
Deep Dive Python : List
리스트의 특징
리스트는 파이썬을 만나게 된 이후 가장 많이 사용하는 자료구조라고 생각한다. 파이썬에서는 C++이나 Java와 같은 배열 자료구조를 제공하지 않고 그 역할을 리스트가 대신한다. 물론 리스트라는 자료구조는 단순히 배열에 대입해서 보기에는 상당히 복잡한 형태로 구성된 자료구조이다.
같이 보면 좋은 저장소는 CPython : List Object이다.
리스트는 객체 참조자들의 저장소
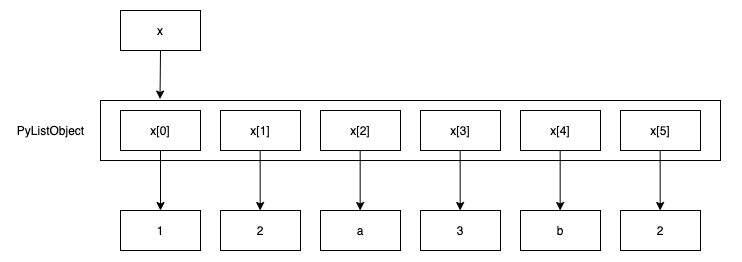
리스트의 활용성이 높은 것은 다양한 자료형 객체의 저장 컨테이너라는 것과 유동적인 데이터 변경이라는 특징때문이다. 여기서 중요한 것은 객체의 저장 컨테이너라는 점이다. 리스트에 저장되는 모든 요소는 객체를 참조하는 역할을 하기 때문에 컨테이너라고 부른다.
리스트와 변수

1
2
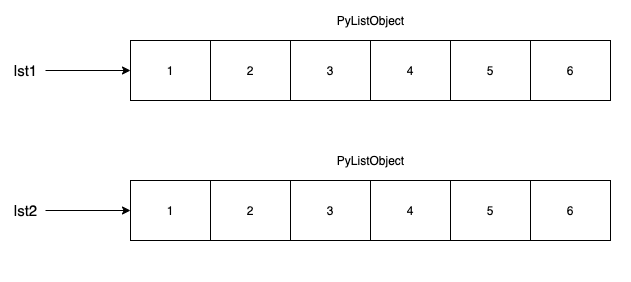
lst1 = [1, 2, 3, 4, 5]
lst2 = lst1
앞서 다뤄본 변수에 대한 대입연산은 리스트도 동일하게 이뤄진다. 그렇기 때문에 리스트를 다른 리스트에 대입하는 연산을 수행하는 경우 동일 리스트를 복사하는 것이 아닌 서로 같은 리스트를 포인팅하는 것이 된다. 따라서 다른 값을 변경해도 마치 C++의 포인터를 통한 변경처럼 다른 변수에도 영향을 준다.
1
2
lst1 = [1, 2, 3, 4, 5]
lst2 = [1, 2, 3, 4, 5]
하지만 만약 동일한 리스트 코드를 각각 생성하면 다른 객체를 참조한다. 여기까지 다룬 내용들에서도 아주 중요한 것들이 많다. 키워드 문장들을 고르면 다음과 같다.
- 리스트의 각 요소는 파이썬 객체들을 참조한다.
- 리스트는 대입연산을 사용하면 동일 객체를 포인팅한다.
- 리스트는 각각 생성하면 다른 객체를 참조한다.
이 3가지 핵심 특성은 뒤에서 설명할 리스트 복사의 개념에서 아주 중요한 것들이다. 일단 이렇게 알아두자.
리스트의 내부 구조
리스트의 내부
이전에 자료구조에서 연결 리스트 (Linked List) 를 배워본 기억이 있을 것이다. 보통 링크드 리스트와 함께 비교하는 자료구조는 배열이 있다. 배열의 장점은 여러가지가 있지만 대표적인 것은 Random Access가 가능하다는 것과 연속적인 메모리 할당으로 빠른 접근 속도이다. 하지만 그 단점인 유동적인 크기의 변경이 불가능하다는 문제가 있다. 그래서 배열의 장점을 일부 포기하고 확장성을 갖는 자료구조가 바로 링크드 리스트이다. 링크드 리스트의 문제점 중 대표적인 것은 불연속적인 메모리 할당이라는 점이 있다.
파이썬의 리스트의 이름을 처음 들으면 링크드 리스트 구조라고 생각할 수 있다. 실제로 리스트의 특징을 갖고 있으며 배열의 특징도 갖고 있어서 단순히 Random Access를 지원하는 링크드 리스트라 생각할 수 있다. 하지만 파이썬의 리스트는 연속된 메모리에 요소를 저장하는 배열로 동작한다. 그리고 리스트는 확장에 대비해서 여유있게 메모리를 미리 확보하는 특징이 있다.
