
Product Serving : MLOps 개론
모델 개발 프로세스
Research VS Production
 모델 개발 : Research
모델 개발 : Research
- 모델 개발의 연구분야는 일반적으로 위 프로세스를 수행
- 고정된 데이터를 사용하는 학습
- 학습이 어느정도 진행되면 서비스를 배포하는 단계로 넘어감
 모델 개발 : Production
모델 개발 : Production
- 배포된 모델의 결과가 이상한 경우에는 적절한 대응이 필요함
- Input data가 이상한 경우
- 실제 서비스는 outlier를 제외하기 어려울 수도 있음 (outlier 여부 판단 어려움)
- 모델의 성능이 계속해서 변화함
- 비정형 데이터는 정확한 성능 지표를 얻어내기 어려움
- 새로 배포한 모델이 더 안 좋은 경우
- Research와 production의 성능에서 차이가 발생할 수 있음
- 이전 모델을 다시 활용하고 재학습을 할 필요가 있음
- 이런 여러가지 문제가 발생하는 것을 처리할 때, 자동화된 과정이 필요함
MLOps
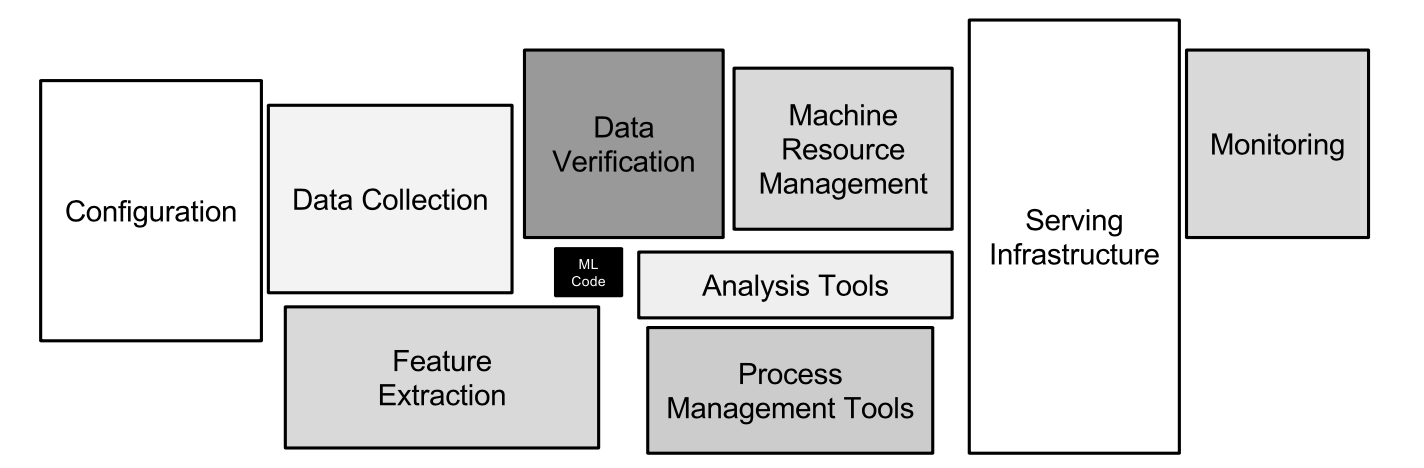 NIPS 2015: Hidden Technical Debt in Machine Learning Systems
NIPS 2015: Hidden Technical Debt in Machine Learning Systems
- 실제 ML 코드는 전체 머신러닝 프로덕션 과정에서 극히 일부만 차지함
- 서비스에 수행되는 과정을 자동화 한 것을 MLOps라고 함
- MLOps = ML(Machine Learning) + Ops(Operations)
- 반복적인 필요 업무를 자동화하는 것
- ML engineering + Data engineering + Cloud + Infra
- 핵심적인 문제와 반복적인 작업을 최소화하고 모델링에 집중할 수 있게 인프라를 구축함
- 추가적으로 현실의 risk에서 잘 버틸 수 있어야 함
- MLOps의 목표는 빠른 시간 내에 가장 적은 위험을 부담하여 Production까지 기술적 마찰을 최소화하는 것
| Research ML | Production ML | |
|---|---|---|
