
Data Viz : Matplotlib Details
Text
- 시각화 과정에서 대부분 그림을 활용하지만 글자적인 요소를 많이 활용하기도 합니다.
- 텍스트는 대신 적절하게 사용하지 못하면 오히려 시각화를 방해하는 요소로 작용할 수 있습니다.
- 인간의 신체는 기본적으로 힘을 덜 들이는 방향을 우선하게됩니다. 어느정도 답을 제시하는 시각화 자료가 아니라 머리를 써 분석을 할 필요가 있다면 그림보다는 텍스트를 우선으로 읽을 수 있기 때문입니다.
matplotlib에서 텍스트를 직접적으로 활용하는 것보다는 데이터의 수치나 제목, x/y축 값 등을 표현하는 데 많이 사용합니다.
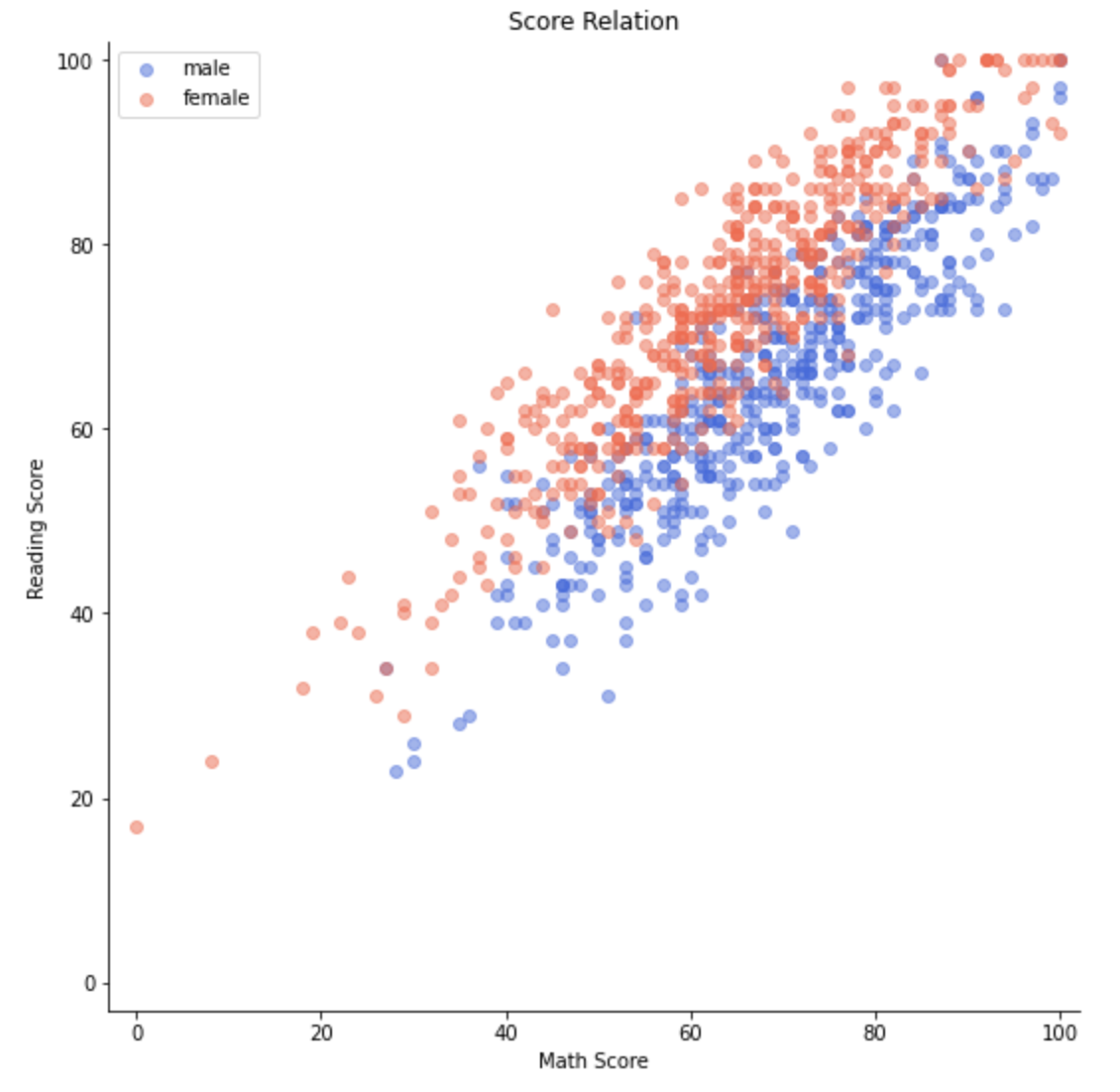
- 이 처럼 일반적으로는 축이 어떤 값을 표현하는지, 이 그래프는 어떤 것을 주제로 처리하는지를 텍스트로 작성합니다.
