
RecSys : DeepCTR
CTR Prediction
- 서비스에서 가장 중요하게 바라보는 것은 CTR을 예측하는 것
- CTR예측의 정확성은 매출 향상에 직결되는 요소라 광고 서비스에서 자주 활용됨
- 현실 CTR 데이터의 한계
- High Sparsity
- non-linear association
- 이런 한계를 해결하고자 딥러닝 모델이 도입됨
Wide & Deep
 Wide & Deep Learning for Recommender Systems
Wide & Deep Learning for Recommender Systems
- Paper: Wide & Deep Learning for Recommender Systems
- Google PlayStore에 활용하기 위한 모델
- 선형모델과 비선형 모델을 결합하여 서로의 장점을 취한 논문
문제 제기
- 추천 시스템에서는 2개의 해결해야 할 과제가 존재
- Memorization : 빈번하게 등장하는 아이템이나 특성 관계를 학습 (자주 나타나는 관계는 암기)
- Generalization : 드물게 나타나거나 전혀 발생하지 않은 관계도 고려할 필요가 있음 (일반화 문제)
- Memorization은 전형적인 Logistic Regression문제와 연결이 깊음
- 모델 자체가 단순하고 수학적 관점이라 해석이 용이함
- 하지만 Regression이라는 것 자체가 기본적으로 주어진 데이터에서 찾아내는 것들이라 학습 데이터에 없는 feature 조합에 취약하다는 단점이 존재
- Generalization은 FM이나 DNN 같은 임베딩 기반 모델이 유리함
- sparsity 문제가 발생함
- 서로의 단점이 보완가능하기 때문에 둘을 결합한 모델을 제안
문제 해결 모델
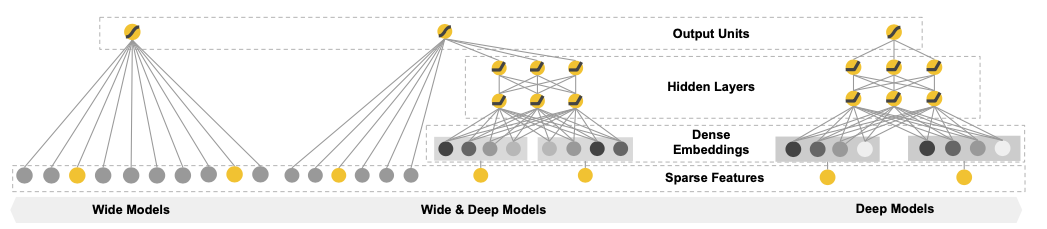 Wide & Deep Learning for Recommender Systems
Wide & Deep Learning for Recommender Systems
- 크게 2개 구성으로 이루어져 있음
- The Wide Component
- The Deep Component
The Wide Component
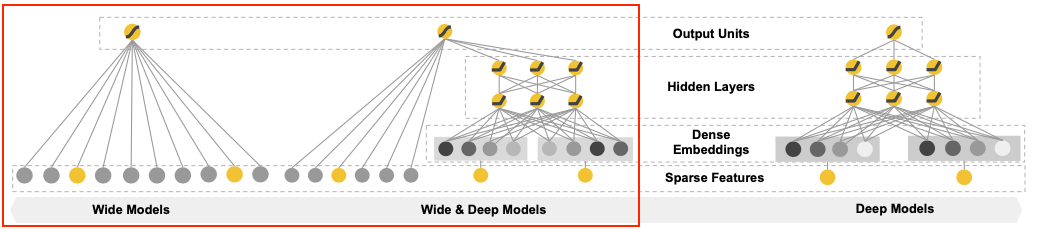 Wide & Deep Learning for Recommender Systems
Wide & Deep Learning for Recommender Systems
- wide component는 기본적으로 logistic regression 원리를 갖게됨
- 핵심은 변수간의 interaction을 구하는 것
- < Cross-Product Transformation >
- 모든 cross product를 구하면 파라미터의 수가 기하급수적으로 증가
- 주요 feature 2개를 쓰는 second-order product만 진행
