RecSys : Item2Vec
임베딩 (Embedding)
Embedding
- 데이터를 낮은 차원의 벡터로 표현하는 방법
- Sparse Representation
- 아이템의 전체 종류 = 차원의 수
- 아이템 개수가 많을 수록 벡터
- 대표적인 예시로는 one-hot encoding이 있음
ex) 면도기 = [0, 0, 0, 1, 0, 0]
- Dense Representation
- 아이템 전체 종류 » 차원의 수
- 기존 벡터를 압축해서 표현하므로 binary가 아닌 실수값으로 표현된 벡터 (compact vector)
ex) 면도기 = [0.4, 0.2]
Word Embedding
- 텍스트 분석을 위해 단어를 벡터로 변환하는 것
- 벡터공간에 단어를 배치하기 때문에 단어 간 유사도를 계산할 수 있음
- 임베딩 표현을 위해서는 학습 모델이 필요
- Matrix Factorization에서 latent matrix는 일종의 embedding
Word2Vec
- Neural Network Language Model(NNLM) 기반의 단어예측 기술
- dense vector로 표현하여 대량의 문서를 vector space에 투영
- 대표적인 학습 방법
- CBOW
- Skip-Gram
- Skip-Gram w/Negative Sampling (SGNS)
- Word2Vec은 Item2Vec을 이해하기위한 베이스 정도의 지식만 잡을 것
Continuous Bag of Words (CBOW)
![]()
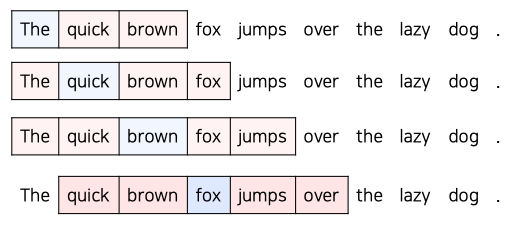
- 주변에 있는 단어를 활용하여 중심 단어를 예측하는 방법
- 인간은 전반적인 맥락을 파악해서 단어를 유추하는데, 이 과정에서 주변부의 단어를 통해 빈칸을 유추하는 경우가 많음
- 앞 뒤 단어의 개수를 window라는 파라미터의 크기로 결정
- 실제 예측에 사용하는 단어는 앞 뒤 n개로 2n개의 단어 사용
![]()
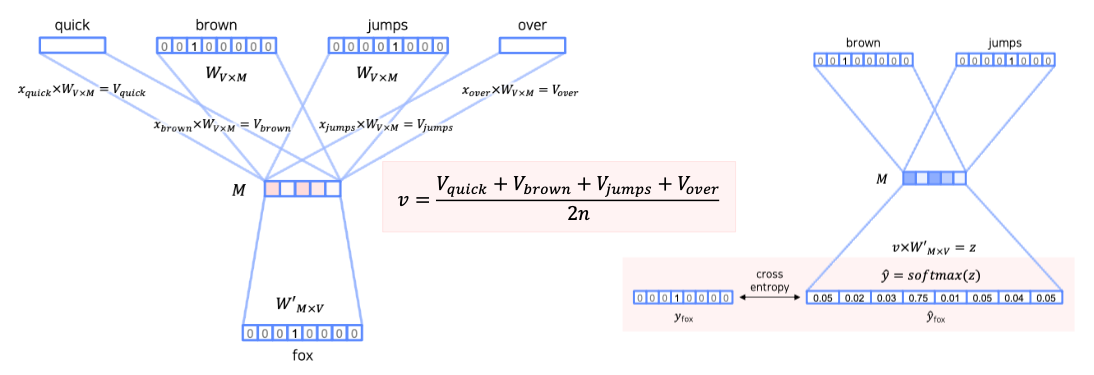
