
DL Basic : Introcution & Historical Review
딥러닝의 기본요소
- Data
- 데이터는 “어떤 문제를 해결할 것인가?”에 따라 형식이 달라짐
- Model
- 모델의 성질에 따라 동일한 데이터라도 다른 성능을 보인다.
- 심지어 같은 task를 해결하기 위해서도 모델에 쓰이는 Technique들이 다양하다.
- Loss Function
- 모델과 데이터가 정해졌을 때 어떻게 모델을 학습할 지를 결정하는 요소이다.
- Neural Net의 weight 조정을 할 때 사용
MSE,CE,MLE와 같은 다양한 loss function이 있는데, 이는 문제의 유형에 맞춰 선택한다. 하지만 loss function이 줄어드는 것이 반드시 좋은 결과를 말할 수는 없다. 또한 데이터의 특성에 맞춰 loss function을 다르게 결정할 필요도 있다.
- Optimiztion Algorithm
- 위의 모든 것들이 결정된 후 네트워크를 어떻게 줄일지를 결정하는 역할을 한다.
- 1차 미분을 활용한 SGD 접근법을 활용하였지만 성능이 좋지 않아 다른 방식도 사용
Momentum,NAG,Adagrad,Adadelta,Rmsprop와 같은 방식들을 사용하게된다.- 추가적으로 regularizer들을 활용하기도 한다.
Historical Review
Denny Britz가 2020년에 발표한 Deep Learning’s Most Important Ideas - A Brief Historical Review에는 2020년까지의 주요 Deep Learning 논문들의 review가 담겨있다. 이를 간단하게 정리하겠다.
AlexNet (2012)
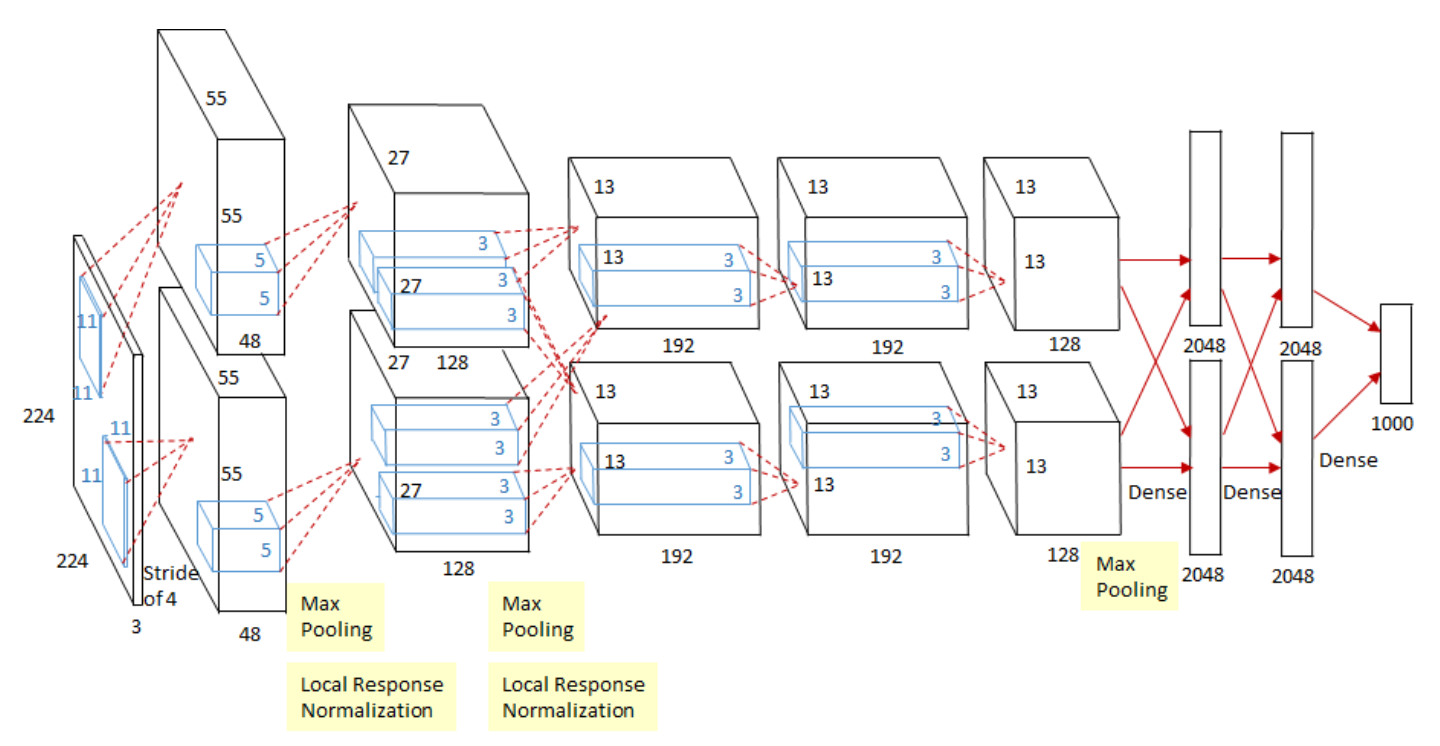
