
RecSys : Recommender System with DL
이 내용은 논문들을 전반적으로 훑는 내용들입니다.
향후 논문 리딩을 통해 더 자세한 내용이 paper review 카테고리에 추가될 예정입니다.
추천 시스템의 딥러닝
- 최근에는 추천 시스템에 딥러닝의 아이디어를 도입하는 연구가 많이 진행됨
- 딥러닝을 도입하는 이유는 크게 다음과 있음
- Nonlinear Transformation
- MF나 factorization machine 등은 기본적인 원리가 linear를 가정한 것이므로 model에서 표현의 한계가 존재
(기존의 XOR과 같은 문제) - DNN은 데이터의 non-linearity를 효과적으로 나타낼 수 있음
- user-item pattern은 복잡한 관계를 가지는데 linear로는 이 관계를 효과적으로 모델링하기 어려울 수 있음
- MF나 factorization machine 등은 기본적인 원리가 linear를 가정한 것이므로 model에서 표현의 한계가 존재
- Representation Learning
- DNN은 raw data로부터 featrue representation을 직접 학습
- Sequence Modeling
- next-item prediction, session-based recommendation(동일 세션 추천)과 같은 sequential task에 효과가 좋음
- 동일 세션의 시간순 데이터를 통한 예측
- Flexibility
- Tensorflow, PyTorch등 여러 프레임워크를 활용해 실질적 서비스에 적용할 수 있음
- Nonlinear Transformation
Neural Collaborative Filtering

- MF의 한계를 지적하며 신경망 구조의 모델을 제시
