
Neural Graph Collaborative Filtering (2019)
논문 소개
 출처 : ACM2019 Neural Graph Collaborative Filtering
출처 : ACM2019 Neural Graph Collaborative Filtering
NGCF는 GNN의 최초 등장 논문은 아닙니다. 이전에 이미 GNN에 대한 개념이 존재했었고 어느정도 연구도 있었습니다. 하지만 추천 시스템에 적용하여 효과적인 성능을 보여줬으며 이후 GNN을 활용한 추천 시스템 연구에 도화선 역할을 하게 되었습니다.
이후 LightGCN 등 여러가지 GNN을 활용한 추천 시스템 연구들이 등장하였습니다. 이번 포스팅에서는 지난 AlexNet과는 다르게 핵심적인 NGCF이론 위주로 설명하겠습니다.
지난번에 알렉스넷 해석처럼 리뷰했다가 반나절 걸려서 그렇게는 못 하겠습니다…
Abstract
- 최신 추천 시스템 연구는 item과 유저의 벡터 표현 (임베딩)을 학습하는 방식을 활용함
- MF나 딥러닝이 적용된 방식은 ID나 attribute 같은 유저(아이템)의 속성을 활용해서 임베딩을 했음
- 이런 임베딩 방식은 유저-아이템 상호작용인 collaborative signal을 임베딩 과정에서 인코딩 하지 않는다는 문제가 존재함
- 이 논문에서는 이분 그래프 구조의 user-item 상호작용을 임베딩 과정에 포함하는 방법을 제시함
- user-item graph 구조를 임베딩 전파를 통해 전달하는 NGCF를 개발
- 이때, user-item graph는 high-order connectivity를 사용해서 표현하고 전달함
Introduction
문제제기
- 논문은 기존 CF의 연산 방식의 핵심을 다음과 같이 정의
- 유저-아이템 임베딩 : latent factor
- 상호작용의 모델링 : $P^\intercal Q$ (dot product를 통한 선형연산)
- 기존 CF에는 상호작용 표현의 한계가 존재함
- 이런 한계가 존재하는 이유는 기존 CF (MF, NCF)의 연산 순서때문
- $\mathbf{e}_u = P$, $\mathbf{e}_i = Q$ 로 유저와 아이템을 임베딩하고 두 임베딩 matrix의 inner product인 $P^\intercal Q$ 순서로 연산
- 이 과정을 보면 각각 임베딩 후 상호작용을 연산하므로 유저-아이템의 상호작용 자체를 전달하지 못하는 한계가 발생함 (latent 형태로 연산하므로 정보의 누락 발생)
- 이런 기존 CF의 문제를 interaction function ($P^\intercal Q$)에만 의존하므로 sub-optimal(누락된 부분 정보)한 임베딩을 사용한다고 제시
문제 해결 아이디어
 Neural Graph Collaborative Filtering
Neural Graph Collaborative Filtering
- 논문에서 계속 언급하는 Collaborative Signal은 유저-아이템 상호작용(소비관계)을 의미
- 좌측은 기존 CF방식의 상호작용 표현방식인데, 이 방법은 유저와 아이템 수가 늘어날수록 연결되지 않은 다른 item의 간접적인 상호작용 표현에 한계가 존재함
- GNN을 활용하여 유저-아이템 상호작용은 임베딩 부분에서 처리하는 방식을 제시
- High-order Connectivity를 사용하면 직/간접적 상호작용을 표시할 수 있음
- GNN을 사용하면 user-item-user 연결관계로 따로 유사도를 계산하지 않아도 user간의 연결관계로 유사도를 파악할 수 있음
- Graph로 관계를 표현하면 $u_1$에 대한 아이템의 추천 강도도 계산할 수 있음
- $i_4$는 $i_4 \rightarrow u_2 \rightarrow i_2 \rightarrow u_1$ path와 $i_4 \rightarrow u_3 \rightarrow i_3 \rightarrow u_1$ path, 총 2가지 경로로 $u_1$에게 전달됨
- $i_5$가 $u_1$에게 전달되는 경로는 1개밖에 없으므로 추천 강도는 $i_4 > i_5$가 됨
Methodology
NGCF 구조
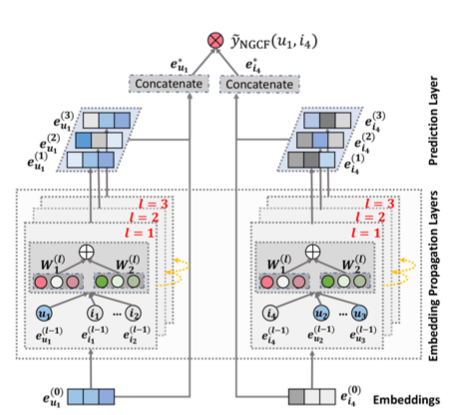 Neural Graph Collaborative Filtering
Neural Graph Collaborative Filtering
- NGCF 모델 구조는 크게 3개의 레이어로 구성됨
- Embedding Layer
- one-hot encoding의 유저-아이템 초기 임베딩을 k 차원 임베딩으로 변환
- Embedding Propagation Layer
- NGCF에서 가장 중요한 레이어
