
PyTorch : 모델 불러오기
Introduction
- 최근 추세는 pre-trained 모델을 데이터에 맞추는 fine-tuning을 진행한다.
- 또한 모델의 학습 결과를 공유하고 저장할 필요가 있다.
모델 저장 및 불러오기
1. model.save
- 학습의 결과를 저장하기 위한 함수이다.
- 모델과 파라미터를 저장한다.
- Earky Stopping이나 중간중간 모델의 최적 결과를 위해 최선의 결과모델을 선택한다.
- 모델을 외부로 공유해서 학습의 재연성을 향상할 수 있다.
1
2
3
4
5
6
7
8
9
10
import torch
import os
torch.save(model.state_dict(), os.path.join(MODEL_PATH, "model.pt"))
new_model = NewModel()
new_model.load_state_dict(torch.load(os.path.join(MODEL_PATH, "model.pt")))
torch.save(model, os.path.join(MODEL_PATH, "model.pt"))
model = torch.load(os.path.join(MODEL_PATH, "model.pt"))
state_dict: 모델의 파라미터를 표시해주는 역할- 모델 파라미터를 불러와서 모델에 저장하는 역할
model.pt: 과거에는 pth의 형식으로 저장을 많이 했으나 요즘은 pt 형식으로 저장한다.- 같은 모델에서 파라미터만 load해서 사용하는 경우가 많다.
2. checkpoints
- 학습 중간에 결과를 저장해서 최선의 결과를 선택한다.
- earlystopping과 같은 기법으로 학습 결과를 저장한다.
- epoch, loss외 metric을 함께 저장해서 확인하는 경우가 많다.
1
2
3
4
5
6
7
8
9
10
11
12
13
torch.save({
'epoch': e,
'model_state_dict': model.state_dict(),
'optimizer_state_dict': optimizer.state_dict(),
'loss': epoch_loss},
f"saved/model_name.pt"
)
checkpoint = torch.load(PATH)
model.load_state_dict(checkpoint['model_sate_dict'])
optimizer.load_state_dict(checkpoint['optimizer_state_dict'])
epoch = checkpoint['epoch']
loss = checkpoint['loss']
Pre-trained model, Transfer learning
- 최근 CV와 NLP 분야에서는 Bert, ImageNet과 같은 Pre-trained model을 사용하는 추세이다.
- 이 모델들은 다량의 데이터로 학습을 시킨 모델들이다.
- pre-trained model에 목적을 위한 데이터를 fine-tuning을 하는 방식을 많이 사용한다.
- backbone architecture가 잘 학습된 모델에서 일부만 재학습하는 방식을 수행한다.
- CV는
TrochVision을 사용하고 NLP는 HuggingFace가 표준이다.- 나도 Bert때문에 huggingface에 들어가본 기억이 있다.
Frezzing
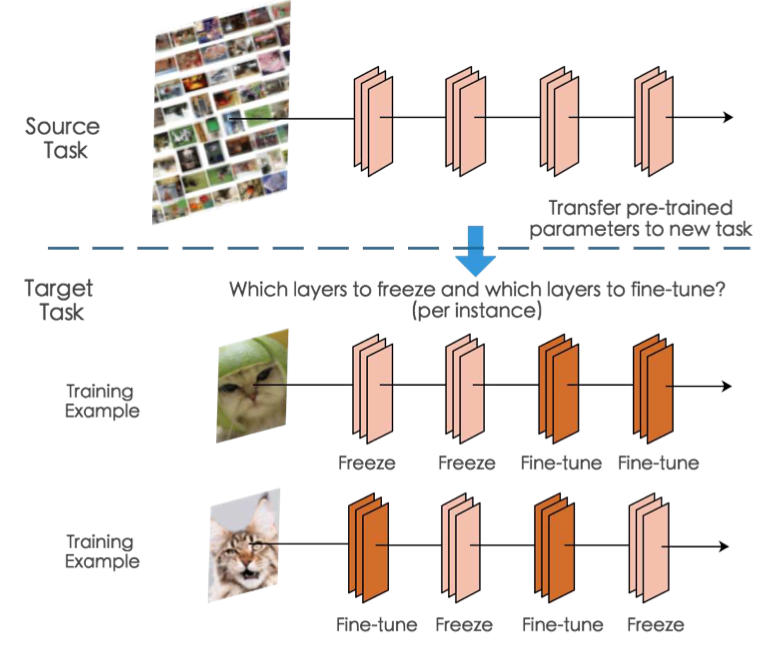 사진출처 : SpotTune: Transfer Learnong through Adaptive Fine-tuning
사진출처 : SpotTune: Transfer Learnong through Adaptive Fine-tuning
- pretrained model 활용시 다른 task를 학습시키기 때문에 일부의 레이어를 고정시키고 남은 레이어만 학습을 진행한다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
import torchvision.models as models
import torch
import torch.nn as nn
class NewNN(nn.Module):
def __init__(self):
super(NewNN, self).__init__()
self.vgg19 = models.vgg19(pretrained=True) # pre-trained load
self.fc = nn.Linear(1000, 1) # linear layer 추가
def forward(self, x):
x = self.vgg19(x)
return self.fc(x)
model = NewNN()
for param in model.parameters():
param.requires_grad = False
for param in model.fc.parameters():
param.requires_grad = True
torchvision의vgg19에 새로운 linear layer를 추가하는 코드이다.- 하단부에 parameter를 처리하는 부분에서 모든 레이어를 일단
require_grad를False로 하고 linear layer인fc의 파라미터의require_grad를True`로 바꾼다.
Comments powered by Disqus.