\[\begin{aligned} \text{Embedding:} & & x_{brown} \times W_{V\times M} = V_{brown} \qquad\qquad\quad \\\\ \text{hidden layer:} & & v_i = \frac{V_{i-n} + V_{i-n+1} + \cdots + V_{i-1} + V_{i+1} + \cdots + V_{i + n}}{2n} \\\\ \text{output:} & & z = v_i \times W'_{M\times V} \; \rightarrow \; \hat{y} = softmax(z) \qquad\qquad \end{aligned}\]
- 학습에 사용되는 단어들을 우선 one-hot encoding으로 표현
- input dimension $\rightarrow$ embedding dimension으로 임베딩
- 주변부 2n개의 단어 임베딩 결과를 평균내어 hidden layer에 전달
- 최종 결과는 실제 one-hot encoding과 output의 softmax 결과의 오차를 계산해서 학습
Skip-Gram
![]()
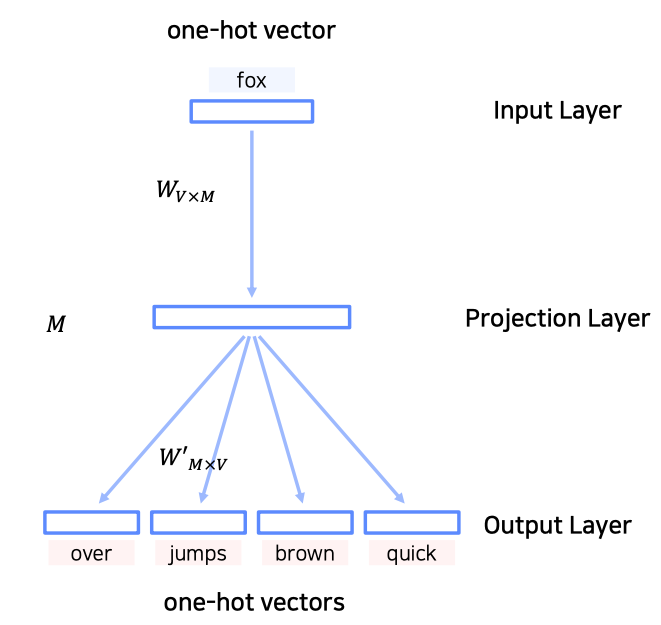
- 컨셉은 CBOW의 입력과 출력을 뒤집은 형태
- 중심 단어로부터 주변부 단어들을 예측하는 multi-class classification 모델
- output 결과는 ${ \text{center word}, n \text{ window words} }$
- 여기서 Skip-Gram의 문제점은 주변에 존재하는 word 위주로만 학습하기 때문에 overfitting의 위험성이 존재함
- 이 문제를 해결하고자 일부러 주변부에 속하지 않는 단어를 일부 sampling하는 negative sampling 방식을 적용
Skip-Gram Negative Sampling (SGNS)
![]()
- SGNS에 사용되는 하이퍼파라미터에는 positive sample 1개당 몇개의 negative sample을 생성할지를 결정하는 k가 있음
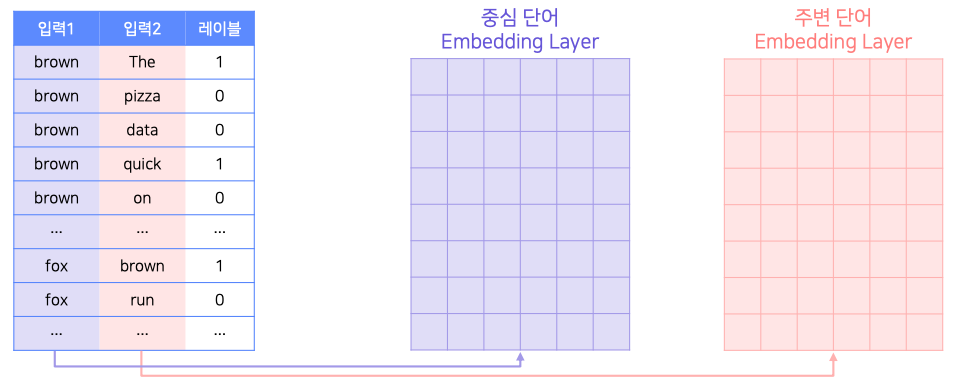
- 중심단어와 주변단어는 서로 다른 lookup table(Embedding Matrix)에 임베딩함
- 두 Embedding Matrix는 반드시 동일 차원이어야 함
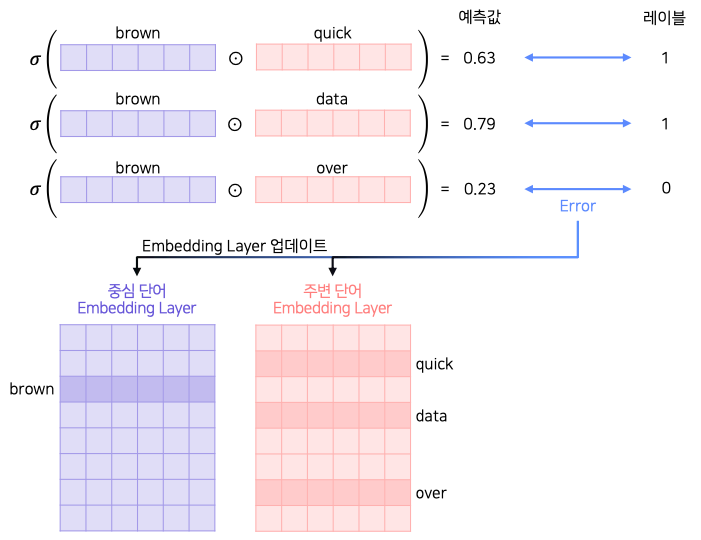
![]()
- 각 Embeddng matrix에서 중심 단어와 주변 단어의 lookup table들을 가져와서 내적과 sigmoid를 통해 레이블을 binary로 분류