| 데이터 | 고정(static) | 계속 변함(Dynamic-Shifting) |
| 중요 요소 | 모델 성능(Accuracy, RMSE…) | 모델 성능, 빠른 inference, 해석 가능성 |
| 도전 과제 | 더 좋은 성능을 내는 모델(SOTA), 새로운 구조의 모델 | 안정적 |
| 학습 | (데이터 고정)모델 구조, 파라미터 기반 재학습 | 시간의 흐름에 따라 데이터가 변경되어 재학습 |
| 목적 | 논문 출판 | 서비스에서 문제 해결 |
| 표현 | Offline | Online |
MLOps Component
- 기본적인 요소로는 Data, Model, Feature
- 모든 요소가 항상 존재할 필요는 없음
- 필요에 따라 하나씩 추가적으로 구축하는 것이 좋음
Server/GPU Infra
- 배포과정에서 어떤 환경에 배포가 이뤄질 지가 필요함
- 예상 트랙픽, CPU, Memory 성능, 스케일 변경, Local Server, Cloud
- 최근에는 클라우드 서버 위에 올려놓고 사용하는 경우가 많음
- 클라우드 : AWS, GCP, Azure 등
- On promise : 회사나 대학원 전산실에 서버를 직접 설치 (NVIDIA DGX)
- Local GPU와 클라우드 GPU를 잘 구분해서 처리할 필요가 있음
Serving
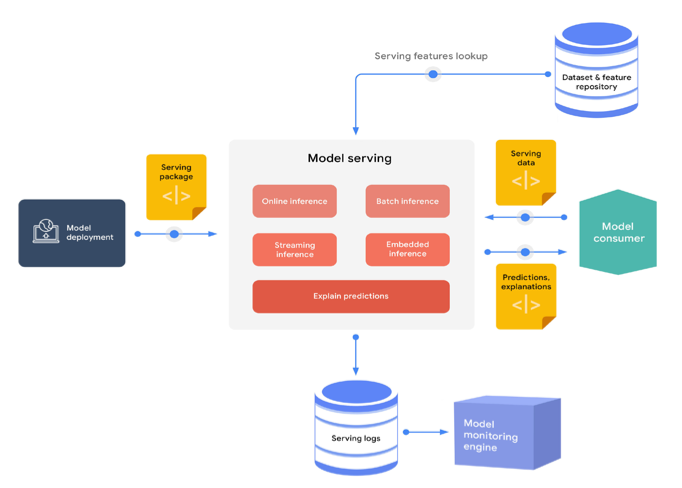
- Production 과정에서 데이터를 전달할 필요가 있음
- 일반적으로 Batch Serving과 Online Serving, 2가지로 구분됨
- Batch Serving
- Model의 prediction 처리를 많은 양의 데이터로 처리하는 것
- 많은 데이터를 일정 주기로 모델에 전달하여 결과를 예측
- 실시간 예측이 필요한 경우 무리가 있음
- Online Serving
- 데이터를 들어오는 그 즉시 실시간으로 처리해서 예측
- 병목현상, 확장 가능성을 모두 고려해야함
- 최근 cortex와 tensorflow serving의 사용추세가 높고 BentoML도 사용이 많은 편
Experiment, Model Management
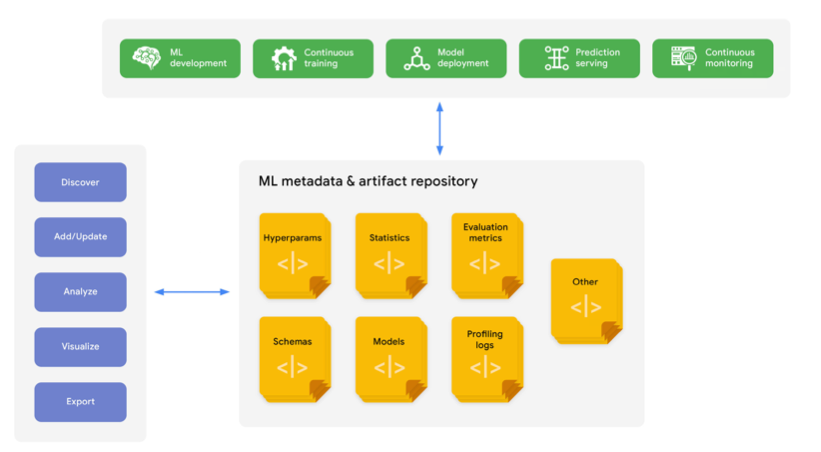
