
RecSys : Approximate Nearest Neighbor (ANN)
ANN의 필요성
- 추천 시스템은 기본적으로 Vector Space에 존재하는 새로운 query vector와 가장 유사한 vector를 찾는 방식을 많이 활용함
- MF에서도 아이템과 유저가 같이 임베딩된 latent vector space에서 유저와 아이템의 유사도 연산을 진행하거나 아이템과 아이템의 유사도를 계산함
- 문제는….
- 특정 K개를 뽑기위해 모든 vector space를 탐색하는 Brute Force KNN은 vector의 차원과 개수에 비례한 연산을 진행함
- 100차원 기준 100만개의 벡터의 유사도를 계산할 때 0.1초가 걸린다고 가정하면 1,000,000 X 0.1 = 100,000초 = 약 27.7시간이라는 시간이 소모됨 (실제 소요시간은 0.1초보다 기므로 더 시간이 길어짐)
- 결과적으로 정확도와 시간은 trade-off이므로 정확도를 포기하고 시간을 어느정도 확보하는 방법으로 접근
- 정확한 Nearest Neighbor가 아닌 근사적 접근을 활용한 Approximate NN을 찾는 방법을 사용
ANNOY
ANNOY 개념과 알고리즘
 Github : spotify/ANN
Github : spotify/ANN
- spotify에서 개발한 tree-based ANN 방법
- Github : spotify-ANN / paper
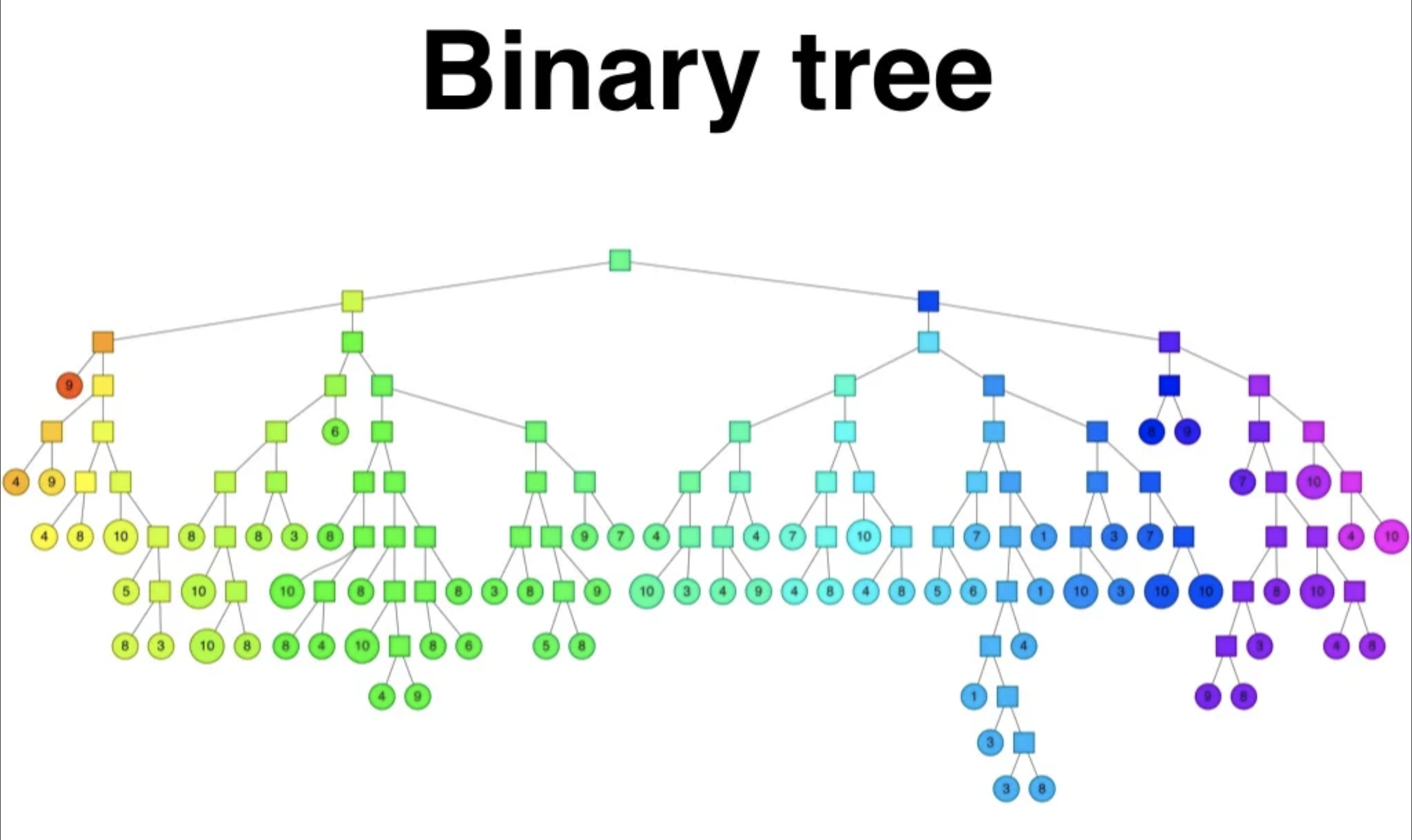
- 주어진 벡터들을 여러 개의 subset으로 나누어 tree 자료구조로 저장하여 탐색하는 방법
 https://www.slideshare.net/erikbern/approximate-nearest-neighbor-methods-and-vector-models-nyc-ml-meetup?from_action=save