- Paper : Neural Collaborative Filtering
문제 제기
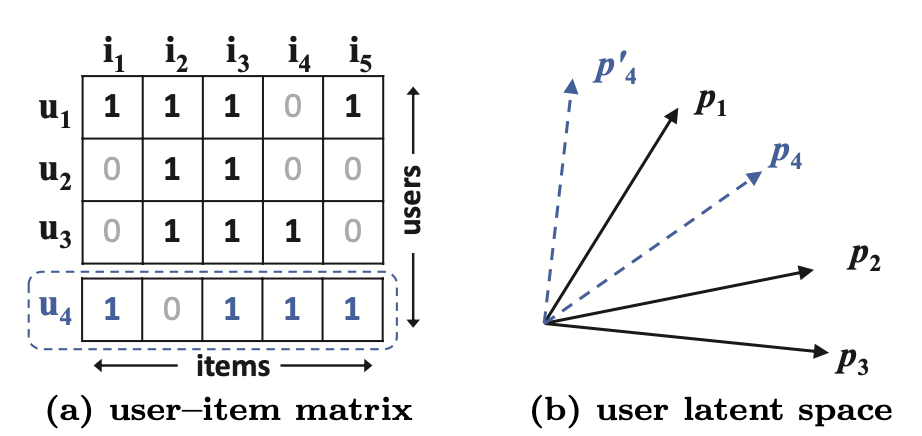
- Matrix Factorization의 한계
- user와 item embedding이 선형조합 형태라는 것
- 선형관계는 표현의 한계를 가짐
- similarity를 찾는 과정에서 latent space에서 정확한 유사관계를 표현하는데 문제가 발생함
- 실제 논문에서 언급하는 MF의 한계로는 user-item embedding에서는 실제로 $sim_{41}$과의 관계에서 jacard 유사도로 계산하면 $sim_{43}$이 $sim_{42}$보다 더 가깝지만 latent vector space에서는 어떠한 방법을 써도 $sim_{42}$가 더 가깝게 위치함
- 이를 해결하는 방법으로는 2차원의 경우는 3차원으로, 3차원이면 4차원으로 차원을 늘리는 형식의 vector space 변환을 진행해야하지만 차원을 증가하는 것은 한계가 존재
문제 해결 모델
- 모델 구성을 크게 2가지 파트로 구분됨
- MLP 파트
- MF 파트
MLP 파트
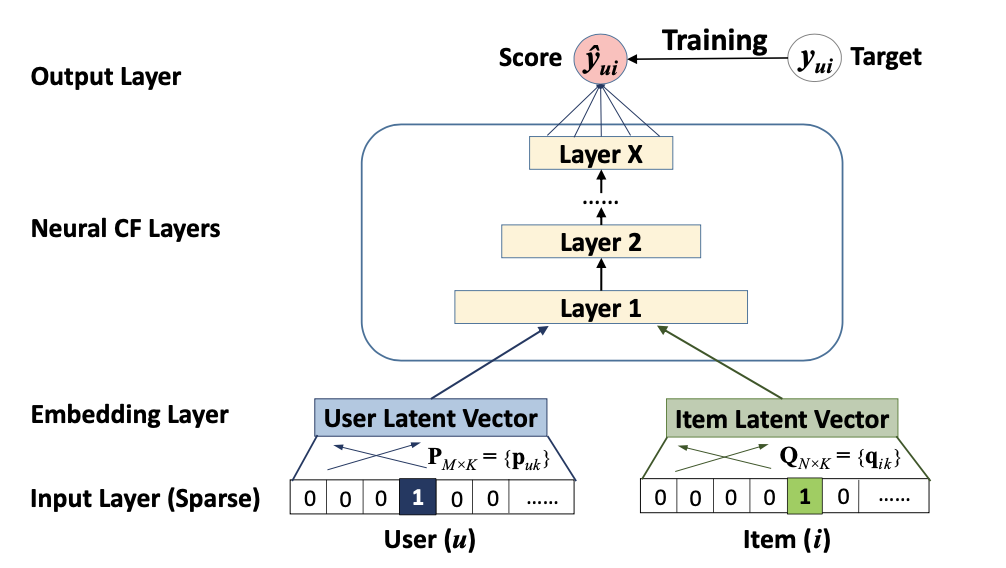
- Input Layer
- one-hot encoding user(item) vector : $v_u (v_i)$
- Embedding Layer
- user(item) latent vector : $P^\intercal v_u (Q^\intercal v_i)$
- Neural CF Layers
- $\phi_{X}(\cdots\phi_{2}(\phi_{1}(P^\intercal v_u, Q^\intercal v_i))\cdots)$