그림에서 알 수 있듯이 CNN이다. AlexNet이 탄생한 것은 224 X 224의 이미지를 분류하는 대회인 ILSVRC였다. 지금보면 왜 평범한 CNN이 딥러닝의 역사를 바꾼 것의 맨 처음을 장식하는 것일까? 라는 생각을 할 수 있는데 사실 AlexNet은 평범한 CNN은 아니었다.
AlexNet이 나오기 이전, ILSVRC의 우승 모델은 DL 기반의 모델들이 아닌 커널기반, SVM과 같은 고전방식을 활용했다. AlexNet의 등장으로 최초의 DL 모델이 우승을 차지했고 이후 대 Deep Learning 시대가 열리게 되었다.
단순히 “되겠지~”라고만 여겨지던 딥러닝이 드디어 Machine Learning에서 빛을 보이며 실력을 발휘하게 된 역사적인 사건이다.
DQN (2013)
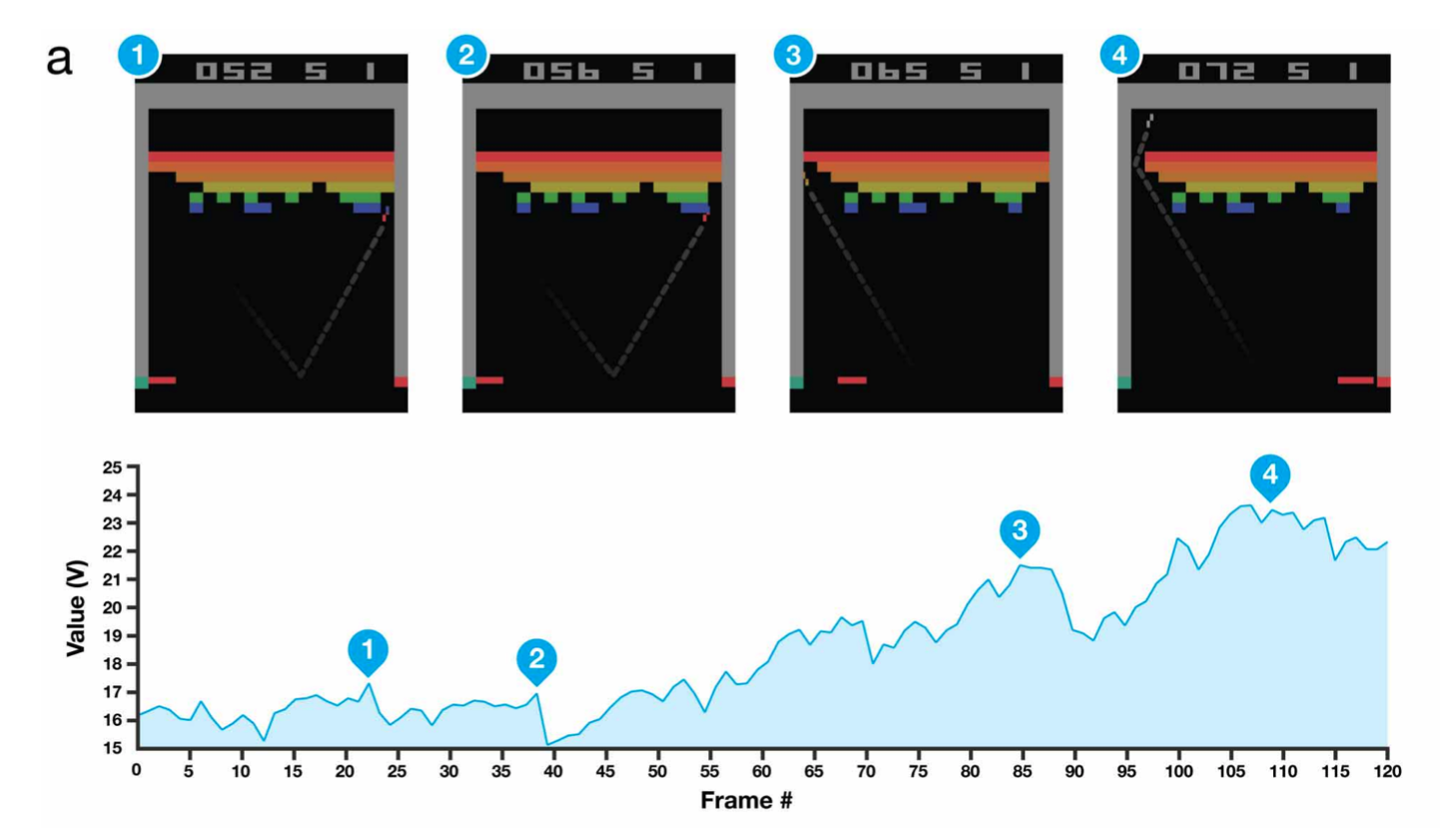
