
P Stage 1 : Project Day 2
Day 2 list
- 깃허브 README 실험기록 자동화 코드 수행
- F1Score scoring 코드 추가
- baseline model 기본 하이퍼파라미터 제출
깃허브 README 자동화
요약
- 부캠에서 제공해준 팀 프로젝트용 깃허브에 각자 폴더를 만들어서 실험 진행하기로 함
- 하나하나 기록값을 README에 적는 것은 효율 떨어진다고 판단
- 실험 종료 후 자동 기록 코드를 설정하여 실험 기록 자동화 진행
자세한 이야기
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
def record_expr(model, model_name, best_train_loss, avg_val_loss, avg_val_score, best_val_f1, args):
# | Date | model_name | best_loss | avg val loss | avg val f1 score | best f1 | Hyperparameters |
current_time = datetime.now(pytz.timezone('Asia/Seoul'))
base_url = '/opt/ml'
model_state_save_path = base_url+f'/level1-image-classification-level1-recsys-12/polar/model_state/' \
f'{model_name}_{current_time.month}{current_time.day}_' \
f'{current_time.hour}{current_time.minute}.pt'
markdown_path = base_url+'/level1-image-classification-level1-recsys-12/polar/README.md'
non_list = ['name', 'mode', 'save']
hypers = {k: v for k, v in vars(args).items() if k not in non_list}
current_time = current_time.strftime("%Y-%m-%d %H:%M:%S")
os.system(f"echo '|{current_time}|{model_name}|{best_train_loss:.3g}|{avg_val_loss:.3g}|{avg_val_loss:.3g}|\
{avg_val_score:.3g}|{best_val_f1:.3g}|{str(hypers)}|' >> {markdown_path}")
print("Save the experiment complete!")
이전에 학교 문해기 수업에서 매번 주어진 테스트 케이스 확인하기 귀찮아서 풀이 C++ 파일이름을 양식에 맞춰서 argument에 입력하면 채점해주는 프로그램을 만든 적이 있습니다.
당시에 os.system을 사용하면 파이썬 코드에서 콘솔로 명령어를 수행할 수 있다는 것을 배웠는데, 이를 활용해서 특정 출력을 README에 기록하는 방식으로 코드를 작성했습니다.
우선 대부분의 파일은 utils.py로 따로 빼서 관리를 진행했기 때문에 utils.py에 관련 메서드를 작성했습니다. (위 코드)
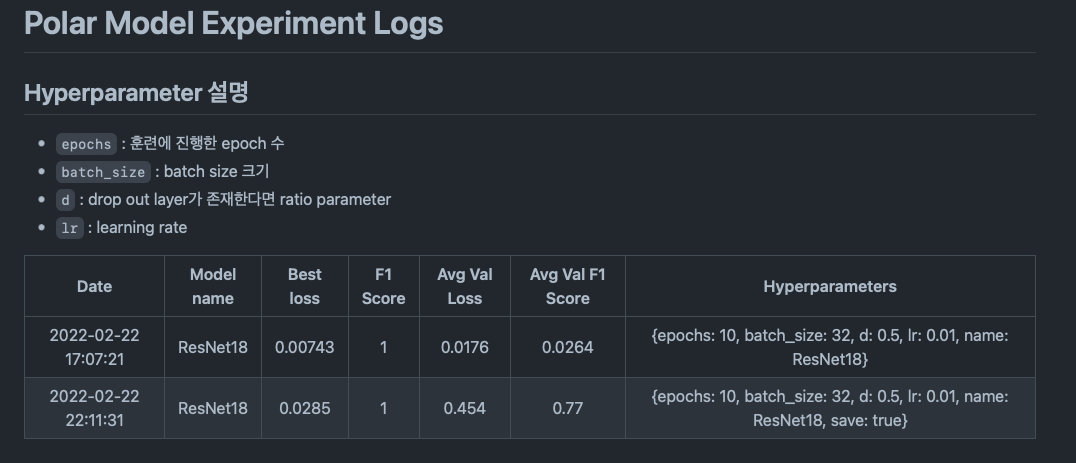
그림처럼 표로 작성하는 것이 좋을 것 같아서 상위 컬럼틀만 만들고 최하단에 표 내용을 채우는 방식을 사용했습니다.
1
2
3
4
5
6
7
def main(args):
...
if args.save.lower() == "true":
record_expr(best_model, args.name, prev_loss, val_loss, val_f1, f1_best, args)
if args.mode == "test":
test(best_model, device)
대충 훈련이 다 돌아가고 인자로 받는 값 중 -s 또는 --save가 true면 관련 함수를 동작하여 값을 자동기록합니다.
F1Score scoring 코드 추가
요약
- 이번 대회의 평가지표는 macro F1 score
- 일반적으로 sci-kit learn의
f1_score을 사용하지만 번거로우므로 다른거 찾아봄 - torchmetrics를 알게되어 설치해서 세팅함
- 일반적으로 sci-kit learn의
자세한 이야기
1
2
3
4
def main(args):
...
f1_score = F1Score(num_classes=18, average="macro").to(device)
...
이번 대회에서는 multi-class에 대한 F1 score가 평가지표입니다. 따라서 단순 accuracy를 사용하면 안됩니다. 이에 f1 score 기록 방법을 찾다가 sci-kit learn보다는 pytorch와 관련된 형식으로 일치하기로 결정했습니다.
자료를 찾던 중 torchmetics를 발견해서 사용했는데 매우 편했습니다. 나름 토치쓰면 강추
baseline model 기본 하이퍼파라미터 제출
요약
- Day 1에 작성한 ResNet18 베이스라인 코드 제출해봄
- 기대를 안하긴했는데 역시나 그렇게 좋진않았음
- valid f1 0.78 이었는데 실제 test f1은 0.5정도로 나옴
- 대략 validation과 오차 0.2정도 차이
Day 2 분석
- 일단 아무것도 처리하지 않은 상태에서 진행했으므로 좋은 성능이 안 나올 것은 예상
- EDA 결과 imbalance가 심해서 관련 data augmentation 진행해야 할 듯
- 내 EDA 짱임~ (Upvote 많음! - 이러니까 캐글도 EDA 많이 해보고프다)
- 이미지도 PCA나 임베딩으로 클러스터링 가능하진 확인해보고 싶음
- 다른 pre-trained를 써보고 결과 확인하기
- GPU 사용이 좀 떨어지는거 같은데 GPU 사용율 체크 해보기
Comments powered by Disqus.