- 논문에서는 User Installed App과 Impression App만 사용
- 기존의 polynomial logistic regression처럼 2개의 feature의 AND interaction을 표현함
The Deep Component
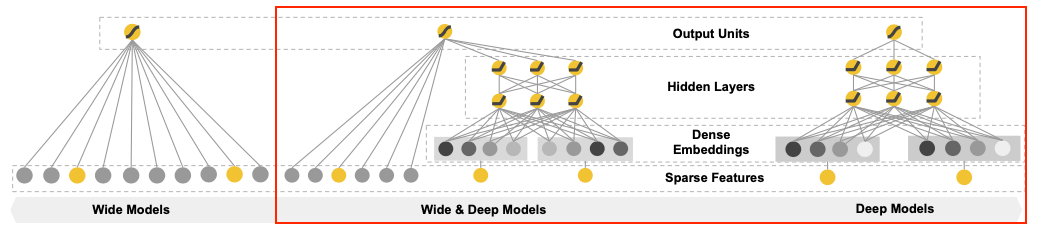 Wide & Deep Learning for Recommender Systems
Wide & Deep Learning for Recommender Systems
- < Feed-Forward Neural Network >
- 3 lyaer로 구성되었고 ReLU 함수 사용
- 연속형 변수는 그대로, 범주형 변수는 feature embedding 진행
전체 구조 및 loss function
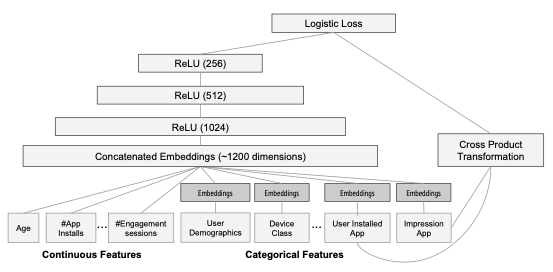 Wide & Deep Learning for Recommender Systems
Wide & Deep Learning for Recommender Systems
- Cross Product Transformation에 들어가는 feature는 유저가 설치했던 아이템과 현재 추천하려는 아이템에 대한 정보가 들어감
- $\phi(\mathbf{x})$는 cross product transformation 결과
DeepFM
 DeepFM: A Factorization-Machine based Neural Network for CTR Prediction
DeepFM: A Factorization-Machine based Neural Network for CTR Prediction
- Paper: DeepFM: A Factorization-Machine based Neural Network for CTR Prediction
- wide & deep 모델의 한계인 feature engineering을 진행해야한다는 문제를 해결한 모델
문제 제기
- 추천 시스템은 implicit feature interaction을 학습하는 것이 중요함
- 기존 모델은 low-order나 high-order 중 한 쪽에만 강한 문제가 있음
- 즉 feature 그 자체를 쓰거나 통째로 활용하는 방식
- 이를 해결한 것이 wide & deep model이지만 wide component에서 feature engineering이 필요하다는 한계가 존재 (feature engineering은 효과는 좋지만 어렵고 시간이 오래 걸리는 문제가 있음)
- 이를 해결하고자 기본 아이디어가 second-order인 Factorization Machine을 wide component로 활용
문제 해결 모델
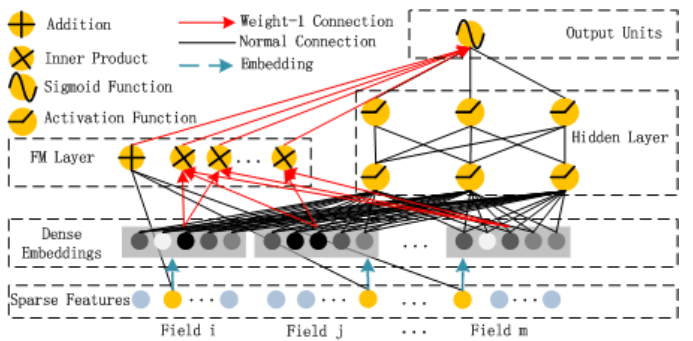 DeepFM: A Factorization-Machine based Neural Network for CTR Prediction