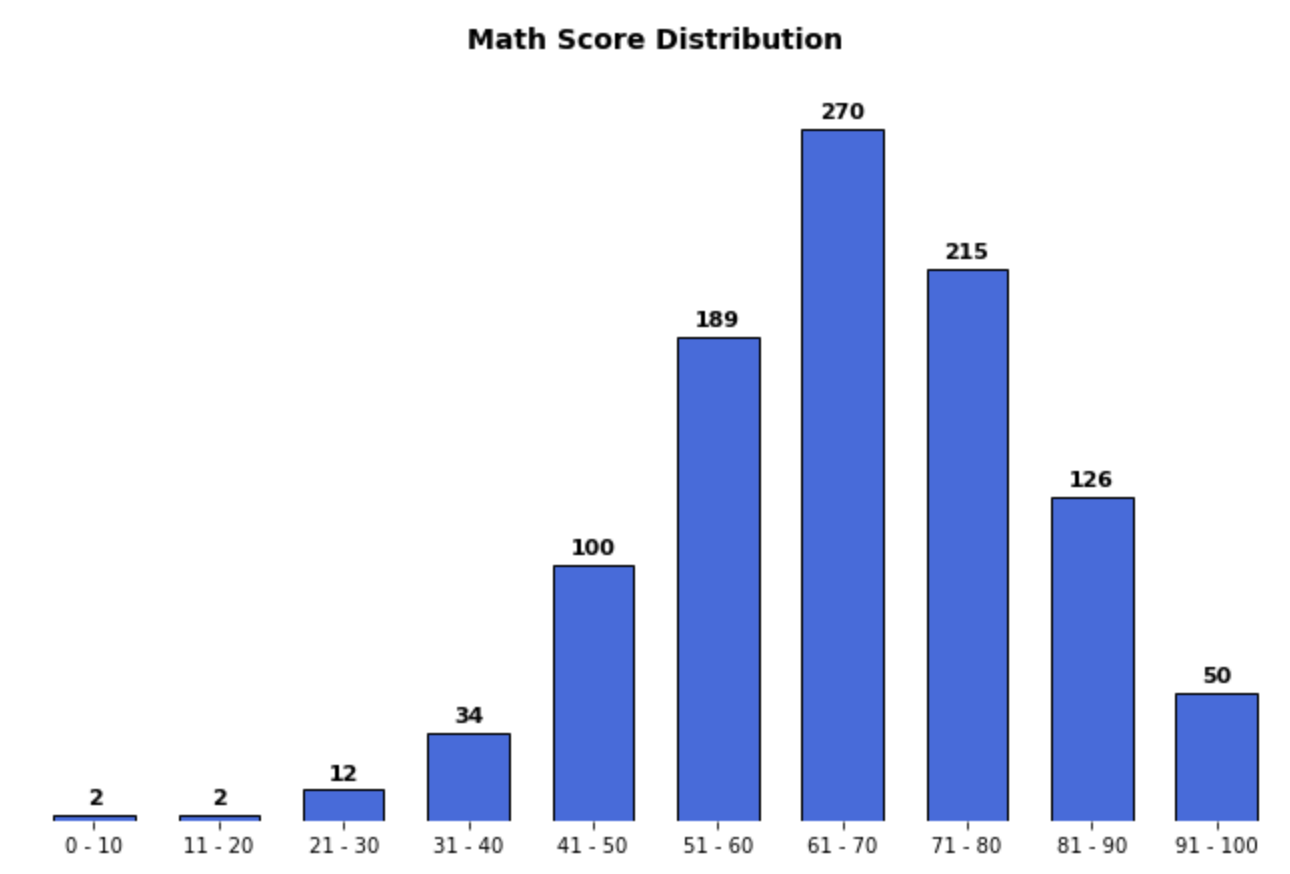
- 개인적으로도 텍스트의 사용처 중 많이 사용하는 부분이 값을 표시하는 곳입니다.