- 유저-아이템 연결관계를 갖는 high-order connectivity를 학습하는 레이어
- Prediction Layer
- 아이템, 유저 각 전파 레이어에서 전달된 임베딩을 concat해서 결과 score를 연산
- Embedding Layer
Embedding Layer
\[\mathbf{E} = [ \; \underbrace{\mathbf{e}_{u_1}, \cdots, \mathbf{e}_{u_N}}_{\text{users embeddings}} , \underbrace{\mathbf{e}_{i_1}, \cdots, \mathbf{e}_{i_M}}_{\text{item embeddings}} \;]\]- embedding을 생성하는 레이어
- 임베딩 방식은 기존의 CF방식 (MF, Neural CF)과 동일하지만 기존 CF는 이걸 바로 interaction function에 입력함
- NGCF는 GNN에 임베딩을 전파하여 refine
- Collaborative Signal(상호작용)을 직접적으로 레이어에 전달하는 과정
Embedding Propagation Layer
First-order Propagation
- collaborative signal을 전달할 message를 구성하고 결합하는 단계
- Message Construction 단계는 유저-아이템간의 affinity(밀접관계)를 표현하는 message를 형성함
- $\mathbf{e}_i \odot \mathbf{e}_u$에서 $\odot$은 element-wise 연산인데, element-wise 연산 특성상 두 벡터 연결관계와 강도를 잘 표현함 (interaction term)
- $p_{ui}$는 연결 item이 과도하게 많을 경우를 방지하는 decay factor
- 주변 이웃 노드 수($\left\vert \mathcal{N} \right\vert$)로 나눠서 normalize함
- Message Aggregation 단계는 $u$의 이웃 노드들에서 전파된 message를 결합하여 해당 유저의 1단(1 layer) 임베딩을 형성함
- $\text{LeakyReLU}$를 사용한 이유는 collaborative signal에서 긍정과 부정 정보를 모두 인코딩해야 하기 때문
- 정보의 손실을 방지하고자 self-connection term ($\mathbf{m}_{u \leftarrow u}$)를 추가함
- 이걸 추가하는 이유는 GCN에서 그래프를 표현하는 방식때문임
왜 self-connection term이 필요한가?
self-connection항이 들어가는 이유는 본 논문에서 제시하는 그래프 표현 방식때문입니다. 일반적으로 그래프를 표현할 때 앞서 말한 것처럼 인접행렬의 형태를 사용하려고 합니다. 아래 그래프로 예를 들어봅시다.
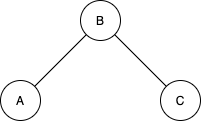
문제는 단순히 인접행렬만으로 표현하면 특정 노드에 인접한 노드의 개수(차수)를 $O(1)$시간에 알기에 무리가 있습니다. 그래서 그래프 표현에 Degree matrix를 추가해서 표현합니다. 문제는 두 행렬이 따로 존재하면 여러가지 의미로 효율성이 떨어집니다. 그래서 이 두 행렬의 정보가 서로 공존하게 만드는 Laplacian Matrix (라플라시안 행렬) 을 만듭니다. (wikipedia : laplacian matrix)
\[\mathcal{L} = \text{Degree matrix} - \text{Adjacency matrix} = \begin{bmatrix} 1 & -1 & 0 \\ -1 & 2 & -1 \\ 0 & -1 & 1 \end{bmatrix}\]이렇게 만들어진 라플라시안 행렬은 일반적으로 대각성분이 모두 1인 Normalized Laplacian Matrix로 변환합니다.
\[\mathcal{L}^{\text{norm}} = \mathbf{D}^{-\frac{1}{2}}\mathcal{L}\mathbf{D}^{-\frac{1}{2}} = \begin{bmatrix} 1 & -\frac{1}{\sqrt{2}} & 0 \\ -\frac{1}{\sqrt{2}} & 1 & -\frac{1}{\sqrt{2}} \\ 0 & -\frac{1}{\sqrt{2}} & 1 \end{bmatrix}\]그래서 원래는 대각성분이 모두 1로 존재하기 때문에 self-connection이 필요하지 않습니다. (아마도요….)
근데 본 논문에서는 모델의 계산 편의성을 위해 대각원소를 모두 0으로 처리한 matrix로 정의했습니다. 그래서 self-connection term이 필요합니다.
