
Data Viz : Basic Plots
Matplotlib

matplotlib은 데이터 시각화에 가장 보편적으로 사용되는 라이브러리이다. 기존에 수학/통계에서 많이 사용하는 MATLAB에서 아이디어를 따왔다는 것으로 알려져있다. numpy, scipy와 같은 다양한 라이브러리와의 호환이 좋고 가장 많이 같이 사용되는 라이브러리는 pandas가 아닐까 싶다.
최근에는 단순히 matplotlib만 사용하는 것이 아닌 확장버전인 seaborn과 plotly를 많이 사용하는 추세다.
1
2
import matplotlib as mpl
import matplotlib.pyplot as plt
matplotlib은 alias gudxofh mpl을 사용하고 가장 많이 사용되는 모듈은 pyplot으로 alias는 plt로 많이 활용한다.
1
2
3
4
5
6
7
8
9
10
11
x1 = [1, 2, 3]
x2 = [3, 2, 1]
fig = plt.figure(figsize=(12, 7))
ax1 = fig.add_subplot(211)
ax2 = fig.add_subplot(212)
ax1.plot(x1)
ax2.plot(x2)
plt.show()
add_subplot()을 활용해서 plot들을 생성하는 방식을 사용하는 것이 기본 방식이다. 하지만 개인적으로 가장 많이 사용하는 방법은 plt.subplots(row, col, figsize=(r,c))를 사용하는 방법이다.
1
2
fig, axes = plt.subplots(2, 2, figsize=(7, 7))
plt.show()