1
2
3
4
5
for idx, val in math_grade.iteritems():
ax.text(x=idx, y=val+3, s=val,
va='bottom', ha='center',
fontsize=11, fontweight='semibold'
)
- 반복문을 활용해 직접 데이터에 접근해서 x, y 좌표에 맞춰 데이터를 입력한다.
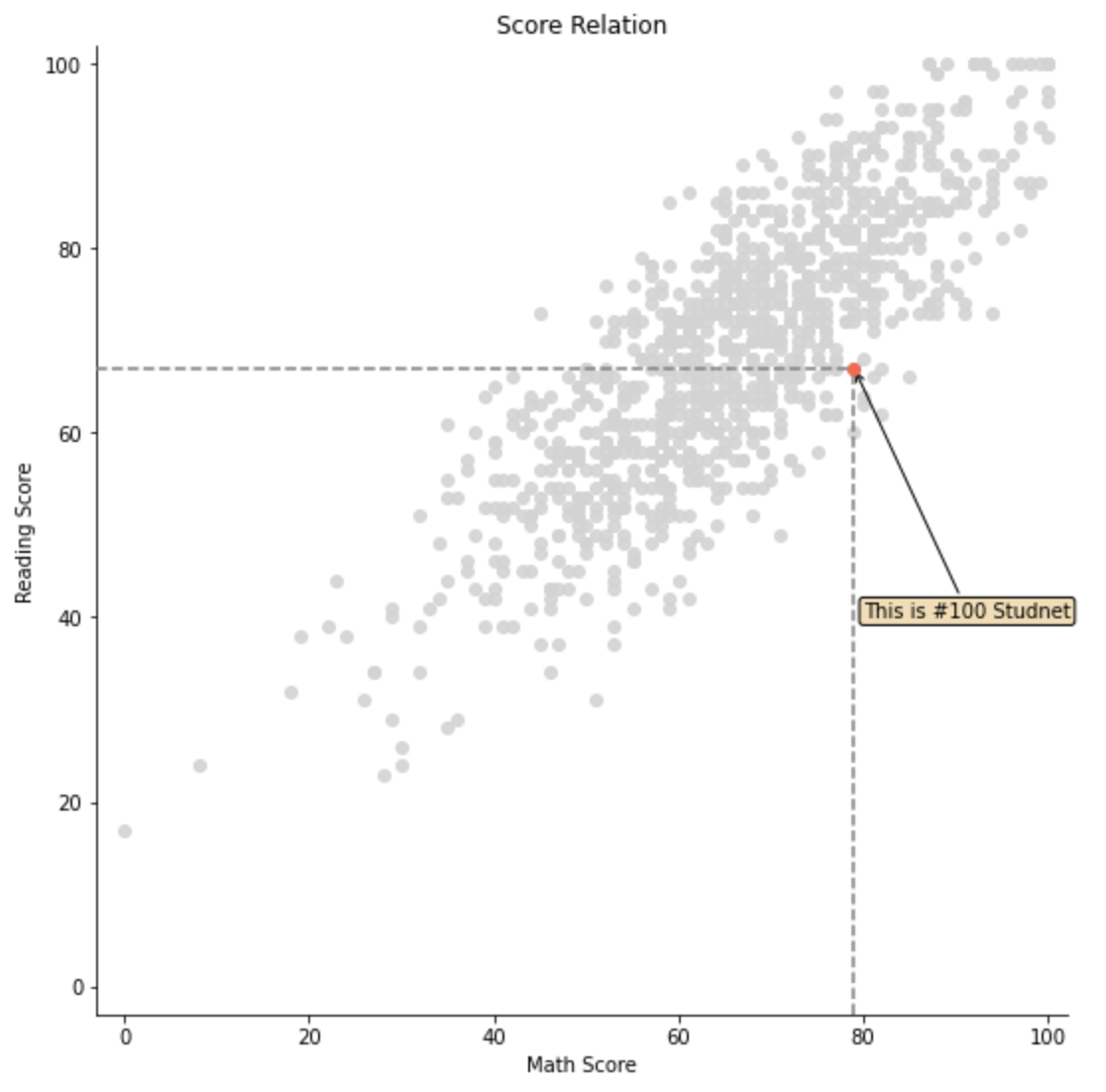
- 이처럼 특정 데이터를 지칭하는 것도 가능합니다. 이는 보통 데이터프레임의 특정 index 데이터를 가져오는 방식을 사용하여 구현합니다.