https://www.slideshare.net/erikbern/approximate-nearest-neighbor-methods-and-vector-models-nyc-ml-meetup?from_action=save
- Vector Space에서 임의의 두 점을 선택한 뒤, 두 점사이의 hyperplane으로 vector space를 나눔 (두 점 사이의 직선의 수직 이등분하는 hyperplane)
- Subspace에 있는 점들의 개수를 node로 하여 binary tree 생성하거나 갱신
- Subspace 내의 점이 K개를 초과했다면 해당 Subspace에 대해 1, 2를 반복하여 모든 subspace가 K개 아래로 점을 갖게 진행
 https://www.slideshare.net/erikbern/approximate-nearest-neighbor-methods-and-vector-models-nyc-ml-meetup?from_action=save
https://www.slideshare.net/erikbern/approximate-nearest-neighbor-methods-and-vector-models-nyc-ml-meetup?from_action=save
- 특정 query case가 입력되면 트리구조의 특성상 $O(\log N)$ 시간안에 동일 노드에 존재하는 Nearest Neighbor들을 찾을 수 있음
ANNOY의 문제점과 해결방안
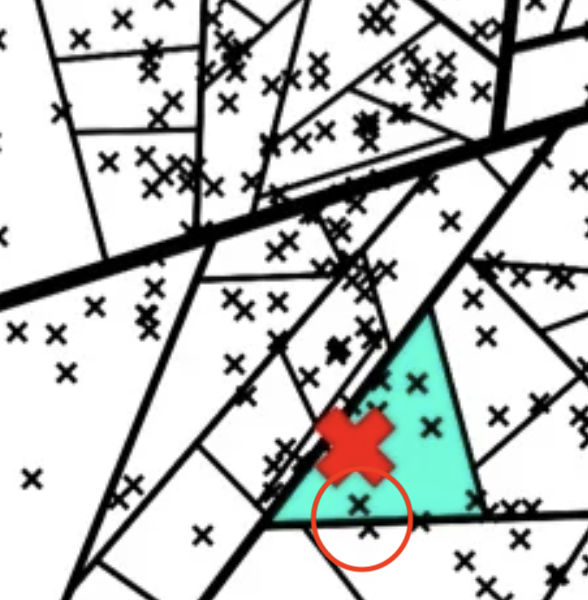
- 붉은색 원안에 있는 것처럼 점이 경계선 근방에 존재한다면 오히려 같은 노드에 존재하는 점들보다 다른 노드에 더 가까운 점이 있지만 NN을 카운트 하지 못함
- 이 문제는 hyperplane을 형성하는 점의 선택이 random으로 이루어지기 때문에 발생하는 것