여기서 $\mathbf{R}$은 user-item intercation matrix 입니다.
High-order Propagation
 Neural Graph Collaborative Filtering
Neural Graph Collaborative Filtering
- 1개의 레이어는 1개의 order를 처리함
- 따라서 $l$개의 embedding propagation layer를 쌓으면 유저노드는 $l$ 거리만큼 떨어진 이웃의 메시지를 사용할 수 있음
- 이런 이웃들을 $l$-hop neighbor라고 함
- 수식적으로 $l$ layer에서 생성된 message는 아래와 같이 나타냄
- 최종적으로 위의 식의 계산은 아래 수식을 통해 구현되어 실제 처리됨
- 솔직히 굉장히 뭐가 많이 튀어나와서 정신이 없을텐데 여기서 살짝 첨언을 하자면 도대체 저 $\mathcal{L}$은 어디서 갑자기 튀어 나온건가..?하면 $\mathbf{e}^{(l)}_u$ 식을 자세히 보면 내부에 크게 2개의 항으로 나뉜다.
- $\mathbf{m}^{(l)}_{u \leftarrow u}$ : self-connection
- 이 항을 계산할 때는 자기 자신 노드에 대한 연산만 하기 때문에 굳이 user-item interaction을 생각할 필요가 없다. 그래서 그냥 identity matrix를 곱한다.
- $\mathbf{m}^{(l)}_{u\leftarrow u}$ : user-item interaction
- 문제는 이 항에서는 user-item interaction을 고려해야한다. 따라서 앞에서 user-item 관계를 담고 있는 그래프 정보인 $\mathcal{L}$을 곱해주는 것이다.
- 이해가 잘 안되면 $\mathbf{E}^{(l)}$랑 $\mathbf{e}^{(l)}_u$를 그냥 다 전개해서 나란히 두고 비교해보면 어느정도 느낌이 날 것이다.
별로 안 복잡하다.
- $\mathbf{m}^{(l)}_{u \leftarrow u}$ : self-connection
Prediction Layer
\[\begin{aligned} \mathbf{e}^{*}_u = \mathbf{e}^{(0)}_u \Vert \cdots \Vert \mathbf{e}^{(L)}_u , \quad \mathbf{e}^{*}_i = \mathbf{e}^{(0)}_i \Vert \cdots \Vert \mathbf{e}^{(L)}_i \\\\ \hat{y}_\text{NGCF}(u, i) = {\mathbf{e}^{*}_u}^\intercal\mathbf{e}^{*}_i \qquad\quad\quad \end{aligned}\]- L번째 layer까지 임베딩 벡터를 형성했으면 user, item 별로 각각 concatenate하여 최종 임베딩 벡터를 생성함
- 그리고 각 임베딩 벡터를 내적해서 최종 선호도를 계산
Optimization
\[\textit{Loss} = \sum_{(u, i, j)\in \mathcal{O}} -\ln\sigma(\hat{y}_{ui} - \hat{y}_{uj}) + \lambda \lVert \Theta \rVert^2_2 , \quad \Theta = \{ \mathbf{E}, \{ \mathbf{W}^{(l)_1}, \mathbf{W}^{(l)}_2 \}^L_{l=1} \}\]- loss function은 이전에 BPR에서 사용된 BPR loss를 사용
- BPR loss의 수식구조에 따라 $\mathcal{O} = { (u, i, j) \mid (u, i) \in \mathcal{R}^+, (u, j) \in \mathcal{R}^- }$이 되는데, $\mathcal{R}^+$는 관측한 상호관계이고 $\mathcal{R}^-$는 비관측 상호관계를 의미
- activation function은 sigmoid
- $\lambda$는 $L_2$ regularization으로 오버피팅 방지
- optimizer는 Mini-batch Adam 사용
Dropout
- Message Dropout
- layer에서 생성된 message 중 일부를 dropout
- user와 item의 단일 연결관계의 존재 여부에 더 강한 robustness를 임베딩해주는 효과
- Node Dropout
- 특정 노드를 임의로 차단하고 모든 출력 message를 차단
- $l$번째 전파 레이어에서 라플라시안 행렬의 노드들 중 임부를 임의로 drop
- 특정 user-item 관계에 대한 영향을 줄여줌
Conclusion
- Embedding propagation layer가 많을수록 성능이 좋아짐
- 다만 너무 많으면 오버피팅 발생하므로 3~4개 층이 가장 최적 성능
- Embedding propagation으로 representation을 좀 더 정확하게 해줬기 때문에 수렴속도와 recall에서 좋은 효과를 보임
- 또한 유저-아이템 임베딩 공간이 더 명확하게 구분됨
Comments powered by Disqus.