Color
- 시각화에서 물론 화려하게 표현해서 독자의 눈을 사로잡는 것이 반드시 좋은 것은 아닙니다. 색은 우리 생활에서 많은 의미를 담고 있기 때문입니다.
- 주변에서 간단하게 볼 수 있는 예시로 주식에서 빨간색은 양봉, 파란색은 음봉을 의미하는 것과 같습니다.
- 인간의 심리적 기저에 깔려있는 색상이 담고있는 의미들은 많습니다. 심지어 같은 색임에도 인간은 주제에 따라 다른 의미를 부여하기도 합니다.
이 때문에 색은 시각화에서 함부로 쓰면 안되는 요소 중 하나입니다.
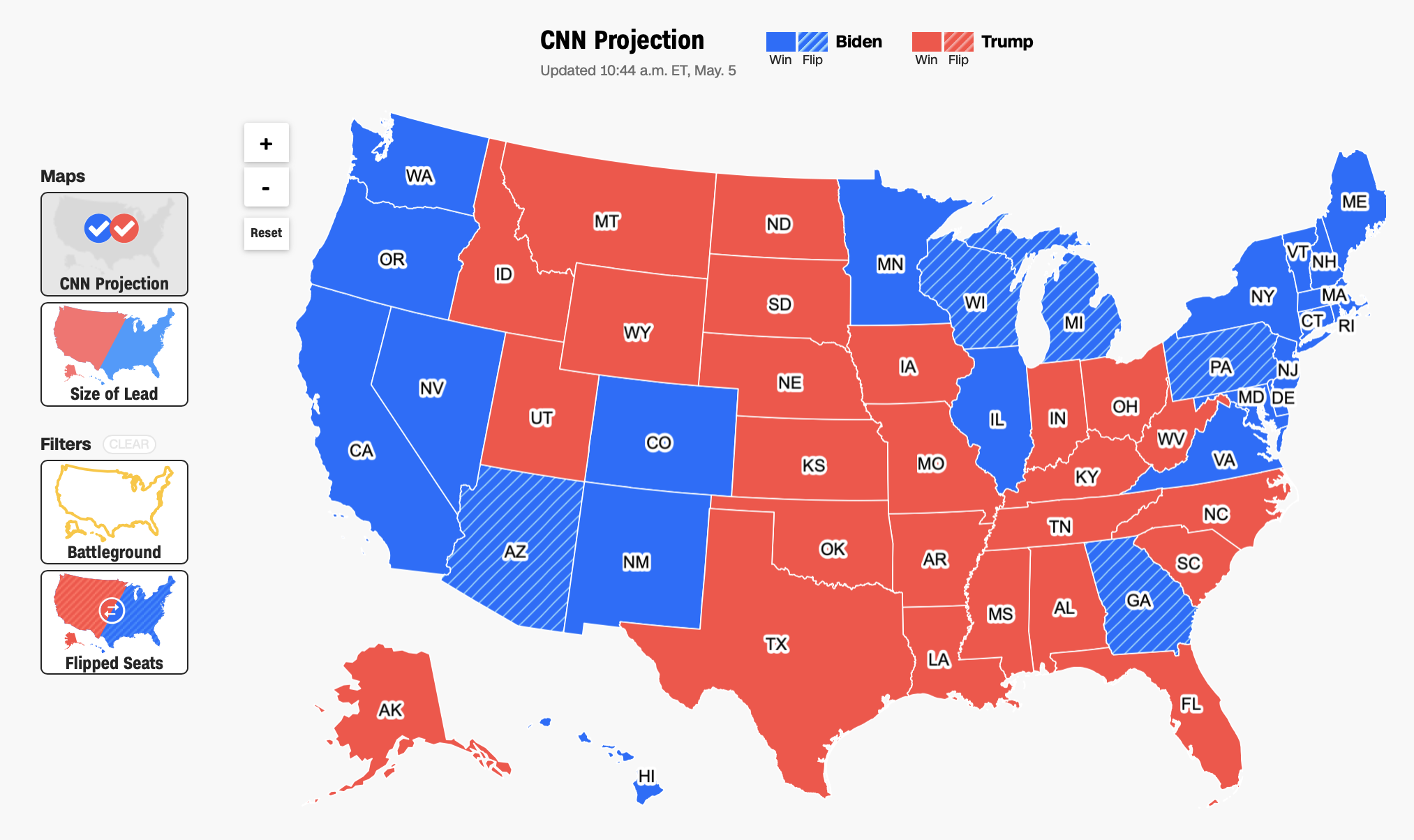 출처 : CNN https://edition.cnn.com/election/2020/results/president
출처 : CNN https://edition.cnn.com/election/2020/results/president
- 붉은색이 주식시장에서는 이익, 푸른색은 손해를 의미했지만 미국 대선 혹은 한국 대선에서는 다른 의미로 사용됩니다. 정말 신기하게도 인간은 같은 색이지만 다른 의미를 자동적으로 부여해서 해석합니다.
범주형 자료

- 색상은 다양한 컨셉으로 의미를 갖습니다. 위에서 미국 대선의 공화당과 민주당은 일종의 범주형 자료(Categorical data)입니다.
- 범주형 자료는 색상 자체에 의미를 갖지는 않습니다. 물론 상징성은 있을 수 있습니다. 하지만 그 자체가 어떤 수치를 갖지는 않기 때문에 독립적인 색상을 활용하는 것이 좋습니다.