- 모델의 파라미터나 architecture를 기록할 필요가 있음
- 기록을 기반으로 가장 좋은 성능을 보이는 모델을 적용해야함
- 모델의 학습으로 나오는 부산물들인 artifact, 이미지 (feature importance, confusion matrix등…)를 저장해야 함
- 학습과 관련된 metadata를 기록할 수 있음
- 필요에따라 모델을 여러개 동시에 사용할 수도 있음
- 대표적인 실험 assistant는 MLFlow가 있음
Feature Store
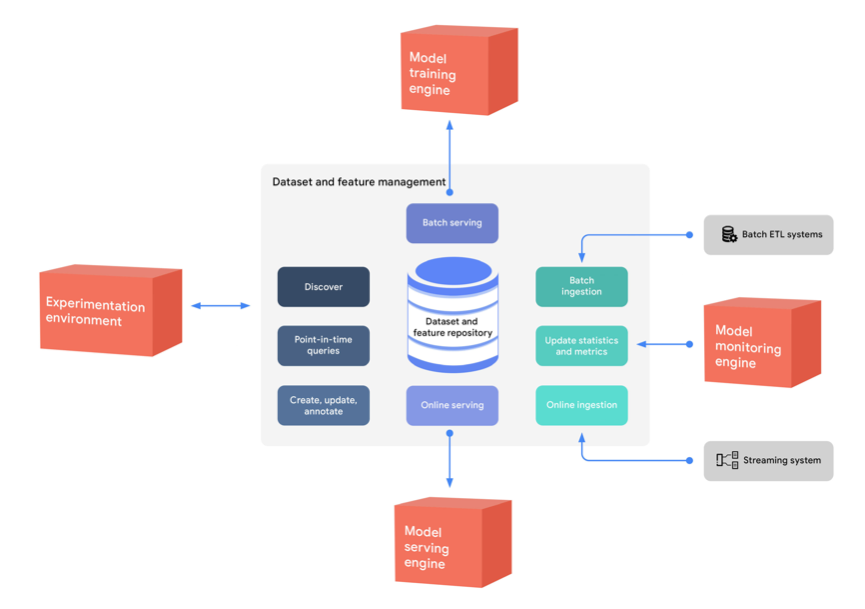
- tabular data에서 유용한 feature를 미리 준비해두는 경우
- 미리 feature store를 만들어두면 시간을 아낄 수 있음
- 대표적인 feature store는 FEAST가 있음
- 현재 제한적인 사용때문에 feature store 라이브러리가 그렇게 많진 않음
Data Validation
- 모델 성능에 가장 직접적으로 영향을 미치는 부분
- MLOps에서 주의 깊에 바라보는 Data Drift, Concept Drift를 볼 필요가 있음
- Feature의 분포나 데이터의 분포를 확인할 필요가 있음
- 다양한 Drift에 대해 모델이 지속적으로 학습을 해야 성능 개선이 필요함
- 대표적인 라이브러리로는 Tensorflow Data Validation(TFDV)가 있지만 tensorflow 한정으로 동작할 수 있는 것이라 한계가 있음
Continuous Training

- Drift에 대해 잘 대처했어도 성능 개선이 일어나지 않는 경우가 있을 수 있음
- 다시 학습을 진행해서 모델을 다시 설계할 수도 있음
- 이 경우 새로운 데이터, 주기, 평가지표를 재정의 할 수도 있음
Monitoring
- 모델 성능, 인프라 성능을 기록하면서 지속적인 모니터링을 해야함
- 여기서 지표는 단순히 성능만이 아닌 에러 발생이나 특정 값 이상으로 변동되는지를 확인해야 함
AutoML
- 좀 더 모델의 성능을 높이고 효율을 높이고자 데이터를 넣으면 자동으로 모델 아키텍처를 찾아줌
- 대표적으로 MS NNi가 있음
Comments powered by Disqus.