 https://www.slideshare.net/erikbern/approximate-nearest-neighbor-methods-and-vector-models-nyc-ml-meetup?from_action=save
https://www.slideshare.net/erikbern/approximate-nearest-neighbor-methods-and-vector-models-nyc-ml-meetup?from_action=save
 https://www.slideshare.net/erikbern/approximate-nearest-neighbor-methods-and-vector-models-nyc-ml-meetup?from_action=save
https://www.slideshare.net/erikbern/approximate-nearest-neighbor-methods-and-vector-models-nyc-ml-meetup?from_action=save
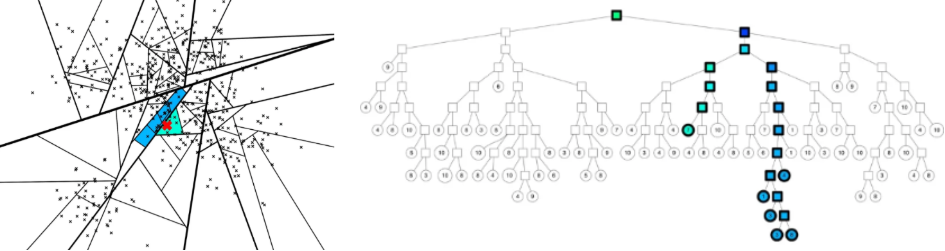
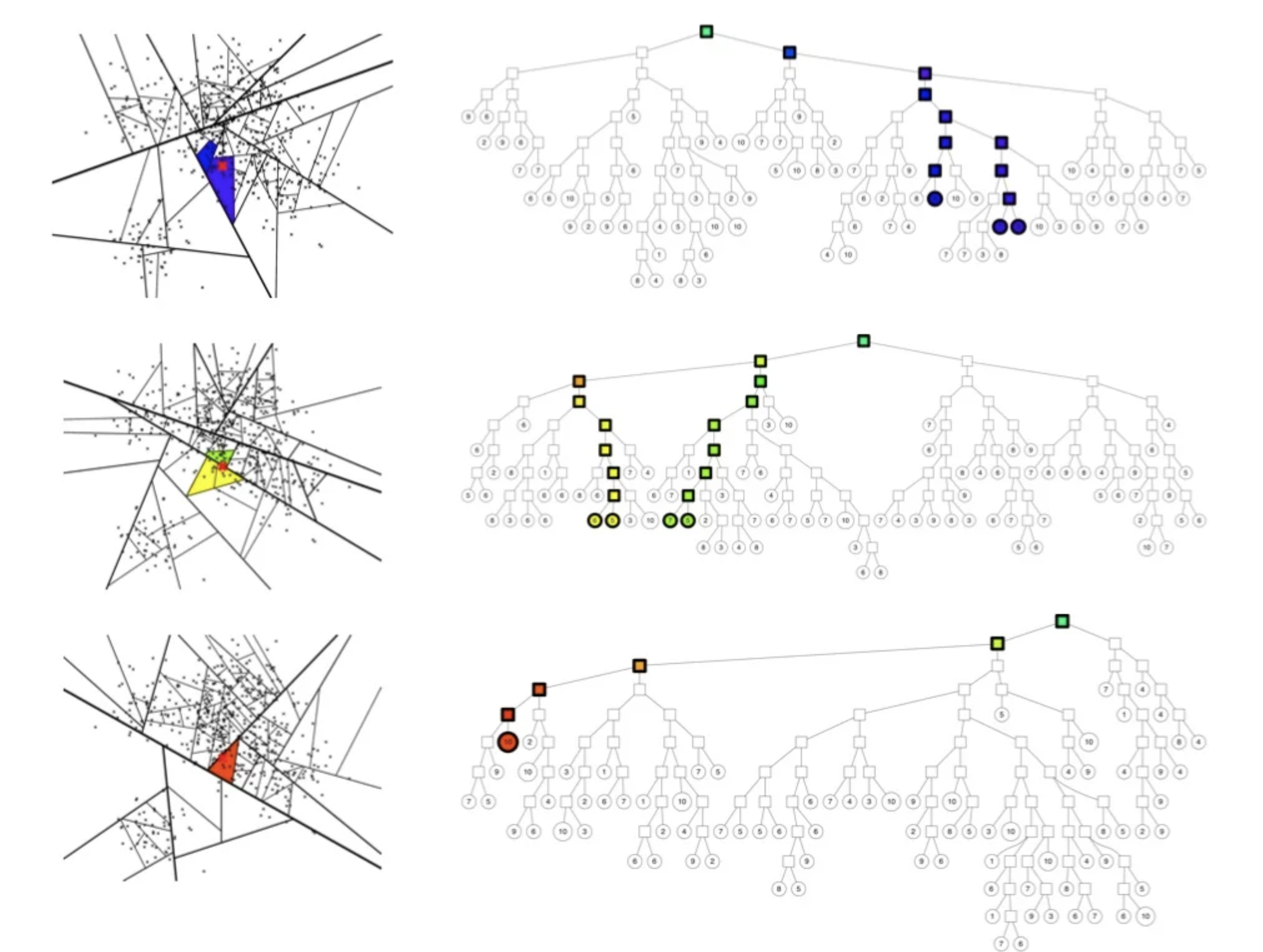
- 이를 해결하고자 다음과 같은 방법을 사용해서 해결
- priority queue를 사용하여 가까운 다른 노드를 탐색
- binary tree를 여러 개 생성하고 병렬적 탐색
- parameter
number_of_trees: 생성하는 binary tree 수search_k: NN을 구할 때 탐색하는 node 수
- 여전히 해결되지 않은 문제는…
- 기존 생성된 bianry tree에 새로운 데이터를 추가할 수 없음
- GPU 연산의 미지원
기타 ANN
Hierarchical Navigable Small World Graphs (HNSW)
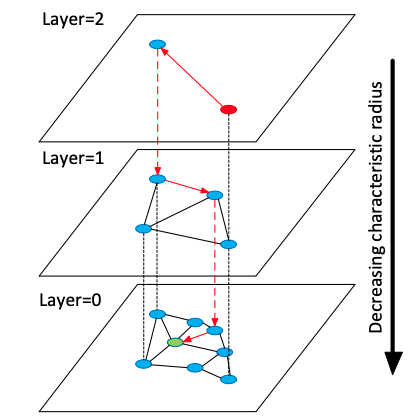
- 벡터를 그래프의 node로 표현하고 인접 벡터를 edge로 연결