- 색 자체가 유사한 구성을 하는 것보다는 색이 뚜렷하게 구분이 되는 것을 고르는 것이 중요합니다.
연속형 자료

- 정렬된 값을 가지는 순서형, 연속형 변수에 적합합니다.
- 배경색의 기준에 맞춰 큰 값이 변경되는데, 일반적으로 어두운 배경에는 밝은색이, 밝은 배경에는 어두운색이 큰 값을 의미합니다.
- 연속형 자료는 색상의 밝기가 곧 데이터의 강세를 의미하므로 단일 색조로 표현하는 것이 좋습니다.
발산형 자료

- 발산형 자료는 연속형과 매우 유사하지만 중앙을 기준으로 데이터의 수치가 발산합니다.
- 기온, 지지율과 같은 상극의 값에 대한 비율적 지표를 나타내는 시각화에 효과적인 색상 지표입니다.
Grid
- Grid는 데이터를 확인하는 것의 보조 자료로 사용하기 좋습니다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
x = np.random.random(25)
y = np.random.random(25)
fig, ax = plt.subplots(1, 1, figsize=(5, 5))
plt.scatter(x, y)
ax.grid()
ax.spines['right'].set_visible(False)
ax.spines['top'].set_visible(False)
ax.set_xlim([0, 1.2])
ax.set_ylim([0, 1.2])
plt.tilte('Grid')
plt.show())
- Grid는 다양한 형태로 표현할 수 있습니다. 이를 활용하면 다양한 데이터를 표현할 수 있습니다.