- $\phi_{X}$는 x번째 neural network
- $\phi_{1}(P^\intercal v_u, Q^\intercal v_i)$는 각 latent vector결과를 concatenate한 것을 신경망에 feed하는 것을 의미
- Output Layer
- activation function : Logistic or Probit
- $ \widehat{y}_{ui} = \phi_o (\phi_X(\cdots\phi_2(\phi_1 (P^\intercal v_u, Q^\intercal v_i))\cdots)) $
- $\widehat{y}_{ui} \in [0,1]$
최종 모델
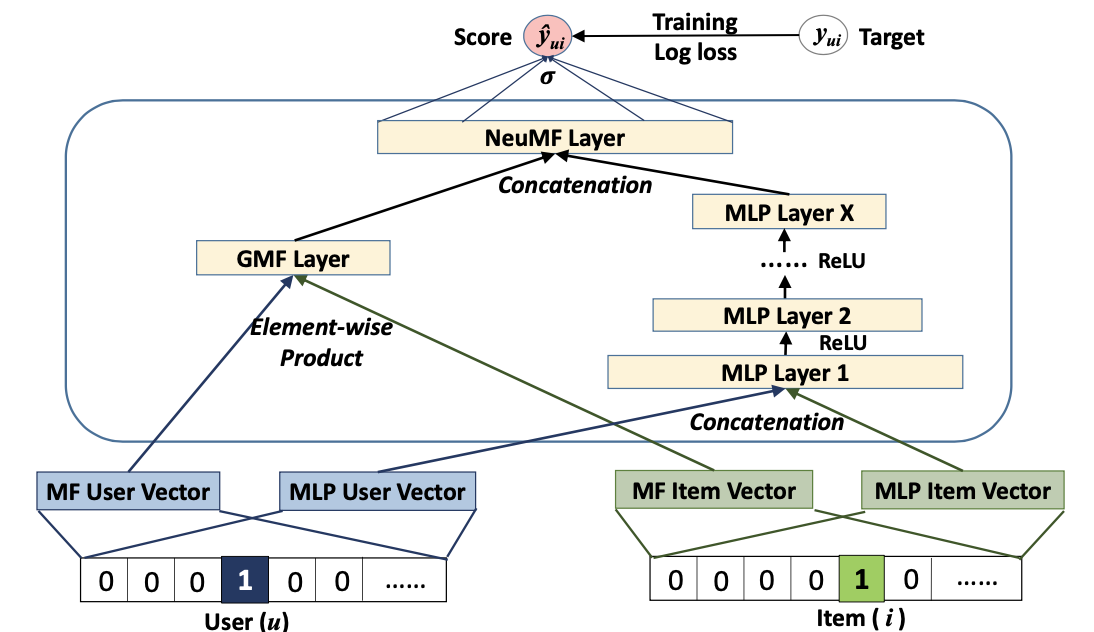
- Neural Matrix Factorization
- GMF라는 MF 일반화 모델과 MLP를 앙상블
- 기존 MF의 장점인 sparsity 해결과 같은 장점을 가져오면서 단점인 표현 한계를 MLP로 극복
- 두 모델은 서로 다른 embedding layer를 사용
- $\phi^{GMF} = (p_u^G)^\intercal q_i^G$
- $\phi^{MLP} = \phi_{X}(\cdots\phi_{2}(\phi_{1}(p_u^M, q_i^M))\cdots)$
- $\widehat{y}_{u,i} = \sigma\left( h^\intercal \begin{bmatrix} \phi^{GMF} \ \phi^{MLP} \end{bmatrix} \right)$
- MovieLens, Pinterest 데이터셋에 대하여 NCF의 추천 성능이 MF(BPR), MLP 모델보다 높음
Deep Neural Networks for YouTube Recommendations