DeepFM: A Factorization-Machine based Neural Network for CTR Prediction
- 모델은 크게 2개의 구조로 구성
- FM Component
- Deep Component
FM Component
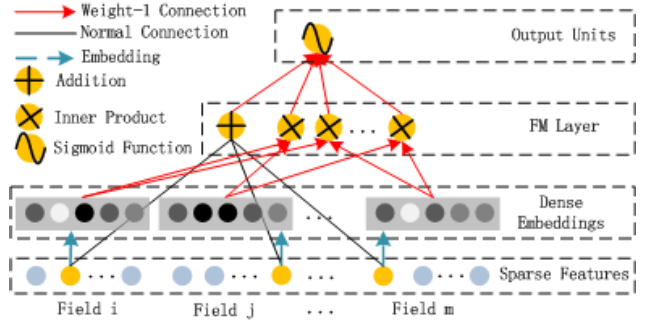 DeepFM: A Factorization-Machine based Neural Network for CTR Prediction
DeepFM: A Factorization-Machine based Neural Network for CTR Prediction
- low-order feature interaction을 처리하는 역할을 기존의 FM과 동일한 구조를 활용함
- FM의 특성상 second-order feature interaction 처리에 효과적임
Deep Component
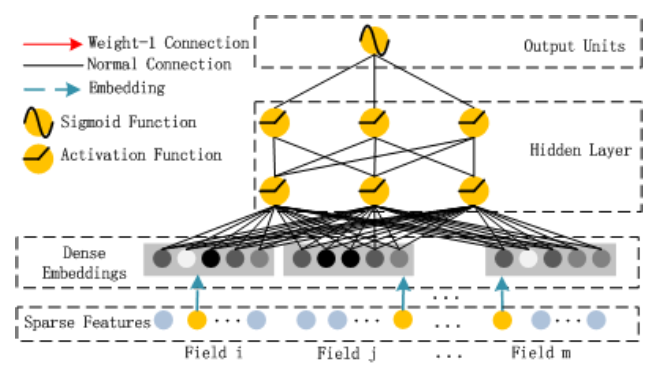 DeepFM: A Factorization-Machine based Neural Network for CTR Prediction
DeepFM: A Factorization-Machine based Neural Network for CTR Prediction
- high-order feature interaction을 처리하는 역할로 DNN을 활용
- 모든 feature는 동일한 차원(k)으로 임베딩 (논문에서는 5차원)
- 임베딩에 사용되는 가중치는 FM과 동일한 가중치($V_{ij}$)와 동일
- 실제 전체 모델 구조를 보면 알 수 있듯이 임베딩을 각 Component가 공유하는 것을 알 수 있음
다른 모델과의 비교
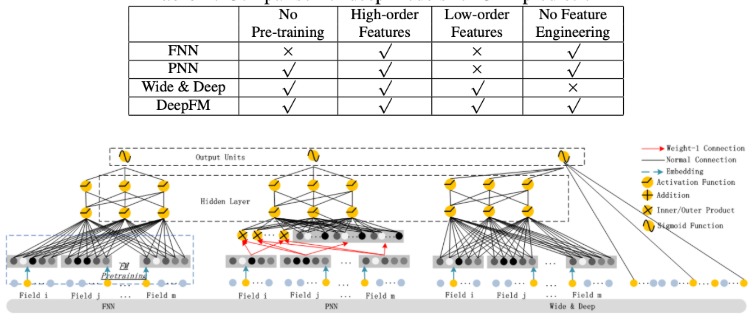 DeepFM: A Factorization-Machine based Neural Network for CTR Prediction
DeepFM: A Factorization-Machine based Neural Network for CTR Prediction
- FNN은 **Factorization Machine의 학습이 필요하다는 문제가 존재
- PNN은 feature interaction 처리는 가능하지만 low-order, 즉 feature 단일의 특징을 처리하는 데에 문제가 있음
- Wide & Deep은 앞서 말했듯이 feature engineering이 필요하다는 문제가 존재
Deep Interest Network (DIN)
 Deep Interest Network for Click-Through Rate Prediction
Deep Interest Network for Click-Through Rate Prediction