- 두 값의 차이를 통해 error를 연산하고 각각의 embedding layer를 업데이트
- 둘 중 1개만 쓰거나 둘의 평균치를 활용
Item2Vec
![]()
- SGNS 아이디어에서 착안한 item-based CF에 word2vec에 적용한 논문
- 핵심 아이디어는 SGNS라 SGNS의 아이디어와 동일
- 유저가 소비한 아이템 리스트를 문장으로 설정하고 각 아이템을 단어로 가정하고 Word2Vec을 적용
- 유저-아이템 관계를 사용하지 않으므로 유저를 별도로 식별하지는 않음
- 이 말은 다시 말하면 비로그인 상태의 추천인 세션단위 추천이 가능
- Item2Vec의 목표는 SGNS 기반의 아이디어를 활용하여 아이템을 vector화하여 vector space에 배치하는 것
- 소비 아이템 집합을 생성하여 사용하기 때문에 공간/시간적 정보는 존재하지 않음
\[\frac{1}{K}\sum_{i=1}^{K}\sum_{-n\leq j < n, j \neq 0} \log p(w_{i+j} | w_{i}) \quad \rightarrow \quad \frac{1}{K}\sum_{i=1}^{K}\sum_{j \neq i}^{K} \log p(w_{j} | w_{i})\]
- 집합관계를 사용하므로 동일 아이템 집합은 Positivie Sample로 설정됨
- Skip-Gram은 앞뒤 window n개를 참고하지만 Item2Vec은 모든 아이템 쌍을 활용함
- 같은 아이템은 제외함 (center word와 center word가 굳이 관계를 구할 필요는….)
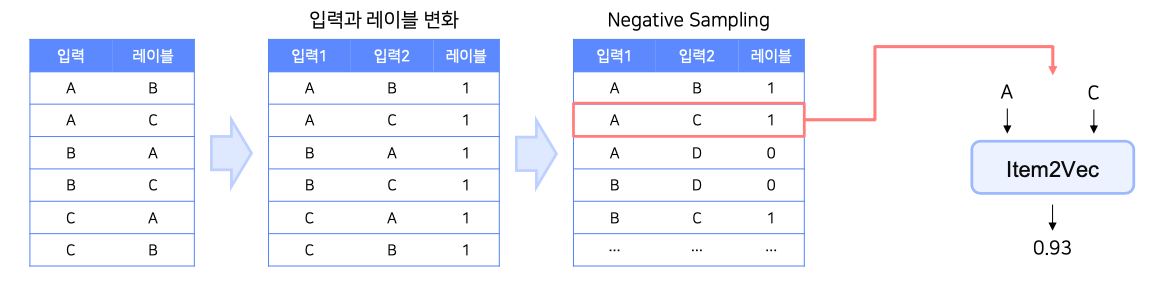
예시를 통한 이해
![]()
- 동일 세션 유저가 A, C, B 아이템을 소비한 상황
- 아이템 집합 {A, B, C}
$\rightarrow$ Word2Vec 데이터 [A, B, 1], [A, C, 1], [B, C, 1] , [B, A, 1] , [C, A, 1], [C, B, 1] - 이렇게 생성된 테이블에 Neagtive Sampling 진행
- SGNS처럼 동일 집합내의 임베딩 정보를 추출해서 Item2Vec에 넣어서 처리


Comments powered by Disqus.