대입과 누적 대입
리스트를 확장하는 방법으로는 append, extend, x = x + [1] , x += [1] 과 같은 방식이 있다. append와 extend는 기본적으로 기존 리스트의 참조를 확장하는 방식이다. 하지만 누적대입(+=)과 대입(=)은 파이썬 내부 동작이 다르게 동작한다. 이 점을 고려하면 좀 더 빠른 연산을 고려할 수 있다.
1
2
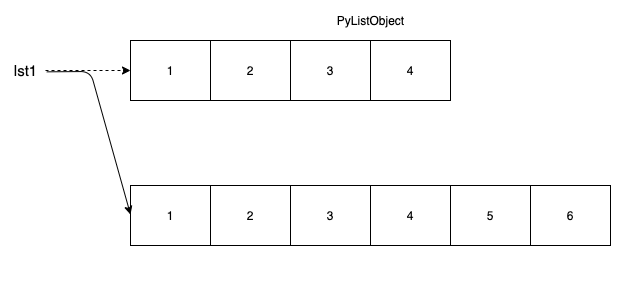
x = [1, 2, 3, 4]
x = x + [5, 6]
기본적으로 대입을 사용하는 리스트 확장은 기존의 파이썬의 대입의 특징을 갖는다. 즉, 새롭게 객체를 만들고 변수는 새로운 객체를 참조한다. 결국 새로운 객체를 생성하는 추가적인 시간이 발생한다.
1
2
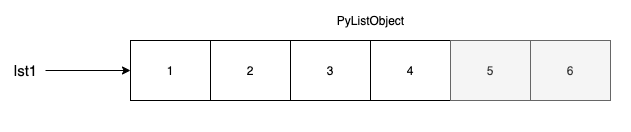
x = [1, 2, 3, 4]
x += [5, 6]
하지만 누적대입(+=)은 기존의 리스트에 확장이 되는 방식으로 연산한다. 따라서 기존 리스트 객체가 변화하지 않는다.
리스트 복사
리스트를 사용하다보면 가장 많이 마주치는 문제가 바로 리스트 복사 이슈이다. 특히 2차원 배열 형태의 리스트를 사용하면 단순 list.copy()를 사용하는 것에 문제가 발생하기도 한다. 그래서 좀 더 자세히 리스트 복사와 관련된 내용을 알아보고, 각 방법에 따른 리스트의 구조 변화를 알아보자.
리스트의 단순 복사
1
2
3
4
a = [1, 2, 3, 4]
b = a
b[0] = 1
바로 전 포스팅에서 다뤘던 예제이다. 이 경우 이제는 익숙하겠지만 b는 a 리스트 객체를 참조하기 때문에 a에도 영향을 준다. 리스트의 원본을 유지하면서 변화하는 조작은 프로그래밍에서 상당히 많이 사용되는 기법이다. 보통 변화를 주고 조건 확인 후 문제가 발생하면 원본으로 복구하고, 문제가 없다면 원본에 덮어씌우는 방식에 많이 쓴다. 이런 경우 파이썬은 문제가 될 수 있는 부분들이 있다. 문제들을 해결하고자 파이썬은 copy와 같은 메소드를 쓴다.
1
2
3
4
a = [1, 2, 3, 4]
b = a.copy()
b[0] = 1
가장 간단한 방법은 list.copy()를 사용해서 리스트 복사본을 생성하는 것이다. 이렇게 되면 리스트의 동일한 객체를 복사본을 새롭게 생성하여 리턴한다. 즉 새로운 id를 부여받은 객체를 참조한다.
1
2
3
4
a = [1, 2, 3, 4]
b = list(a)
b[0] = 1
또 다른 방법은 list 함수를 사용해서 새로운 리스트를 생성하여 반환하는 것이다. 잠깐 위로 올라가보면…
리스트의 주요 특징 중 각각 생성한 리스트는 새로운 객체들을 참조한다는 것이 있었다. 결국 이 방식은 완전히 새로운 리스트를 생성하는 것과 동일하기 때문에 복사와 같은 동작을 한다.
1
2
3
4
a = [1, 2, 3, 4]
b = a[:]
b[0] = 1
마지막으로는 리스트 슬라이스를 모든 인덱스로 하면 새로운 리스트가 생성된다. 두 리스트에 대해 객체 비교를 하면 서로 다르게 나타난다. (하지만 튜플은 같다고 나타난다. 이는 이후 설명할 튜플과 딕셔너리에서 다루겠다.)
얕은 복사, 깊은 복사
이제 복사를 알았으니 자유롭게 리스트를 변경할 수 있다고 생각하겠지만… 절반만 맞는 말이다. 파이썬의 변수가 객체를 참조한다는 점에서 참 골치가 아픈 일이 발생한다. 아래 코드의 출력 결과는 과연 뭘까?
1
2
3
4
5
6
a = [[1, 2], [3, 4]]
b = list(a)
b[0][1] = 1
print(a)
위에서 말한 대로라면 [[1, 2], [3, 4]]가 나와야 하지만, [[1, 1], [3, 4]]가 된다.