지난 2016년에 있었던 역사적인 사건인 알파고 VS 이세돌의 시작인 DQN이다. DQN은 알파고를 개발한 딥마인드의 연구결과인데, 아타리라는 블록깨기 게임을 인공지능 모델 스스로 학습을 통해 해결하는 강화학습으로 풀어낼 때 사용한 방식이다. 사실 Q-Learning이라는 방식은 이전에 사용이 되었는데 이를 deep learning과 접목시킨 방식으로 학습을 한 것이다. DQN 연구로 구글이 딥마인드를 인수했다는 설도…
Encoder / Decoder (2014)
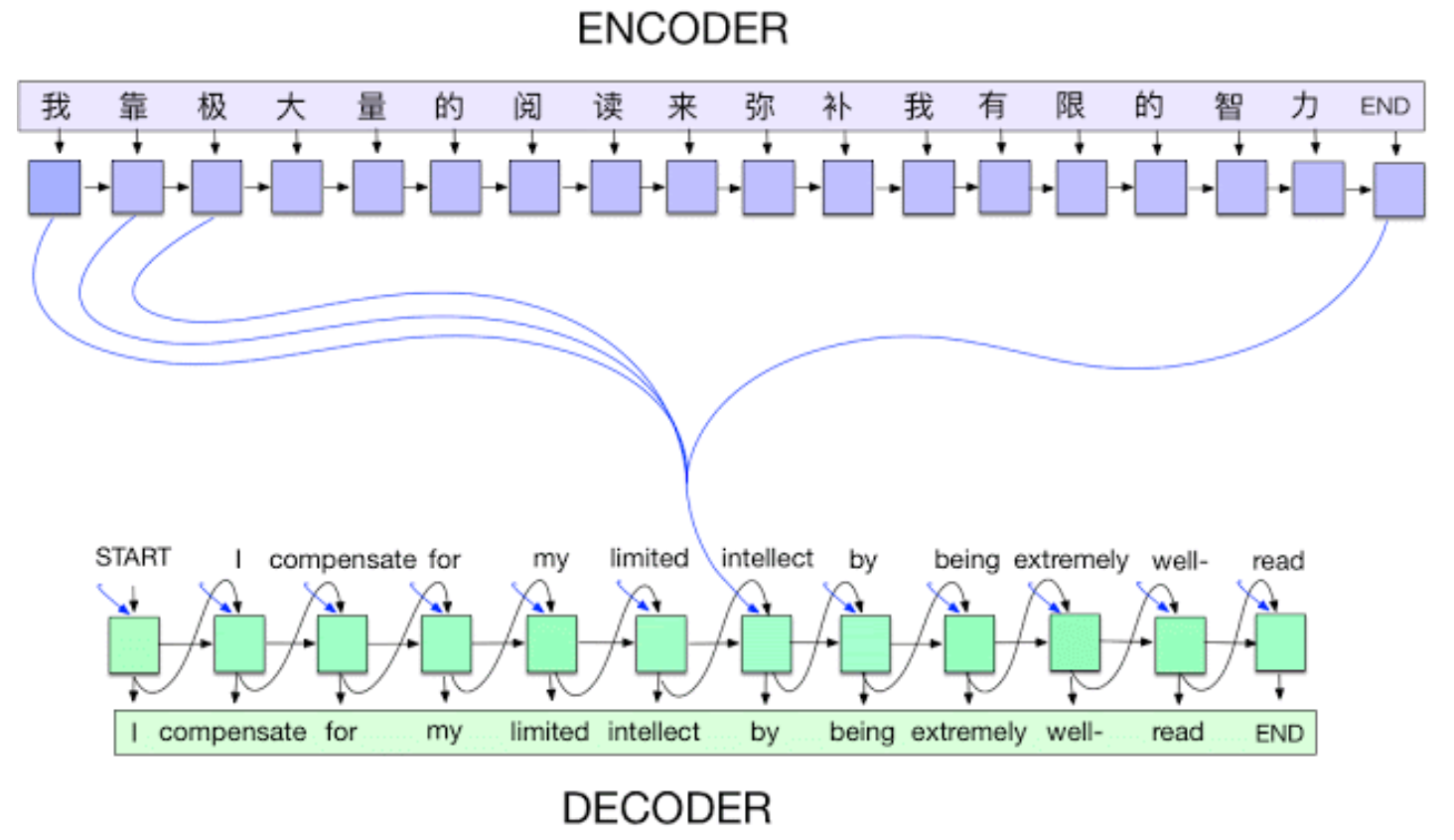
Encoder와 Decoder는 NLP에서 translation 문제를 해결하고자 나타났다. 다른 언어의 문장을 또 다른 언어의 문자으로 바꿔야하는 것이다. 즉 특정 Sequence를 다른 Sequence로 변환하는 작업을 하는 것이다. 결과적으로 Sequence-to-sequence(Seq-2-Seq)를 할 수 있게되었고 NLP분야의 발전이 일어났다.