문제 제기
- Scale
- 유저와 아이템의 수가 매우 많음
- 컴퓨팅 파워의 제한
- 효율적인 서빙과 추천 알고리즘이 필요
- Freshness
- 기존의 학습 컨텐츠와 새로운 컨텐츠를 실시간으로 잘 조합해야 함 (exploration / exploitation)
- Noise
- 높은 Sparsity와 다양한 외부 요인 때문에 유저 행동 예측이 어려움
- Implicit Feedback과 같은 낮은 품질의 메타데이터를 써야 효과가 좋음
모델 전체 구조
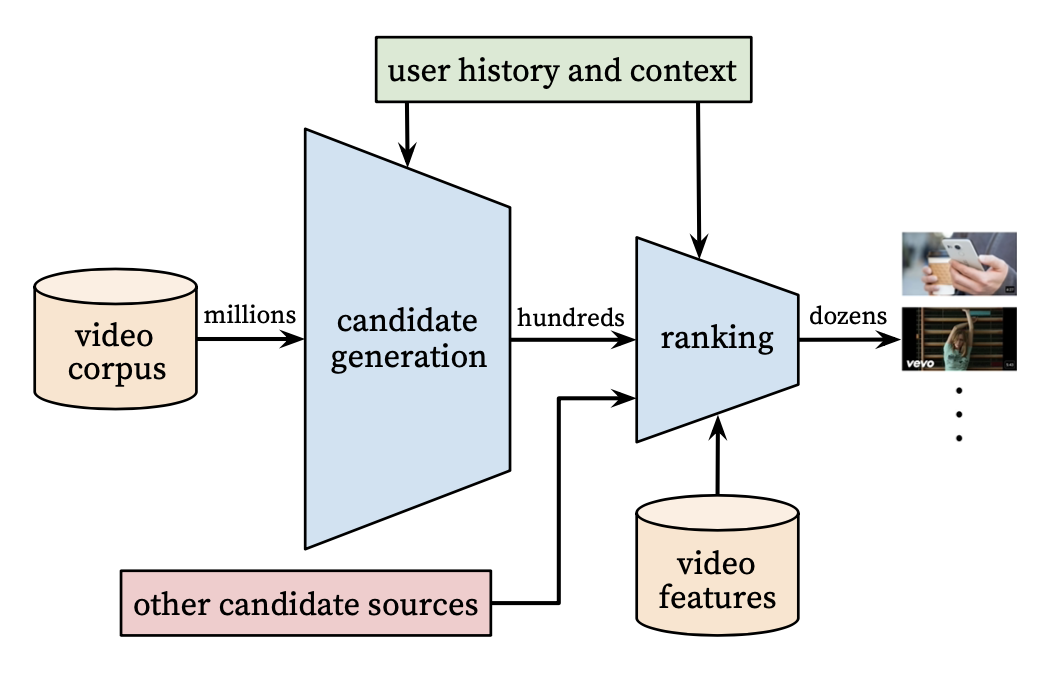 Deep Neural Networks for YouTube Recommendations
Deep Neural Networks for YouTube Recommendations
- 모델은 크게 2개의 추천 구조로 이루어져있음
- Candidate Generation
- High Recall을 위해 수많은 데이터 중 유저에게 어울리는 수백개의 Top N개 추천 후보군을 추출
- 이때 다양한 유저의 정보를 활용
- Ranking
- Candidate Generation에서 생성된 추천 후보군에서 유저, 비디오 등 feature를 다채롭게 사용하여 최종 추천 리스트 제공
- Candidate Generation
Candidate Generation
 Deep Neural Networks for YouTube Recommendations
Deep Neural Networks for YouTube Recommendations
- 주어진 특정 유저 $u$가 선호할 video의 리스트를 생성하는 것이 목적
- 특정 시간(t)에 유저 U가 C라는 context에서 비디오(I)를 볼 확률을 계산
