
Python : Numpy
행렬의 표현
\[\begin{aligned} \begin{aligned} 2x_{1} + 2x_{2} + x_{3} = 9 \\ 2x_{1} - x_{2} + 2x_{3} = 6 \\ x_{1} - x{2} + 2x_{3} = 5 \end{aligned} \rightarrow \begin{bmatrix} 2 & 2 & 1 & 9 \\ 2 & -1 & 2 & 6 \\ 1 & -1 & 2 & 5 \end{bmatrix} \end{aligned}\]위와 같은 수식이 존재할 때 선형대수에서는 이를 행렬로 표현하는 방식을 많이 사용한다.
- 행렬을 코드로 나타내는 방법에는 2가지 방식이 있다.
- 리스트 표현
1 2
matrix = [[2, 2, 1], [2, -1, 2], [1, -1, 2]] constant = [9, 6, 5]
- 이 방식은 큰 matrix를 표현하기엔 메모리상 문제가 있음
- 처리속도의 문제가 발생
- Numpy 활용
- 리스트 표현
Numpy
- 리스트에 비해 빠르고, 메모리 효율적
- 반복문 없이 데이터 배열을 처리할 수 있음
- C, C++, Fortran과 통합이 가능함
- 사용시
import numpy as np로 선언
1. ndarray
np.array(data, dtype)- numpy array의 저장타입
- 리스트와 다르게 dynamic typing이 불가능하고 하나의 타입만 사용 가능
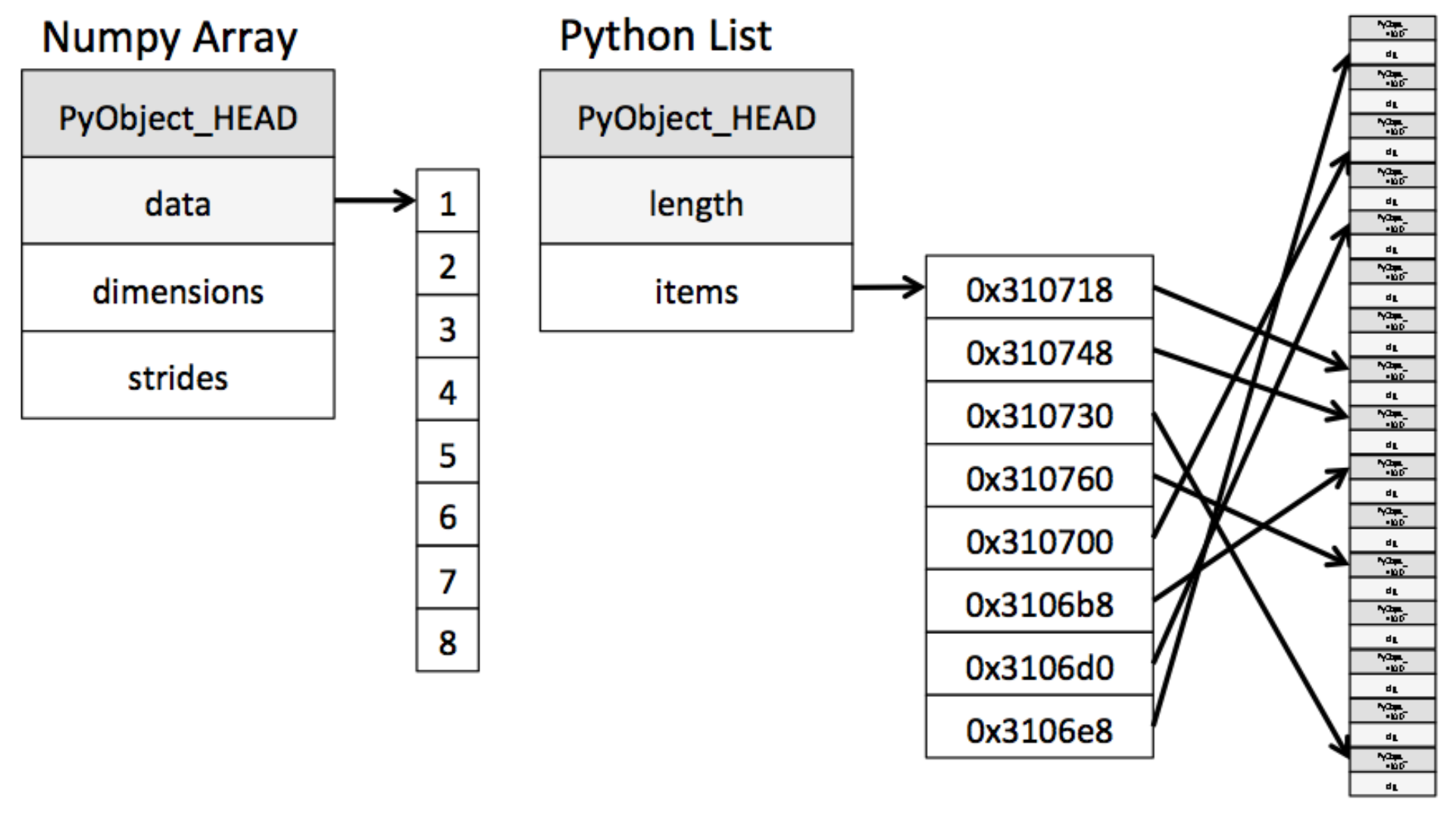
- 리스트는 item을 메모리주소로 static하게 저장하지만
ndarray는 data에 값을 직접적으로 메모리에 저장하기 때문에 연산속도가 빠르다.
![]()
array의 shape에 따라서 이름을 다르게 부른다.