Adam (2014)
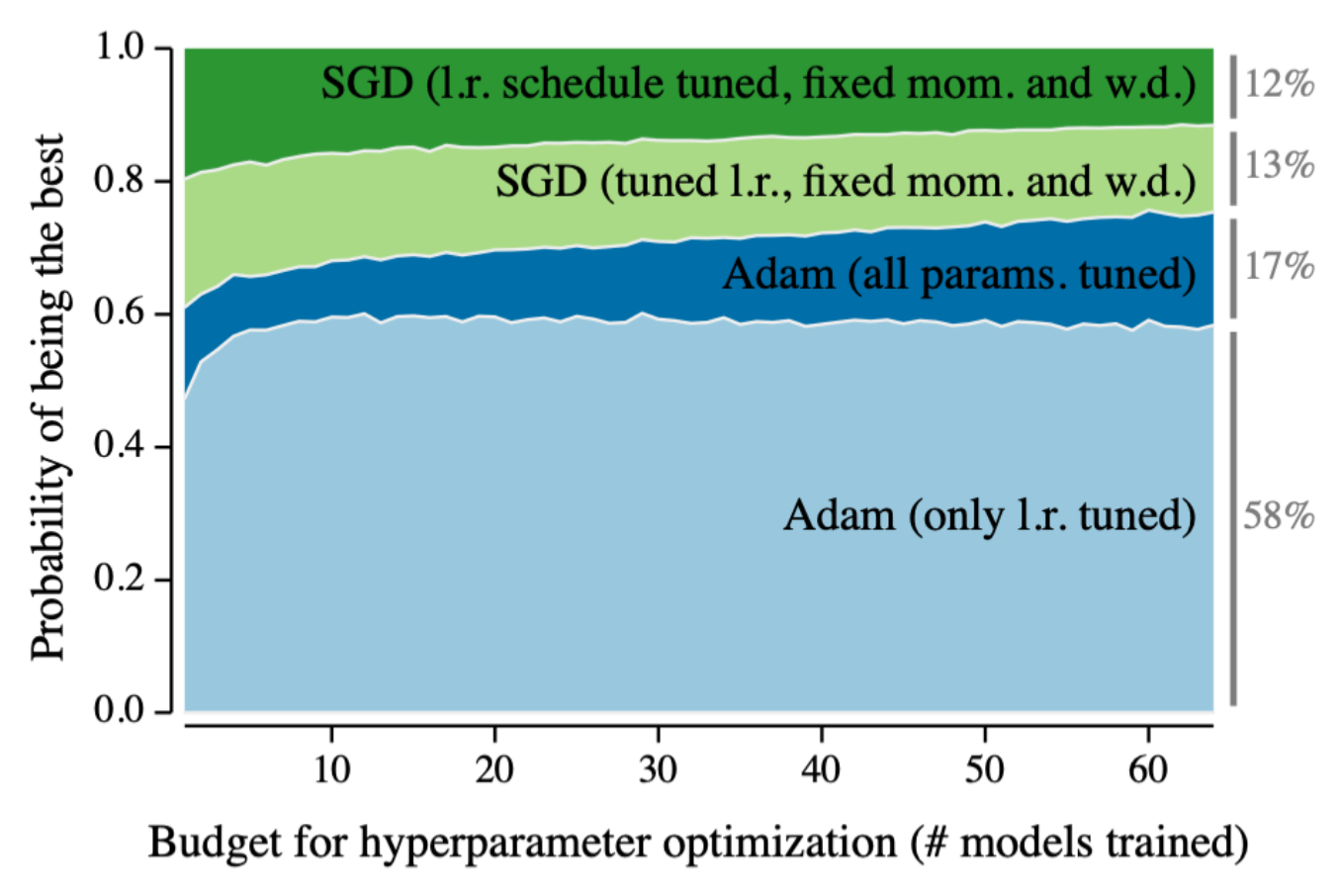
Adam이다. ML/DL을 공부하는 사람 중 과연 Adam을 한번도 못 들어는 봤어도 한번만 본 사람은 없을 것이다. 그만큼 Adam optimizer는 가장 많이 사용되는 optimizer이고 준수한 성능을 낸다. 가장 통용적으로 많이 사용되는 optimizer가 등장한 것이다.
GAN (2015)

GAN은 어떻게보면 DL에서 가장 중요한 것 중 하나라고 말할 수 있다. Network가 스스로 학습데이터를 만들어서 학습을 하게 된 것이다.