이 방법을 사용하면 axes에는 배열 형태로 plot의 위치가 주어지기 때문에 굳이 add_subplot을 하지 않아도 직접적으로 plot에 접근이 가능하다. 보통 seaborn과의 혼용에서 많이 사용하는 방법이다.
Bar plot
Bar Plot은 우리가 자주 접하는 그래프 중 하나인 막대 그래프를 의미한다. 보통 범주형(Categorical) 자료를 비교할 때 많이 사용하는 그래프이다.
막대 그래프를 표현하는 방식은 보통 plot을 여러개를 그리는 방식이 데이터를 직관적으로 바라보기 편리하다. 때로 일부 데이터에 한해서는 비율을 나타내는 Percentage Stacked Bar Chart를 사용하기도 한다.
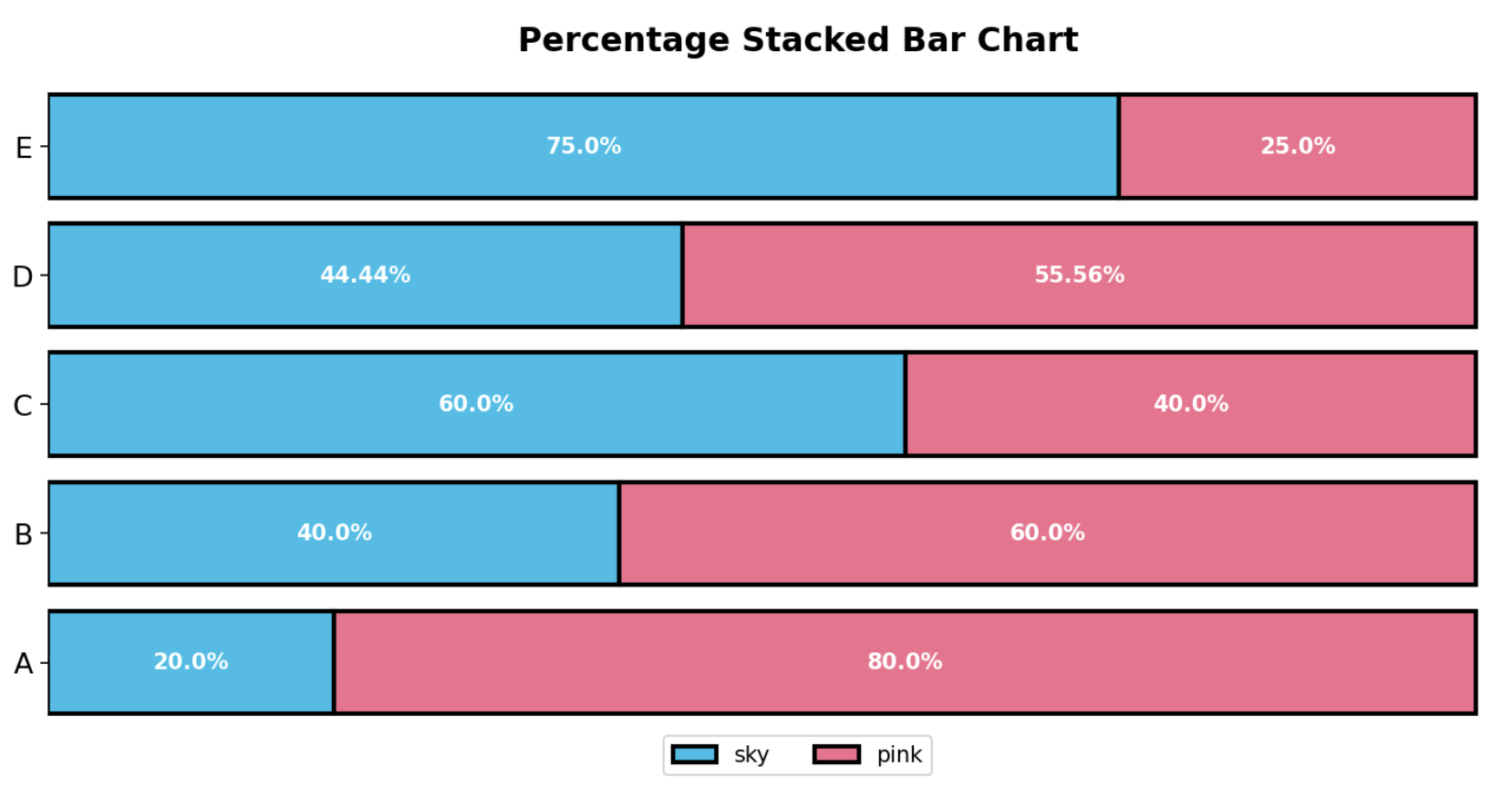
bar plot을 단순히 matplotlib 혼자서 쓰기에는 여러가지 테크닉을 적용하기에 어려움이 존재한다. 따라서 seaborn과 같이 사용해서 좀 더 다양한 테크닉을 적용한다.
Principle of Proportion Ink
The representation of numbers, as physically measured on the surface of the graphic itself, should be directly proportional to the numerical quantities represented.
실제 값과 그에 표현되는 그래픽으로 표현되는 잉크 양은 비례해야 한다. bar plot은 기본적으로 데이터의 정량적인 크기를 주요하게 나타내야한다. 따라서 반드시 x축 값의 시작은 0에서 시작해야한다. 사실 이는 막대 그래프에만 적용되는 것은 아니다. 정량적인 지표를 표현해야하는 case에는 반드시 고려해야하는 내용이다.