- 수백개의 아이템에서 후보군을 선택해야하므로 Extreme multiclass classification 문제
- 마지막에 내적을 통한 Softmax 함수를 사용하여 유저와 비디오의 관계를 계산하여 분류 진행
 Deep Neural Networks for YouTube Recommendations
Deep Neural Networks for YouTube Recommendations
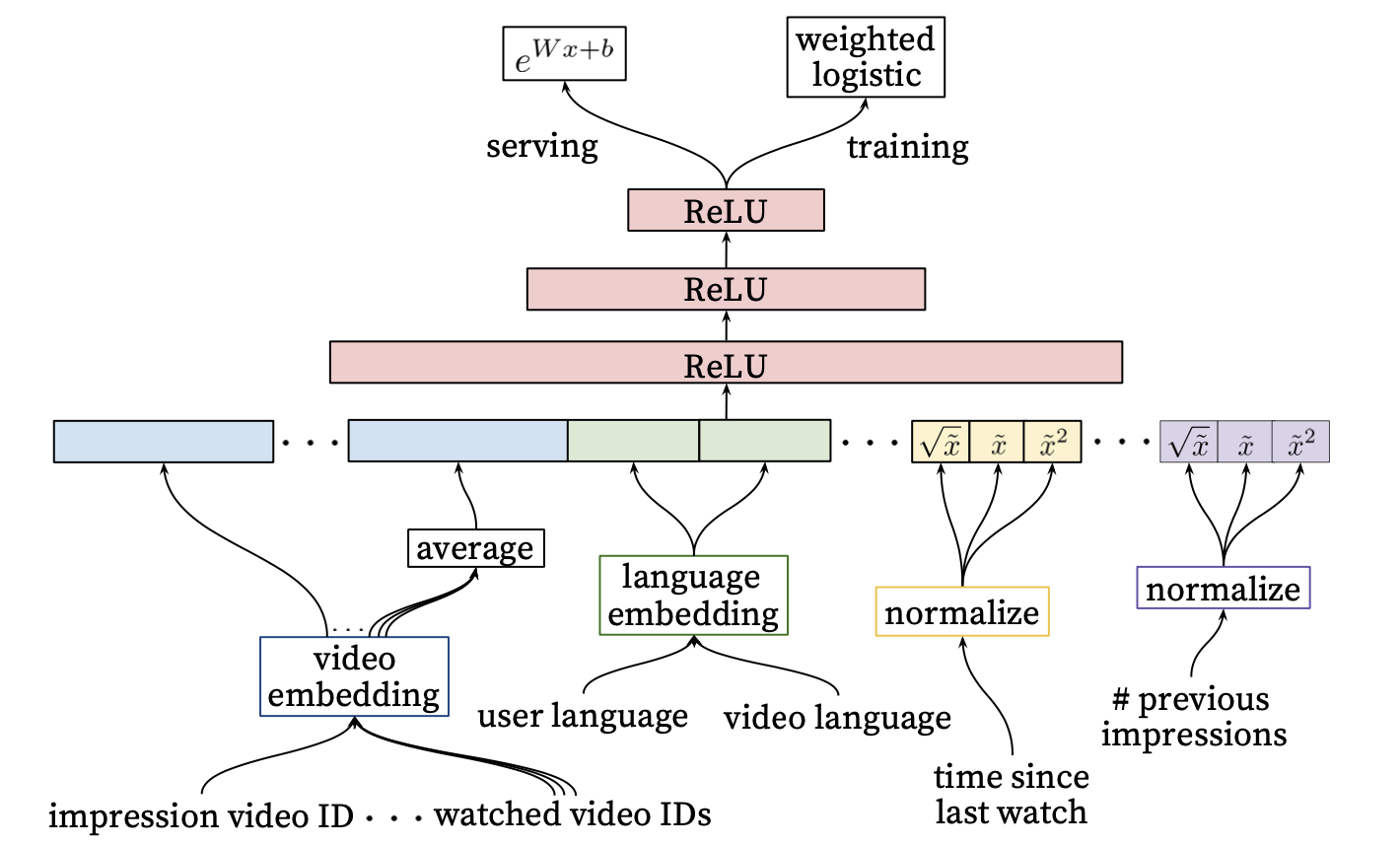
- CG에서 가장 중요한 embedding vector
- 다른 추천 모델에서는 유저의 행동 정보를 잘 활용하지 않았음
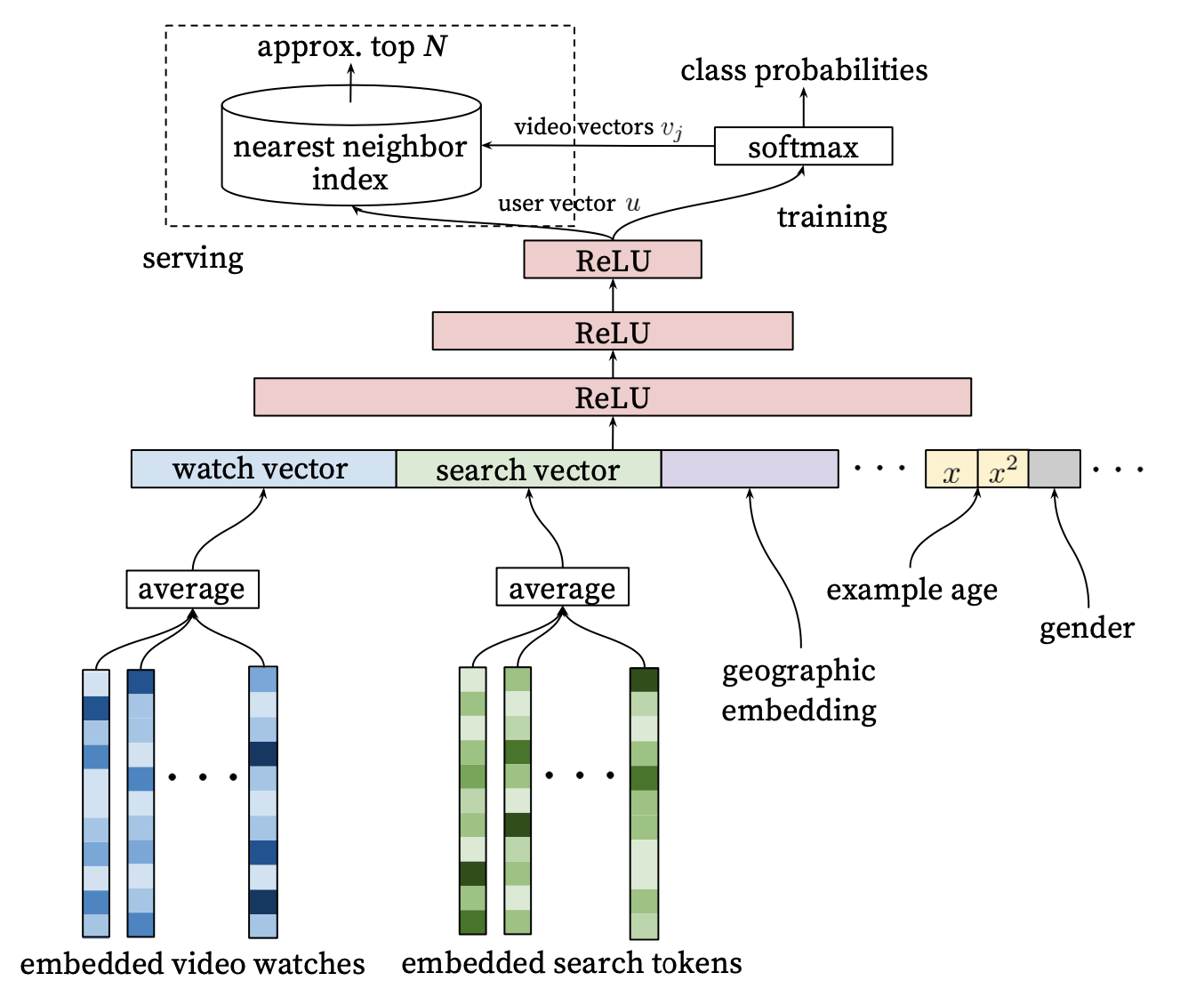
- 유저의 행동기록 임베딩
- 과거의 시청 이력과 검색 이력을 임베딩하여 vector 형성
- 마지막 기록들이 너무 강한 영향을 미치는 것을 방지하고자 전반적인 임베딩의 평균을 적용
 Deep Neural Networks for YouTube Recommendations
Deep Neural Networks for YouTube Recommendations
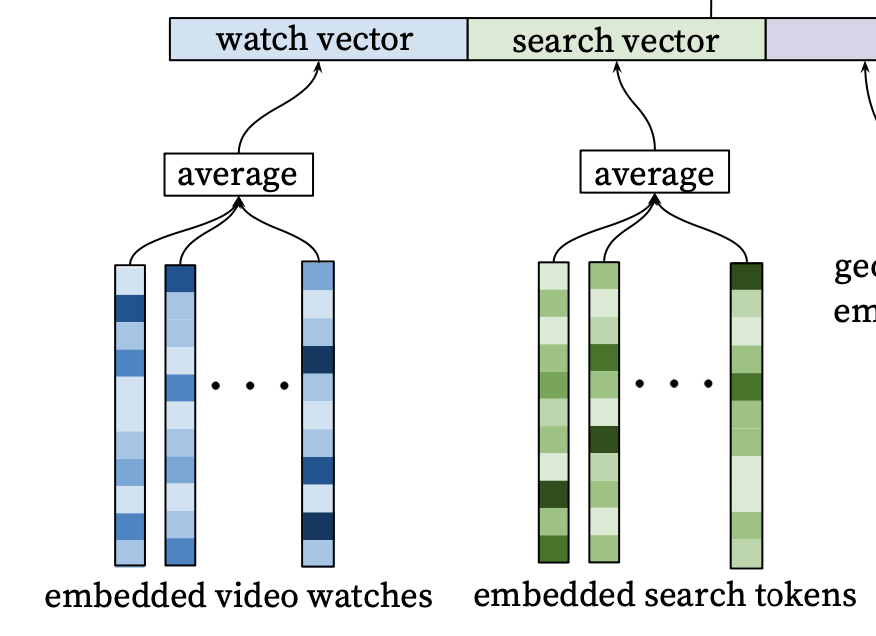
- 성별 등 인구통계학 정보, 지리적 정보를 vector에 포함
- Example Age
- 과거 데이터에 편향된 학습이 이뤄지는 것을 해결하고자 시청 로그가 학습 시점에서 경과한 정도를 피쳐로 추가
- 모델은 오래된 아이템의 특성상 과거의 인기 아이템에 편향되어 학습을 하는 경우가 있음
- 이런 경우 최신의 아이템은 과거에 비해 밀리게 되므로 아이템의 최신성을 고려하고자 추가로 feature에 학습
 Deep Neural Networks for YouTube Recommendations