ResNet : Residual Network (2015)
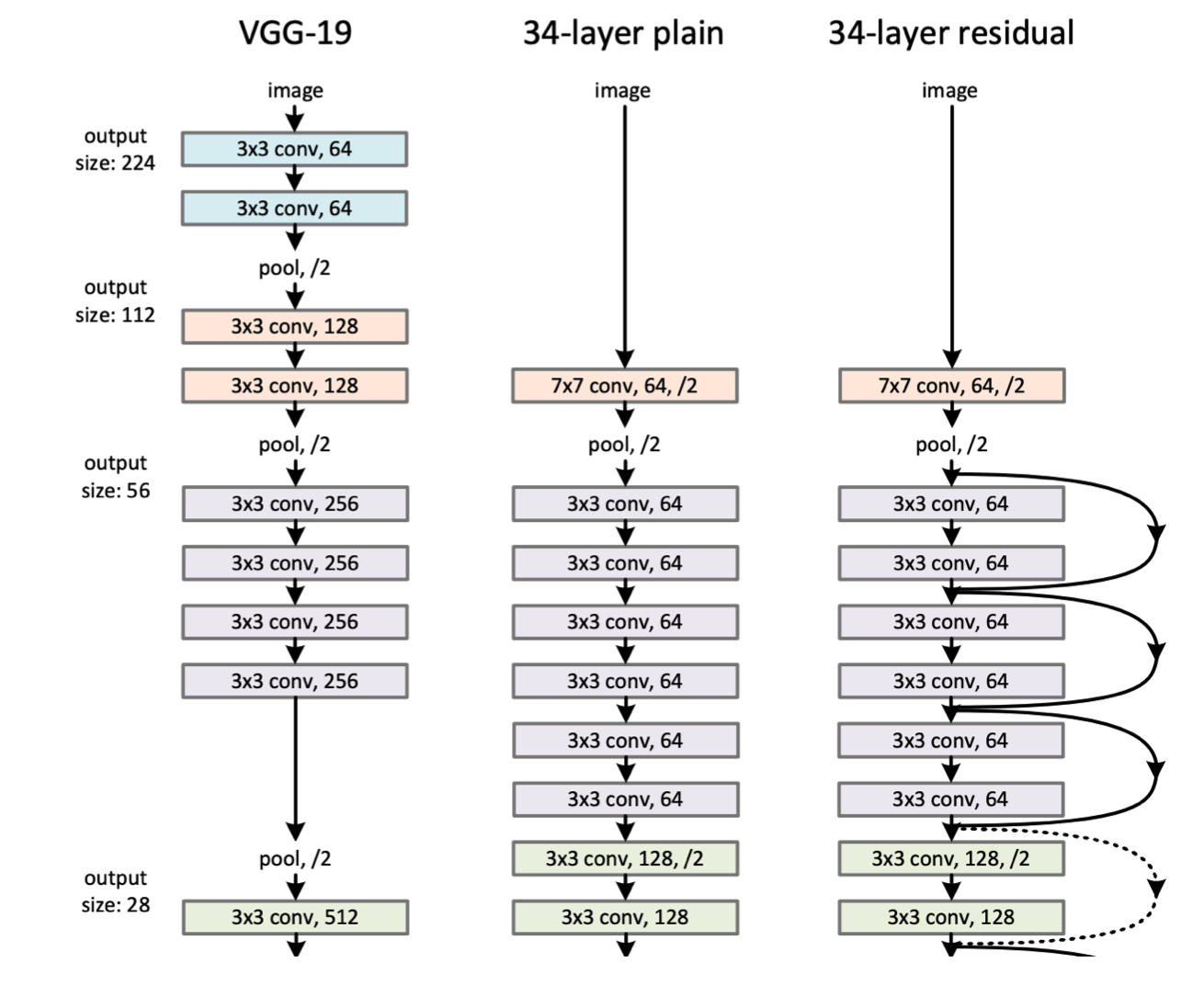
기존의 딥러닝은 많은 층의 network를 쌓게되면 오히려 성능이 떨어지게 되었다. 이름은 깊게 쌒았다는 의미의 딥러닝인데 정작 많이 쌓으면 성능이 떨어진다니… 하지만 ResNet이 나타나며 이전보다 깊은 수의 네트워크를 설정해도 overfitting이나 underfitting문제가 덜 발생하게 해주며 딥러닝이 이름 그대로의 값을 하게 되었다.