- Paper: Deep Interest Network for Click-Through Rate Prediction
- user behavior feature를 처음으로 사용한 논문
문제 제기
- 기본 DL기반 모델은 모두 유사한 embedding과 MLP 아이디어를 사용함
- 결국 목표는 sparse data embedding후 fully-connected training임
- 이런 방식을 사용하는 경우 사용자의 행동으로부터 나오는 여러가지 관심사 반영이 어려움
- 예를 들어 어떤 유저는 특정 카테고리를 보다가 추천 목록 상품을 클릭할 수도 있음
- 이는 사용자의 context를 반영해야 함
- 결국 사용자의 소비 목록들이라는 user behavior feature를 생성하여 소비 아이템과 예측 대상의 관련성을 학습할 필요가 있음
문제 해결 모델
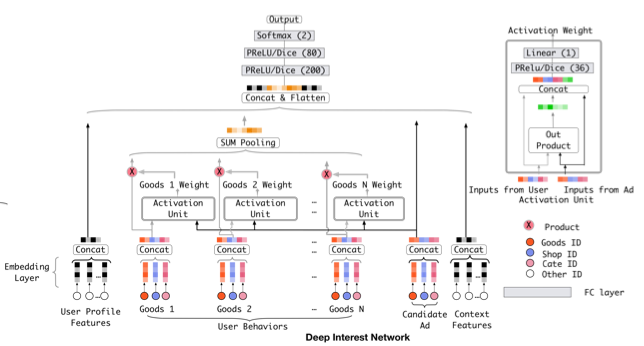 Deep Interest Network for Click-Through Rate Prediction
Deep Interest Network for Click-Through Rate Prediction
- 모델은 크게 3개의 구조를 가짐
- Embedding Layer
- Local Activation Layer
- Fully-connected Layer
- 다른 부분은 다 비슷하고 핵심은 Local Activation Layer
Local Activation Layer
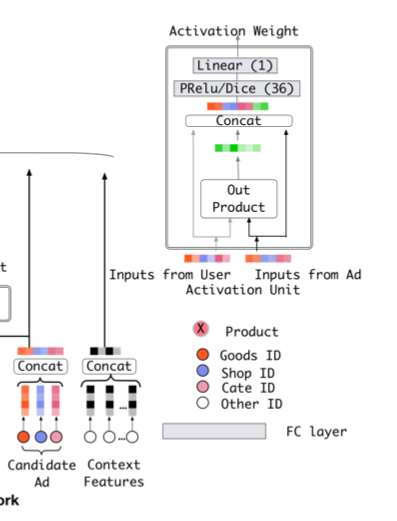 Deep Interest Network for Click-Through Rate Prediction
Deep Interest Network for Click-Through Rate Prediction
- user behavior에서 1개의 광고를 뽑아서 후보군이 되는 광고와 Activation Unit에서 연관성을 계산
- Activation Unit을 통과하면 activation weight가 나오는데, 이는 현재와 과거의 소비 아이템의 연관성을 나타내는 가중치
- Weighted Sum Pooling : 구해진 가중치를 각 representation vector에 곱하고 합을 통해 연산함
- activation unit은 후보군이 되는 광고에 따라 유저의 과거 소비 제품의 weight가 달라짐
Behavior Sequence Transformer (BST)
 Behavior Sequence Transformer for E-commerce Recommendation in Alibaba
Behavior Sequence Transformer for E-commerce Recommendation in Alibaba
- Paper: Behavior Sequence Transformer for E-commerce Recommendation in Alibaba
- Transformer를 사용한 CTR 예측 논문