Deep Neural Networks for YouTube Recommendations
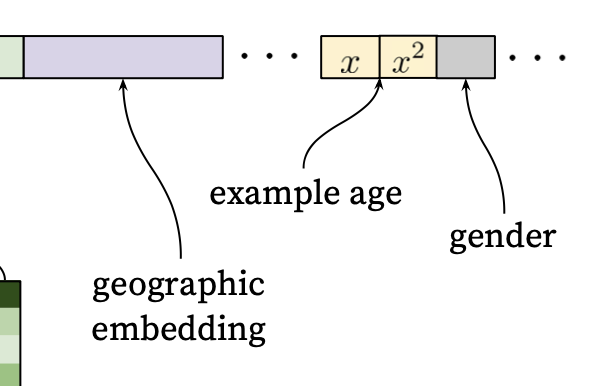
- 위에서 생성된 모든 벡터를 concatenate 후 layer에 feed하여 나오는 것이 User Vector
- User Vector를 입력으로 하여 softmax를 통해 나온 아이템의 임베딩과 내적을 통해 유저와 아이템의 유사정도를 계산
- 이 과정은 아이템 자체가 수백개라 연산시간이 너무 오래 걸려 실제 serving에서는 무리가 있음
- 따라서 실제 serving에는 user vector와 video vector embedding index를 활용해 수백개의 리스트에서 Annoy와 Faiss등으로 Top-N을 추출하여 전달
Ranking
 Deep Neural Networks for YouTube Recommendations
Deep Neural Networks for YouTube Recommendations
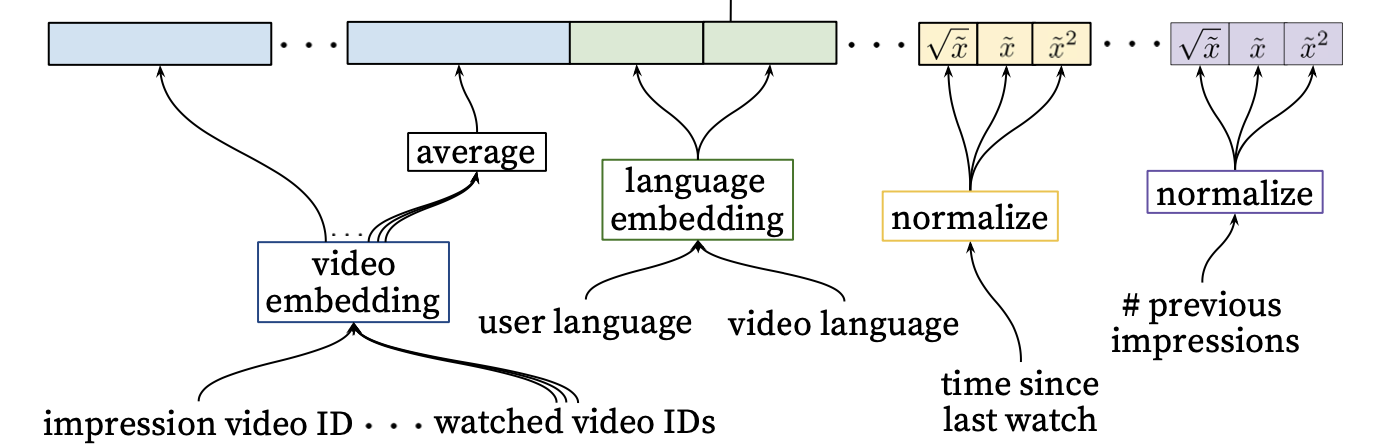
- Candidate Generation에서 받은 비디오 후보군에서 최종 추천 아이템 순위를 책정
- 클릭확률을 계산하는 Logistic 회귀를 사용
- loss function에서 weighted logistic은 비디오 시청시간을 가중치로 한 값이 사용됨
 Deep Neural Networks for YouTube Recommendations
Deep Neural Networks for YouTube Recommendations
- 입력 feature로는 user의 행동 패턴 feature가 사용됨
- 유저가 특정 채널에서 얼마나 많은 영상을 봤는가?