Rank Name ex 0 scalar 7 1 vector [10, 10] 2 matrix [[10, 10], [15, 15]] 3 3-tensor [[[1,5,9],[2,6,10]],[[3,7,11],[4,8,12]]] n n-tensor … shape: numpy array의 dimension을 반환 (몇행 몇열의 구성인지)dtype: numpy array의 데이터 type을 반환ndim: number of dimension (dimension 수만 반환)size: data의 개수 (각 차원별 데이터 수를 곱한 값)
Handling Shape
1. reshape
ndarray.reshape(shape)- element의 갯수는 동일하게 유지하고 shape만 변경
- shape의 특정 dimension 값이 -1이면 알아서 값을 조정해줌
1 2 3 4 5 6 7 8 9 10 11 12 13
test_matrix = [[1, 2, 3, 4], [5, 6, 7, 8]] print(np.array(test_matrix)) print(np.array(test_matrix.reshape(4, 2))) ''' <output> [[1 2 3 4] [5 6 7 8]] [[1 2] [3 4] [5 6] [7 8]] '''
2. flatten
ndarray.flatten()- 다차원 array를 1차원 array로 변환
1 2 3 4 5 6
test_matrix = [[1, 2, 3, 4], [5, 6, 7, 8]] print(np.array(test_matrix).flatten()) ''' <output> [1 2 3 4 5 6 7 8] '''
Indexing & Slicing
- indexing과 slicing은 파이썬의 list나 numpy array를 다룰때 모든 것이라 할만큼 중요하다.
a[:, 2:]: 모든 row의 2열 이상의 데이터a[1, 1:3]: 1행의 1~2열 데이터a[1:3]: 1~2행의 데이터a[:, ::2]: 모든 행의 시작부터 2단위의 열 데이터
numpy creation
1. arange
np.arange(start, end, step)- example
1 2
np.arange(10) # array([0, 1, 2, 3, 4, 5, 6, 7, 8, 9]) np.arange(0, 5, 0.5) # array([0. , 0.5, 1. , 1.5, 2. , 2.5, 3. , 3.5, 4. , 4.5])
2. ones, zeros, empty
np.zeros(shape, dtype): 0으로 가득한 ndarraynp.ones(shape, dtype): 1로 가득찬 ndarraynp.empty(shape): shape만 있고 빈 ndarray (값을 초기화하지 않음)- example
1 2 3 4 5 6
# ones np.ones((2, 3), dtype=float) # zeros np.zeros((2, 3)) # empty np.empty((10, 5))
3. something_like
np.ones_like(ndarray):ndarray랑 shape가 같고 1로 구성된 ndarraynp.zeros_like(ndarray):ndarray랑 shape가 같고 0으로 구성된 ndarraynp.empty_like(ndarray):ndarray랑 shape가 같고 초기화가 안된 값으로 구성된 ndarray
4. identity
np.identity(n=rows, dtype): n x n의 단위행렬- example
1 2 3 4 5 6
np.identity(n=3, dtype=np.int8) ''' array([[1, 0, 0], [0, 1, 0], [0, 0, 1]], dtype=int8) '''
5. eye
np.eye(N, M, k): N x M 행렬에서 k가 시작 index인 대각성분이 1인 행렬- example
1 2 3 4 5 6
np.eye(N=3, M=5, k=1) ''' array([[0., 1., 0., 0., 0.], [0., 0., 1., 0., 0.], [0., 0., 0., 1., 0.]]) '''
6. diag
np.diag(ndarray, k=시작index): 대각 성분을 추출- example
1 2 3 4 5 6 7 8 9 10
matrix = np.arange(9).reshape(3, 3) print(matrix) print(np.diag(matrix)) ''' [[0 1 2] [3 4 5] [6 7 8]] [0 4 8] '''
7. random_sampling
np.random.uniform(모수, 갯수): uniform 분포np.random.normal(모수, 갯수): 정규 분포- 이 외에 다양한 통계 분포를 쓸 수 있음
Operation function
1. sum
sum(): 모든 원소의 합sum의 인자로는 axis가 존재- axis = 1 : col 방향의 합
- axis = 0 : row 방향의 합
- 축이 추가되면 새로 생기는 축이 항상 axis = 0을 나타냄
2. concatenate
vstack(): vertical stack으로 위아래로 두 array를 합침- 합치는 두 array는 반드시 열의 개수가 일치해야한다.
hstack(): horizontal stack으로 좌우로 두 array를 합침- 합치는 두 array의 행은 반드시 개수가 일치해야한다.
concatenate(axis)axis=0: 위아래로 합침axis=1: 좌우로 합침
Array operations
- element-wise 연산을 모두 지원함
- +, -, /, * 로 행렬을 계산하면 각 위치의 원소로 연산
- dot product : 행렬 곱 연산 (내적 연산)
arr.dot(arr)
- transpose : 전치행렬
arr.Torarr.transpose()
- broadcasting
- shape이 다른 배열간의 연산을 해줌
\(\begin{align} \begin{bmatrix} 1 & 2 & 3 \\ 4 & 5 & 6 \end{bmatrix} + 3 = \begin{bmatrix} 4 & 5 & 6 \\ 7 & 8 & 9 \end{bmatrix} \end{align}\)
- shape이 다른 배열간의 연산을 해줌
Comparison
np.where(condition, Tvalue, Fvalue): codition에 만족하는 index를 반환하고 value가 주어지면 만족하는 위치에 해당되는 값으로 대체한다.np.argmax(ndarray),np.argmin(ndarray): array의 최대/최소의 index를 반환- axis 기반으로 가능할 수 있음
argsort(): 값을 기반으로 정렬된 index를 반환
Comments powered by Disqus.