 6, 2, 22, 30, tzinfo=kst),
schedule_interval="@hourly",
tags=["recsys", "recvae"]
)
Comments powered by Disqus.