- 특정 토픽 영상을 본 지 얼마나 지났는지 등…
- feature engineering 부분이라 도메인 전문가의 역량이 중요
 Deep Neural Networks for YouTube Recommendations
Deep Neural Networks for YouTube Recommendations
- 여러가지 feature를 전달받은 neural network를 통과한 결과는 비디오가 실제로 시청될 확률 매핑
- binary classification으로 시청 여부만을 예측
- loss function에서 weighted logistic을 활용하는 이유는 영상 시청 시간은 유저의 만족도와 비례하기 때문
- 이 과정에서 cross-entropy 사용
- 예를 들어 사용자가 좋아하는 부류의 영상은 전체 동영상 길이에 근접한 시청시간을 갖지만 광고나 관심이 없는 영상은 실수로 시청을 했더라도 매우 적은 시청시간을 갖게될 것
논문의 의의
- 최초의 2단계 추천 딥러닝 모델을 제안
- 기존 CF에서는 참고 feature의 종류가 적었던 부분을 보완하는 방식을 채택
- 실제 시청시간을 예측하므로 더 뛰어난 성능을 보여줌
- CG에서도 많은 feature를 사용하지만 추가적으로 ranking과정에서도 많은 feature를 쓰므로 성능이 좋음
AutoEncoder
- 오토인코더란 입력 데이터를 hidden layer를 통해 feature representation을 진행하여 입력을 재구축하는 출력을 만드는 모델
- 중간에 있는 hidden layer는 입력 데이터들의 feature representation 정보를 담고 있음
- 오토인코더는 깔끔한 데이터에 overfitting되는 경향이 존재해서 일부러 noise넣어 학습하는 Denoising Autoencoder가 등장함
- noise나 dropout으로 입력 데이터를 손상하여 학습
AutoRec

- Paper : AutoRec: Autoencoders Meet Collaborative Filtering
- Autoencoder를 CF에 적용하여 feature representation을 더 효과적으로 적용
- Rating Vector를 입력과 출력으로 하여 AutoEncoder를 학습
- 중간에 hidden layer는 유저-아이템 rating vector를 latent feature로 저장하는 역할
- 기존 MF와의 차이는 linear라는 한계로 복잡한 관계를 표현하기 어려움이 존재
모델
 AutoRec: Autoencoders Meet Collaborative Filtering
AutoRec: Autoencoders Meet Collaborative Filtering
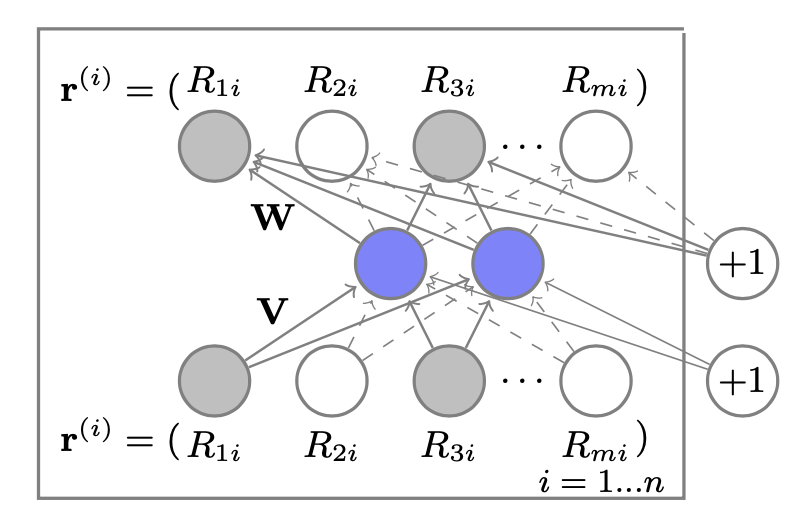
- 모델 자체는 매우 간단하다. 실제 구현도
nn.Linear2개로 구현한다….;; - 임베딩은 아이템과 유저 중 1개만 진행
- $\mathbf{r}^{(i)}$ : 아이템 $i$의 rating vector
- $R_{ui}$ : 유저 $u$의 아이템 $i$에 대한 rating
- $V$ : 인코더 가중치 행렬, 실제로는
nn.Linear - $W$ : 디코더 가중치 행렬, 실제로는
nn.Linear
학습