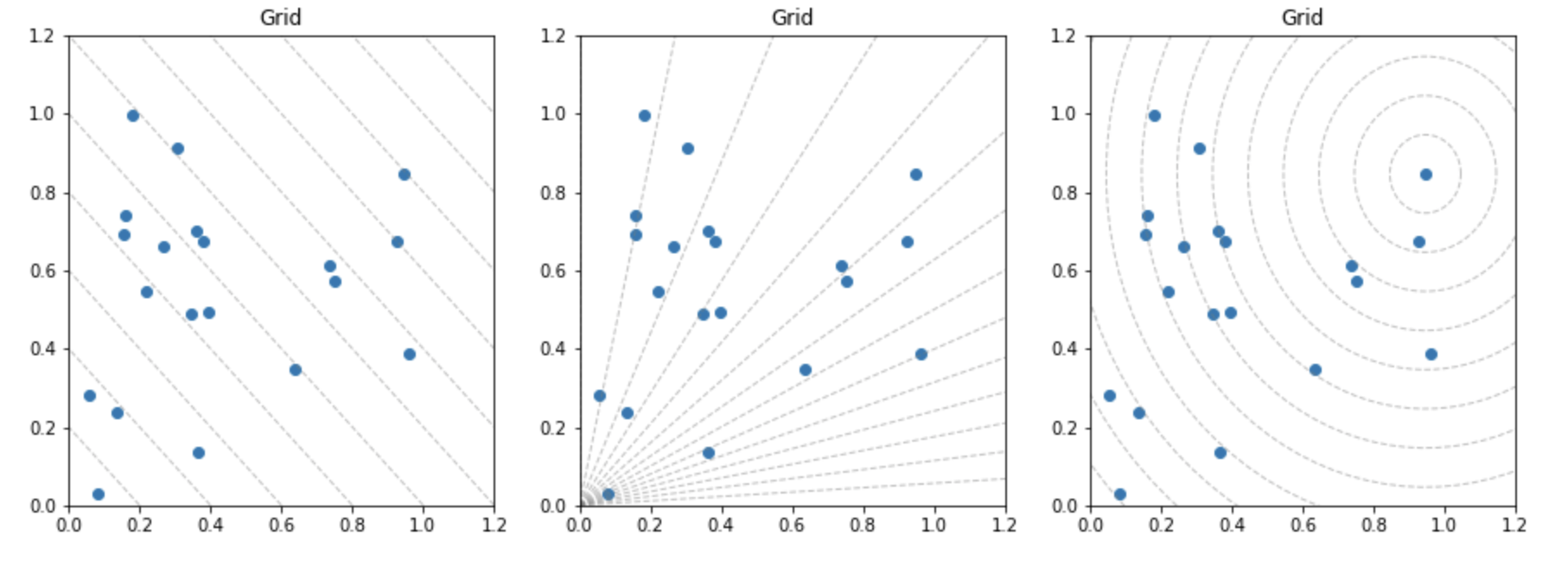
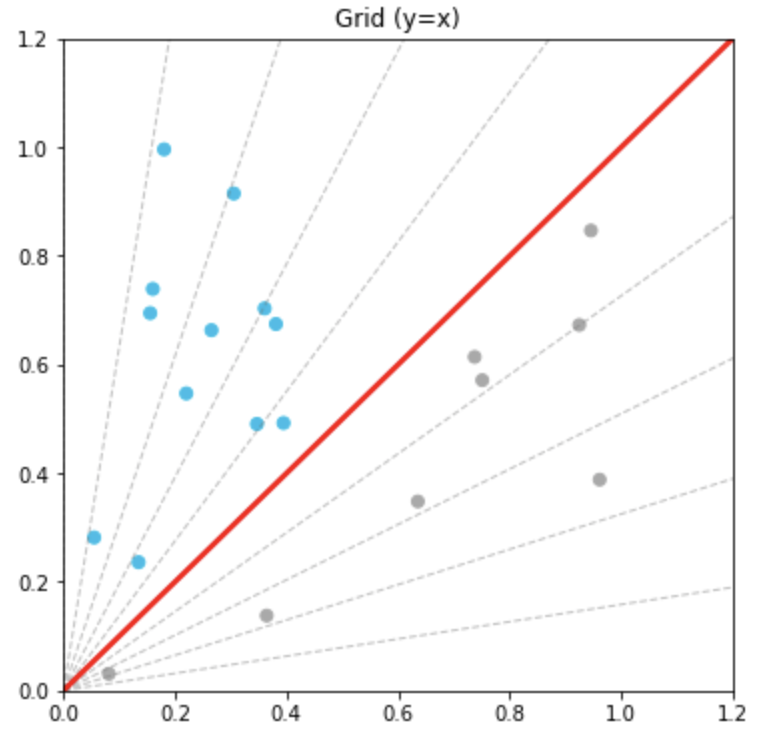
- 이처럼 특정 데이터들의 분류 군집화를 표시하는 방법도 가능합니다.
Comments powered by Disqus.