- DIN에서 local activate unit이 transformer의 attention 같은 역할을 하는 데에서 착안
논문 아이디어
- CTR 예측과 NLP 사이에는 공통점이 존재함
- 대부분 sparse data
- 아이템이건 단어건 실제로 하나의 케이스에 있는 데이터는 전체 데이터에 비해 적음
- low, high-order feature interaction이 모두 존재
- 문장도 순서가 중요하듯 사용자도 행동 순서가 중요한 역할을 하기도 함
- 사람들은 핸드폰을 사고 그에 맞는 핸드폰 케이스를 삼 (반대의 경우는 매우 드묾)
- 대부분 sparse data
- 이런 점을 토대로 NLP에서 좋은 성능을 보이는 transformer를 적용하는 아이디어를 제시
모델 구조
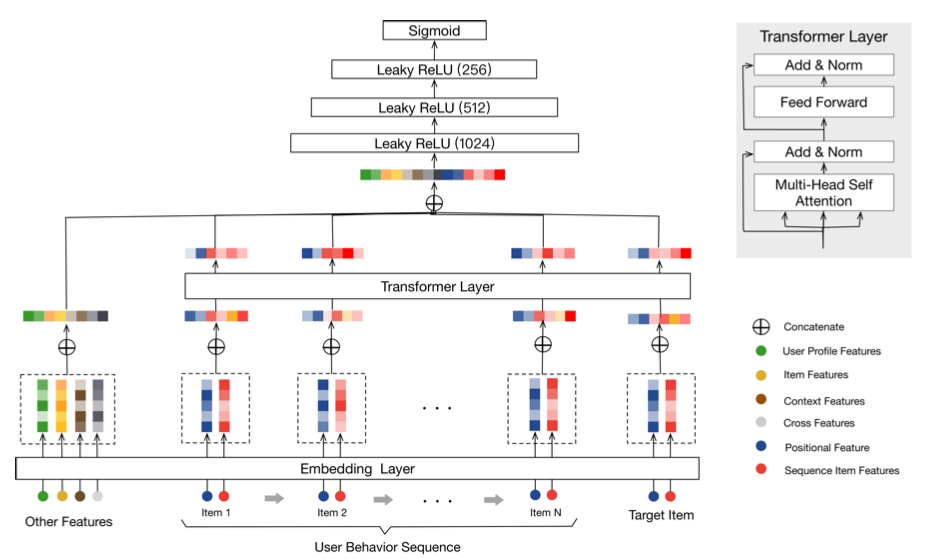 Behavior Sequence Transformer for E-commerce Recommendation in Alibaba
Behavior Sequence Transformer for E-commerce Recommendation in Alibaba
- transformer의 encoder 부분만을 가져와서 user behavior의 가중치를 파악
Transformer Encoder Layer
\[\begin{aligned} &\mathbf{F} = \text{FFN}(\mathbf{S}) \\ &\mathbf{S}' = \text{LayerNorm}(\mathbf{S} + \text{Dropout}(\text{MH}(\mathbf{S}))) \\ &\mathbf{F} = \text{LayerNorm}(\mathbf{S}' + \text{Dropout}(\text{LeakyReLU}(\mathbf{S}'\mathbf{W}^{(1)} + b^{(1)})\mathbf{W}^{(2)})) \\\\ &\mathbf{S}^{(i+1)} = \text{MH}(\mathbf{F}^{(i)}) \\ &\mathbf{F}^{(i+1)} = \text{FFN}(\mathbf{S}^{(i+1)}) \end{aligned}\]- transformer encoder 부분에서는 일반적인 transformer의 처리 방식과 동일한 수식이 적용
- 기존 transformer와 다른 점은 dropout과 leaky relu를 적용했다는 점에서 차이가 존재
- transformer block은 1~4개를 사용한 결과 1개 층을 사용하는 것이 더 좋은 효과를 보임
- 아마도 NLP 보다 sequence 복잡성이 낮기 때문으로 생각
- attention의 positional encoding은 기존의 $\cos$나 $\sin$을 쓰지 않고 물리적인 시간 차이인 $t(v_t) - t(v_i)$를 사용함
Comments powered by Disqus.