이게 이렇게 되는 이유는 파이썬의 변수는 객체를 참조한다는 것과 리스트는 객체 참조자들의 컨테이너라는 점때문에 발생한다. 위에서 말한 리스트 복사는 변수가 리스트를 참조만 하는 것을 막기 위해 동일한 값을 참조하는 참조자들을 저장하는 리스트를 새롭게 만드는 것이다. 이게 참 머리가 아파지는 부분이다. 이해를 돕고자 그림으로 어떻게 된 상태인지 보여주겠다.
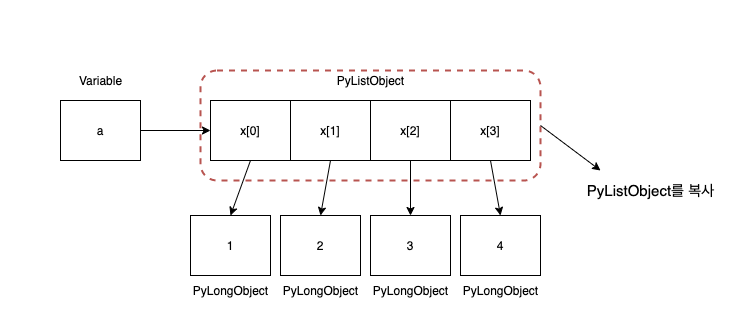
간단하게 말하면 우리가 복사하는 리스트는 PyListObject 객체 자체를 복사한다. 결국 참조자들은 모두 동일하게 유지된다. 그래서 여기서는 매우 특이한 특징이 나타나는데, 앞서 다룬 포스팅에서 -5 ~ 256까지는 동일 숫자 객체를 무조건 지시하지만 범위 밖의 숫자 객체를 매번 새롭게 생성된다고 했다. 하지만 만약 리스트 안에 있는 257은 리스트를 복제하면 다른 객체가 될까?
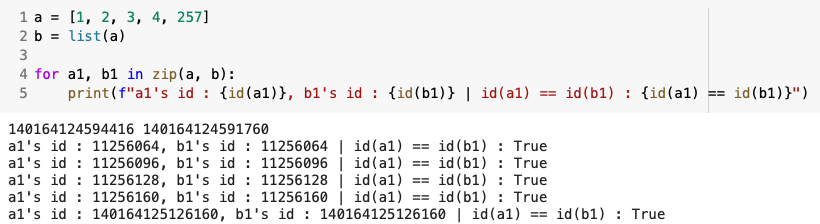
정답을 말하면 “아니다” 이다. 이유는 앞서 말한 이유인데, 결국 참조자를 복사하는 것이고 참조자들은 동일 객체를 가리키고 있다. 결국 이런 이유 때문에 앞에 나온 2차원 배열의 문제가 왜 그렇게 나오는지 알 수 있다. 2차원 배열의 구조를 디테일하게 나타내면 아래와 같다.

결국 바깥 리스트의 참조자를 복사하는 것은 성공했지만 그 참조자가 가리키는 내부의 리스트는 복사하지 못했기 때문에 발생하는 문제였다. 이 문제를 해결하려면 내부의 리스트 참조자까지 모두 복사를 해야 한다.
이를 위해 copy 라이브러리의 deepcopy 메소드를 사용해야 한다.
1
2
3
4
5
6
import copy
a = [[1, 2], [3, 4]]
b = copy.deepcopy(a)
b[0][1] = 1
이렇게 복사를 하면 리스트의 내부까지 복사한 새로운 객체를 만들어서 변수에 할당한다. 따라서 내부의 리스트의 id도 새로 생성한다.
deepcopy, copy에 따른 id 비교

우선 copy로 복사한 경우 얕은 복사가 되며 내부에서 각 리스트의 id를 보면 동일하게 유지되는 것을 볼 수 있다. 이런 구조에서 내부 리스트를 변경하면 그냥 리스트 객체에 참조를 새로 대입한 것과 동일한 것이다.

하지만 deepcopy를 하면 list의 id가 서로 다른 것을 알 수 있다. 이렇게 복사를 하기 때문에 특별한 문제없이 리스트의 변화를 줄 수 있다.
리스트는 파이썬에서 가장 많이 다루는 자료형이지만 생각보다 그 내부를 깊이있게 알고 사용하는 사람은 많지 않다. 이는 딕셔너리, 튜플도 마찬가지인데 리스트는 독립적으로 다룰 필요가 있을만큼 내부구조가 복잡하다. 그래서 이번 글에서는 리스트만 따로 분석을 했다. 다음 포스팀에서는 딕셔너리와 튜플을 알아볼 예정이다. 필요에 따라서는 딕셔너리는 따로 분석할 수도 있다.
Comments powered by Disqus.