- 물리적으로 거리가 작은 node들만 edge를 형성해야 함
- Layer 0 $\rightarrow$ Layer n으로 갈수록 노드를 랜덤 샘플링해서 형성함
nmslib나faiss가 대표적인 라이브러리
- 최상위 layer n에서 임의의 노드에서 시작
- 현재 탐색 layer에서 타겟 노드와 가장 가까운 노드로 이동
- 더 가까워지는 게 불가능하면 다음 하위 layer로 이동
- 타겟 노드에 도달할 때까지 2, 3을 반복
- 2 ~ 4를 진행할 때 방문한 노드들만 후보로 NN 탐색
Inverted File Index (IVF)
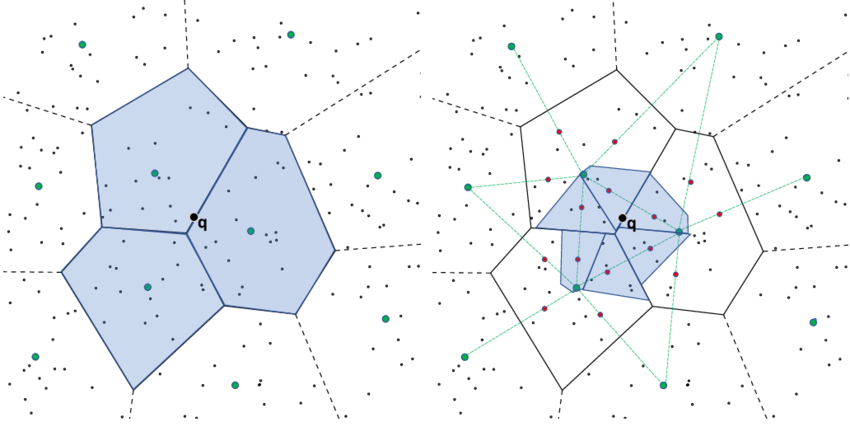
- clustering 과정을 통해 vector를 n개의 클러스터로 나눠서 저장
- vector의 index를 cluster별 inverted list로 저장
- query vector에 대해 cluster 탐색 $\rightarrow$ 해당 cluster의 inverted list의 vector들을 탐색
- 경계 data에서 NN이 발생하는 것을 해결하고자 주변 cluster의 확장과정을 필요로 함
- 클러스터 수가 늘어나면 정확도와 속도의 trade off가 발생
Product Quantization - Compression (PQ)
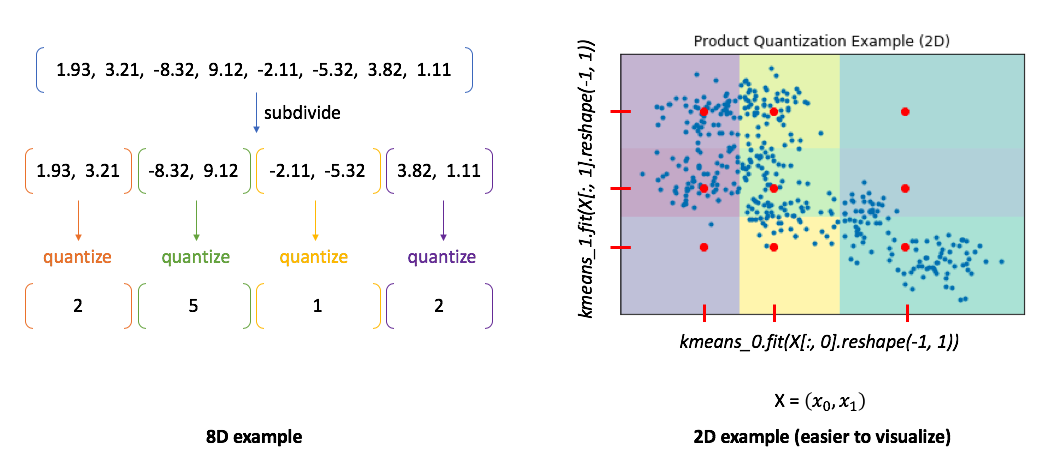
- 기존에 존재하는 벡터를 n개의 sub-vector로 나눔
- 각 sub-vector군에 대해 k-means clustering을 통해 centroid(중심점)을 찾음
- 기존의 모든 vector를 n개의 centroid로 압축해서 표현
- centroid간의 유사도를 활용해서 벡터 유사도를 계산
- PQ와 IVF를 동시에 사용하면 더 빠르고 효율적인 ANN이 수행 가능
faiss라이브러리에서 제공
Comments powered by Disqus.