
Python : Pandas
데이터 로드
import pandas as pd- 일반적으로 pandas는
read_xxx()함수를 활용해 데이터를 불러온다.
Series
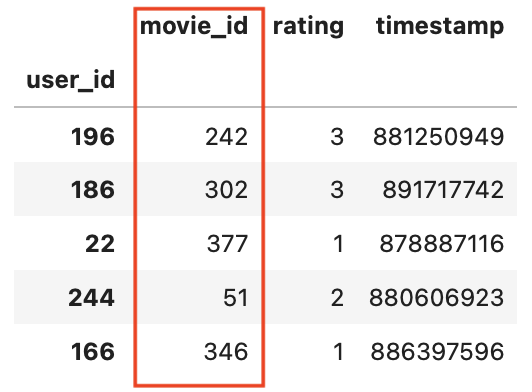
- 데이터프레임에서 하나의 column vector data object를 series라고 한다.
- (index, data) 한 쌍으로 이루어진 데이터 객체
astype을 통해 type을 일괄적으로 변경가능- index를 기준으로 series가 생성되므로 값이 index보다 적으면
NaN으로 채워짐
DataFrame
1. 개념
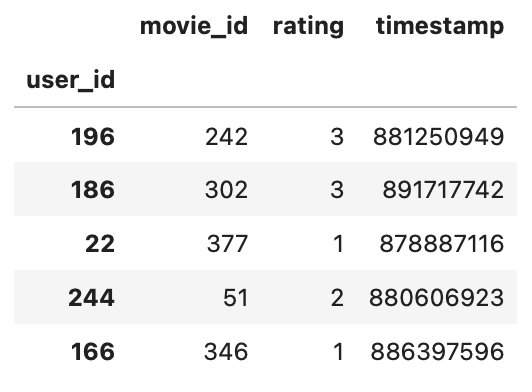
pd.DataFrame(data, columns)- index와 column으로 구성
- series를 모아서 만든 data table이다.
- R에서 존재하는
data.frame을 본 따서 만든 것 - dictionary type으로 생성하는 경우가 많음
2. indexing
loc: index location으로 (index의 이름으로 탐색)iloc: index number- example
- 일반적인 행렬의 transpose와 동일
4. delete column
- 데이터프레임에서 특정 컬럼을 제거하는 방법은 2가지가 있다.
del df[column]: memory상에서 해당 컬럼을 제거df.drop(column, axis=1): df는 유지되므로 다시 할당해줘야 적용
5. to_csv()
df.to_csv(filename, index)- 일반적으로 많이 데이터프레임을 저장하는 형태이다.
index파라미터는 일반적으로False로 선언하여 저장한다.
Selection, drop
1. selection
df[colum]: column 1개를 반환 (series type)df[[columns]]: column을 1개 이상 반환 (dataframe type)- boolean index와 fancy index도 사용가능
loc[[index], [columnn]]으로 특정 position data를 가져올 수 있음iloc[:row, :col]: 특정 행, 열의 position data를 가져올 수 있음
2. reset_index
reset_index(drop, inplace)drop: 기존 index의 제거 여부 (True,False)inplace: 기존의 df를 변경할지 여부
3. drop
df.drop([rows])df.drop([columns], axis=1)
lambda, map, apply
1. map
- example :
df.column.map({"male":0, "female":1})
2. replace
- example :
df.column.replace({"male":0, "female":1})
3. apply
- 특정 series 전체에 특정 함수를 적용
- 내장연산함수(built-in)도 사용가능함
4. applymap
- 데이터프레임 모든 값에 함수를 적용함
Built-in function
df.describe()df[column].unique()sum,mean…isnull과sum을 활용해 결측치의 개수를 확인 가능df.sort_values(by=[column], ascending=True)df.corr(),df.cov()df[column].value_counts()
Groupby
- split -> apply -> combine 순서로 연산을 진행
df.groupby(기준 columns)[적용 column].연산()- group으로 묶인 data를 multi-index인 경우
unstack을 사용하면 matrix형태로 바꿀 수 있음 reset_index를 하면 groupby를 풀어줌- example
- base dataframe
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21
ipl_data = { "Team":[ "Riders", "Riders", "Devils", "Devils", "Kings", "Kings", "Kings", "Kings", "Riders", "Royals", "Royals", "Riders", ], "Rank":[1,2,2,3,3,4,1,1,2,4,1,2], "Year":[2014, 2015, 2014, 2015, 2014, 2015, 2016, 2017, 2016, 2014, 2015, 2017], "Points":[876, 789, 863, 673, 741, 812, 756, 788, 694, 701, 804, 690] } df = pd.DataFrame(ipl_data)
- groupby
1 2
h_index = df.groupby(["Team", "Year"])["Points"].sum() h_index
unstack()1 2 3 4 5 6 7 8 9 10 11
h_index.unstack() ''' <output> Year 2014 2015 2016 2017 Team Devils 863.0 673.0 NaN NaN Kings 741.0 812.0 756.0 788.0 Riders 876.0 789.0 694.0 690.0 Royals 701.0 804.0 NaN NaN '''
- base dataframe
- group으로 묶인 data를 multi-index인 경우
- groupby를 split형태로 사용하면 key-value 형태로 추출가능
- 추출된 group정보는 3가지 유형의 apply가 가능
- aggregate : 요약통계 (
agg) - transformation : 정보변환 (
transgorm) - filteration : 필터링기능 (
filter)
- aggregate : 요약통계 (
pivot table
df.pivot_table(data, index colums)- 특정 구성의 데이터를 재구성하는 방법
Merge & concat
merge: sql의 join과 유사concat: 비슷한 방법으로 합침- example
1 2
pd.merge(df1, df2, how="method", on="col") pd.concat([df1, df2], ignore_index=True, axis=1/0)
Comments powered by Disqus.