\[\begin{aligned} \underset{\theta}{\min}\sum_{\mathbf{r}\in \mathbf{S}} \lVert \mathbf{r} - h(\mathbf{r} ; \theta) \rVert_2^2 \qquad \\\\ h(\mathbf{r} ; \theta) = f(\mathbf{W} \cdot g(\mathbf{V}\mathbf{r} + \boldsymbol{\mu}) + \mathbf{b}) \end{aligned}\]- 기존 rating matrix와 출력으로 생성되는 reconstructed rating matrix의 RMSE를 목적함수로 설정
- 관측된 데이터에 대해서만 역전파와 파라미터 업데이트
- 구현시
np.where(y != 0)으로 관측 데이터를 확인
- 구현시
- $g(\mathbf{V}\mathbf{r} + \boldsymbol{\mu})$: representation 항
Collaborative Denoising Auto-Encoder

- Paper : Collaborative Denoising Auto-Encoders for Top-N Recommender Systems
- Denoising Autoencoder를 적용한 논문
- AutoRec는 추천 아이템을 찾는 것보다는 Rating prediction이 핵심 목표
- CDAE는 ranking을 계산하여 Top-N을 추천하는 모델
- 평가지표로 NDCG를 많이 활용함
- rating prediction이 목표가 아니기 때문에 유저-아이템 정보를 binary 형태로 바꾼 아이템 선호정보(preference)로 변화하여 학습
모델
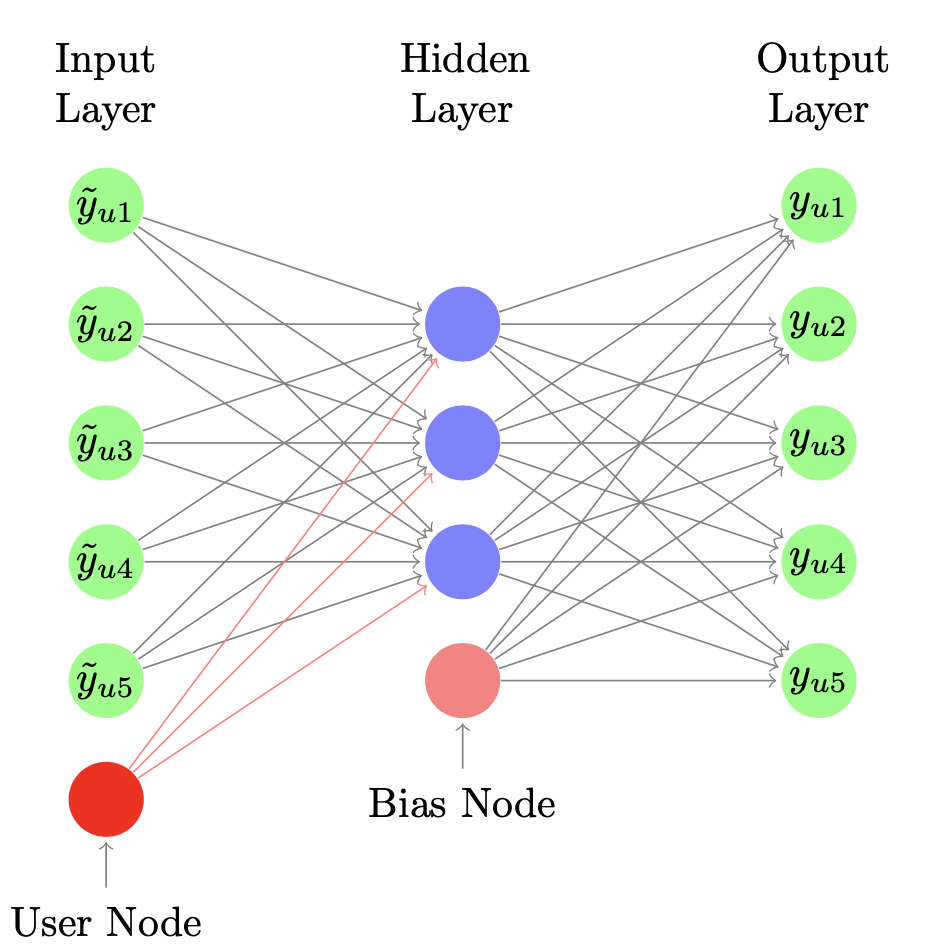 Collaborative Denoising Auto-Encoders for Top-N Recommender Systems
Collaborative Denoising Auto-Encoders for Top-N Recommender Systems
- AutoRec과 다르게 noise를 추가
- noise는 dropout을 활용하여 일부 선호정보를 탈락시킴
- $P(\tilde{y}_u = \delta y_u) = 1-q, P(\tilde{y}_u = 0) = q$
- $\tilde{y}_u$는 q확률에 의해 dropout된 벡터
- 유저 벡터 $V_u$를 학습하면서 다른 유저에 대한 특징을 같이 학습 (collaborative 성격)
- input으로 제공되는 $\tilde{y}$는 각 user의 선호 정보인데 기존 데이터에서 일부는 0으로 처리되는 noise를 제공한다.
- ex) origin = [0, 1, 1, 0, 1], $\tilde{y}$ = [0, 0, 1, 0, 1]
- 추가적으로 개별 유저 정보도 같이 넣어서 학습을 진행함
- 원문: Note that $\mathbf{V}_u$ is a user-specific vector, i.e., for each of the users we have one unique vector. From another point of view, $\mathbf{W}_i$ and $\mathbf{V}_u$ can be seen as the distributed representations of item i and user u respectively.
- encoder의 hidden layer를 통해 latent representation을 만들고 디코더로 재생성
Comments powered by Disqus.