Transformer (2017)
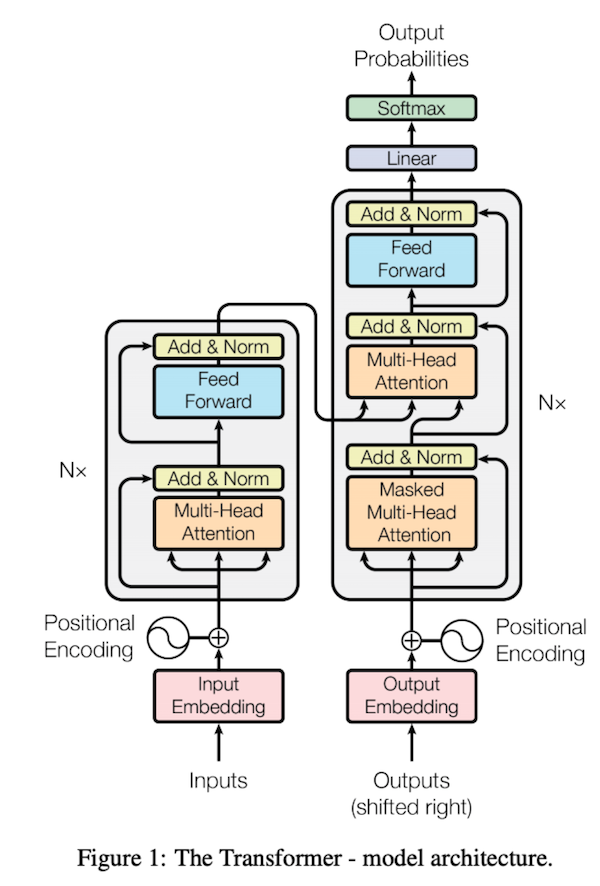
Transformer가 등장하면서 기존의 RNN의 분야에서 RNN을 대체하게되었다. 하지만 이는 겨우 시작에 불과하였고 이제는 transfomer가 다른 분야에까지 사용되면서 CV영역까지 넘어오고있다.
BERT (2018)
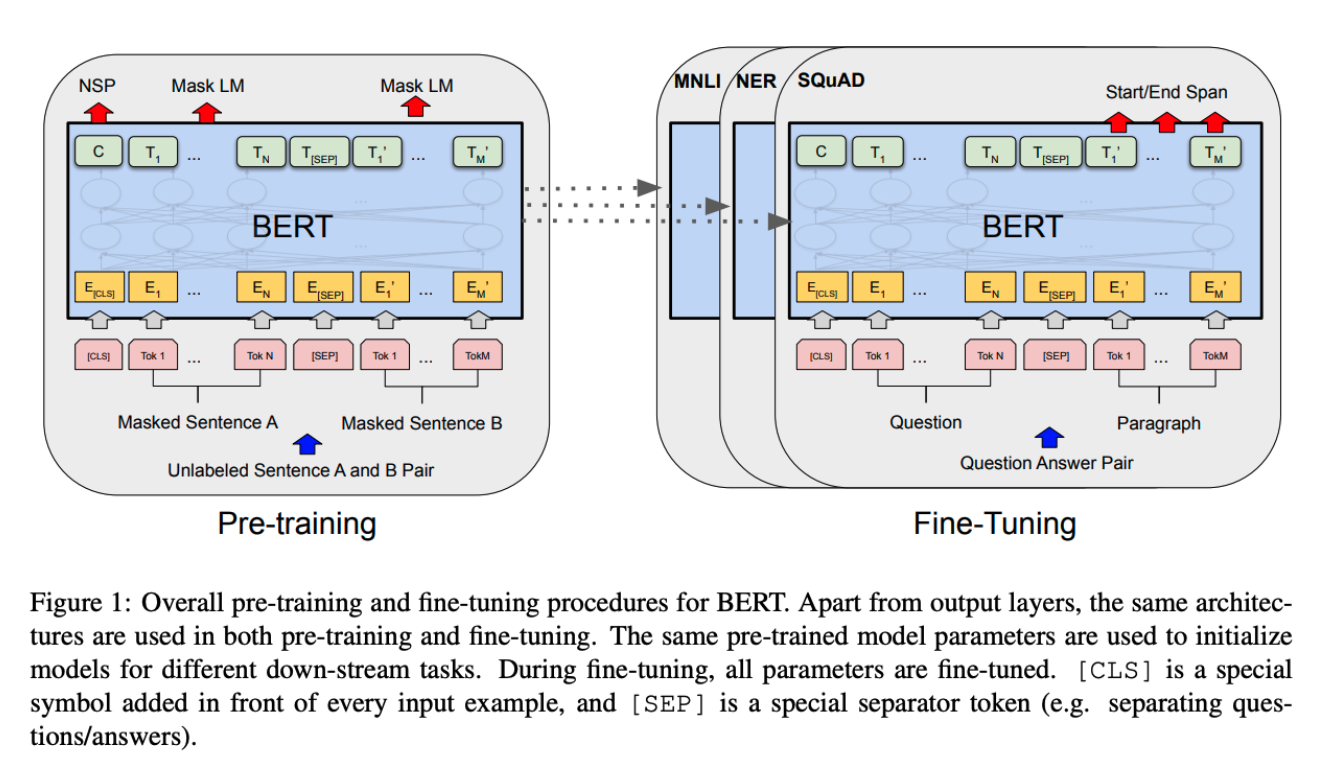
앞서서 이미지 분류(Image Classification), 강화학습(Reinforcement Learning)의 패러다임을 일으킨 연구를 알아봤다. BERT는 대표 분야 중 하나인 NLP(Natural Language Processe)의 가장 큰 패러다임 변화를 일으킨 연구이다. 많은 사람들이 NLP는 BERT 이전과 이후로 나눈다고 많이들 말하는데, 솔직히 개인적으로 써본 결과도 굉장히 압도적인 성능을 보였다.
Fine-tuned NLP model이라고 하는데, 문제해결을 위한 학습 데이터가 많지 않을 때 일반적으로 주어진 큰 규모의 corpus를 활용하여 pre-training을 진행하고 해결하고자하는 데이터를 해당 모델에 fine-tuning을 하는 것이다.
