
DL Basic : Transformer
Transformer

- 2017년 NIPS에 올라온 구글 개발진의 논문 “Attention Is All You Need” 에 등장
- sequence-to-sequence 처리 모델 (번역 case model)
- 입출력 sequence의 길이가 다름
- 입출력 sequence의 도메인이 다름
- 기존 RNN과 다르게 재귀구조를 사용하지 않고 attention을 사용
- 입력이 시간 순에 따른 순차적인 형태가 아닌 한번에 데이터가 들어옴
- 인코더, 디코더 구조로 구성
- 기본 구조는 Self-Attentio $\rightarrow$ Feed Forward NN
Transformer 원리

- 기본적인 원리는 n개의 $x$에서 n개의 $z$를 찾을 때 (x는 번역 전, z는 번역 후) $x_i \rightarrow z_i$에서 n-1개의 $x$를 같이 고려함
- 좀 더 직관적인 이해는 vector space에 뿌려져있는 단어들에 특정 단어 정보가 들어오면 vector space의 단어들 중 어떤 단어와 더 가까운지를 확인
- 이 과정에서 일종의 내분점아이디어가 도입
- 이후 특정 점 K에 대해 mapping된 V를 통해 다른 vector space로 mapping이 가능
문장 임베딩

- 입력으로 들어온 문장을 단어단위로 분리하고 임베딩
Q, K, V vector

- 각 임베딩된 단어에 대해 Q, K, V 벡터를 생성
- 각 X에 대해 Q, K, V를 찾아주는 MLP가 존재
- Q 벡터는 단어의 query 정보, K 벡터는 단어의 vector space 상의 위치, V는 각 단어의 value vector
Scaled-dot-product attention

- 처리하는 단어의 Query vector와 모든 Key vector의 내적을 진행하고 Key vector의 dimension인 $d_k$의 제곱근으로 나눠주며 scaling을 진행
- 이렇게 나온 값을 attention score라고 함
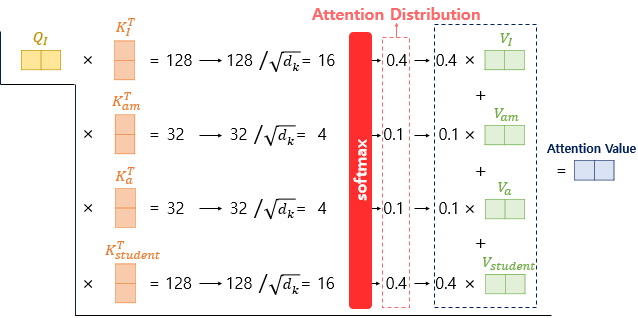
- 이후 결과값에 softmax 함수를 처리
- 이후 각 Key vector에 해당하는 Value vector를 곱해주고 합을 진행
- 이 과정은 softmax의 특성상 내분점 연산과 비슷한 효과가 나타남
- 최종 결과가 Attention Value가 됨
행렬 연산으로 일괄처리

- 각 Q에 대해 scaled-dot 연산을 진행하였지만 실제론 행렬 연산으로 한번에 처리 가능
Multi-head attention (MHA)

- MHA는 head를 여러개를 만들어서 병렬적 연산을 수행하는 것
- 이는 attention 연산 특성상 행렬의 크기가 너무 커지기 때문
- 동시에 attention이 가능하기 때문에 다른 단어들과의 연관성을 한번에 볼 수 있음
Comments powered by Disqus.