Big Language Models : GPT-X (2019)

BERT의 최종 형태라고도 하는 GPT-X이다. Big Language Model이라고 하는데, 이는 parameter 개수가 굉장히 많아서 붙어진 이름이다.
GPT-3의 등장으로 NLP의 연구는 굉장히 발전하게되었다.
Self-supervised Learning (2020)
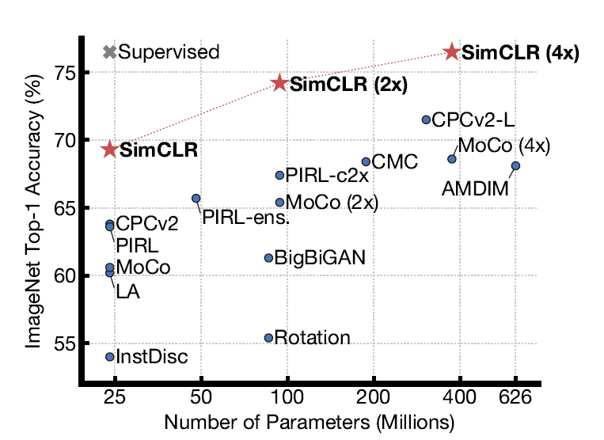
모델을 학습할 때는 라벨이 붙은 데이터를 활용하는 것이 중요하다. 하지만 이는 cost가 많이 소요되는 작업이다. 이를 해결하고자 unlabled data를 활용해서 학습에 사용하는 것이다. 하지만 unsupervised와는 다르게 모델이 스스로 label을 형성하기 때문에 self supervised learning이라고 붙었다고 한다. 이해가 맞는지 모르겠음 ㅠㅠ
Comments powered by Disqus.