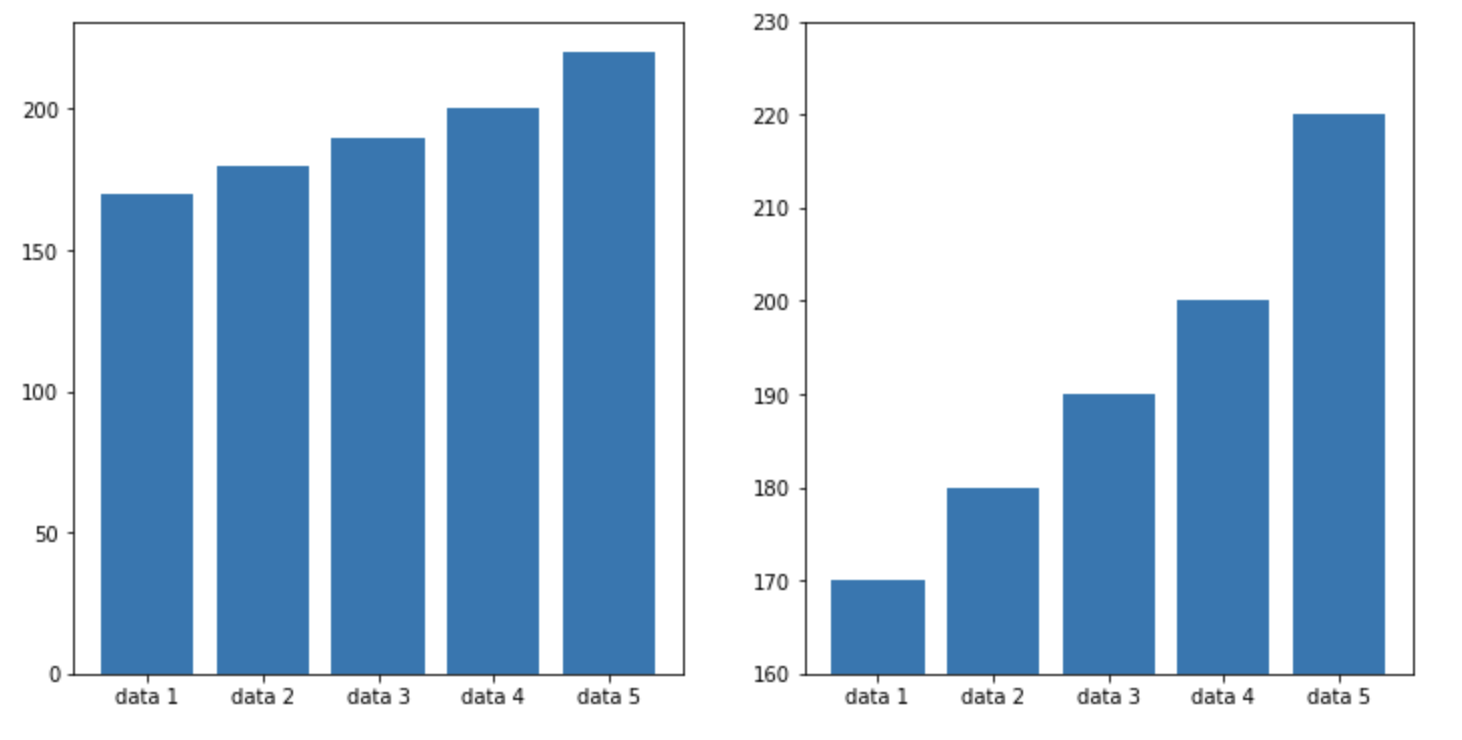
y축의 범위를 0에 맞추지 않으면 데이터의 차이가 매우 커보이는 효과를 갖게 할 수 있다. 데이터 시각화는 우리의 눈을 속일 수 있는 위험한 요소를 갖고 있기 때문에 이런 점을 주의해야한다. 정량적 지표를 표현할 때는 반드시 기준점을 0으로 맞출 필요가 있다.
Line plot
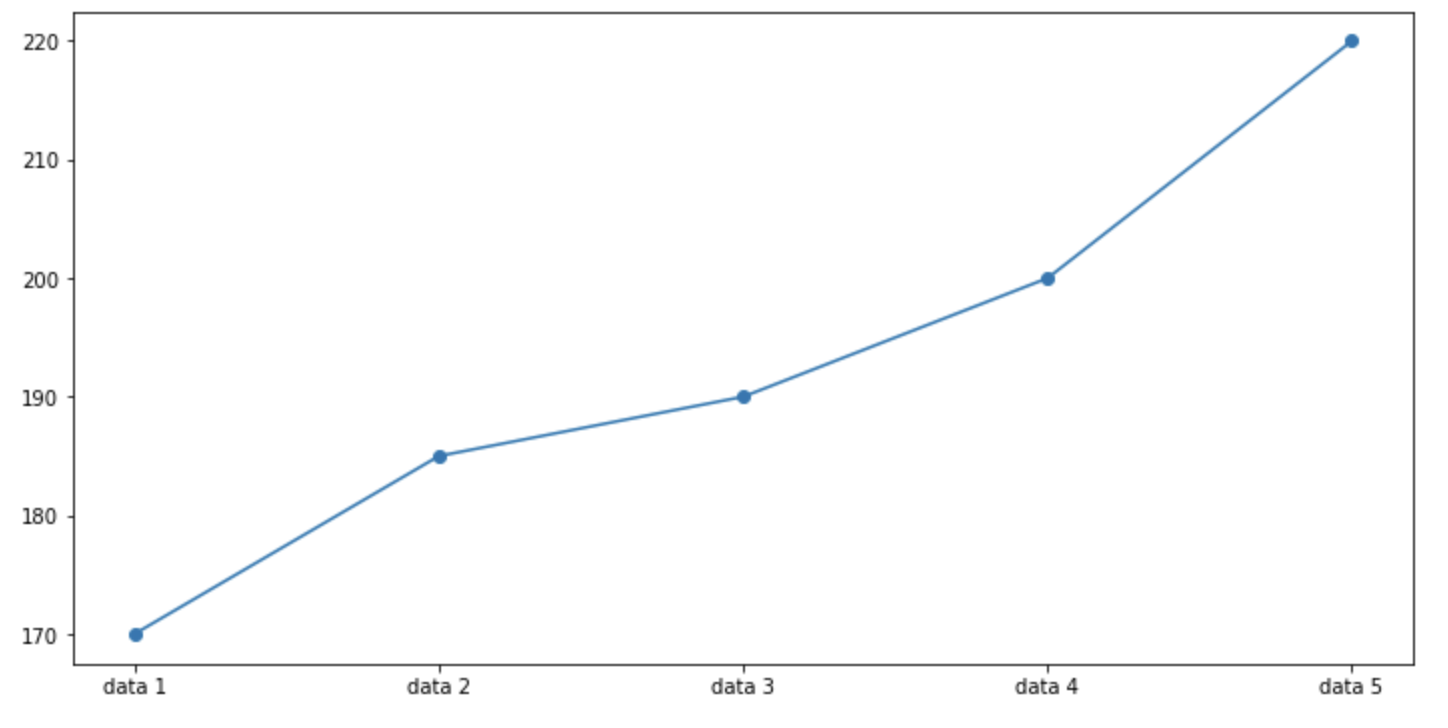
Line Plot은 전반적인 데이터의 추세를 보는 것이 주 목적이다. 따라서 반드시 데이터가 기준점이 0에 맞춰질 필요는 없다. 오히려 0에 맞추게 될 경우 데이터의 추세 흐름을 압축시켜버려 눈에 잘 보이지 않는 문제가 발생할 수 있다. 그래서 일반적으로 .set_ylim() y축의 범위를 조절하는 경우가 많다.
line plot의 간격
line plot은 데이터의 추세성을 보여주는 만큼 비례지표를 보여주는 것보다 x축 데이터의 간격이 중요하다. 따라서 x축을 주의해서 조절할 필요가 있다.

2, 3, 5, 7, 9는 데이터의 간격이 2와 3에서 무너지는 현상이 나타난다. 이를 막고자 해당 데이터는 표현을 단순히 marker를 통해 나타내는 방식을 사용하는 것이 좋다.
물론 x축 값을 살려야 할 경우 축 간격을 살려낼 필요가 있다.
보간법
Line plot의 성질상 데이터와 데이터를 연결해서 그래프를 표현한다. 이에 따라 결측치가 존재하면 전체적인 데이터의 추세가 무너질 수 있다. 따라서 시계열분야는 이전부터 다양한 방법으로 결측치를 처리하는 방식을 연구했다. 대표적인 방법은 결측치 보간법인데, forward fill, backward fill과 같은 방식도 많이 사용하지만 선형 보간법을 많이 사용한다.
1
from scipy.interpolate import make_interp_spline, interp1d
문제는 보간법은 실제 있는 데이터가 아닌 없는 데이터를 추가하는 것이므로 전반적인 데이터 분석에서 데이터 분포를 해칠 수 있다. 따라서 실질적인 분석에서는 활용을 지양하는 것이 좋다.
이 외에도 sklearn의 KNNimputer와 같은 방식을 쓸 수도 있다. KNN방식으로 상위 N개의 유사 데이터의 값을 활용하는 방식이다.
보간법 추가 자료 링크
Scatter plot
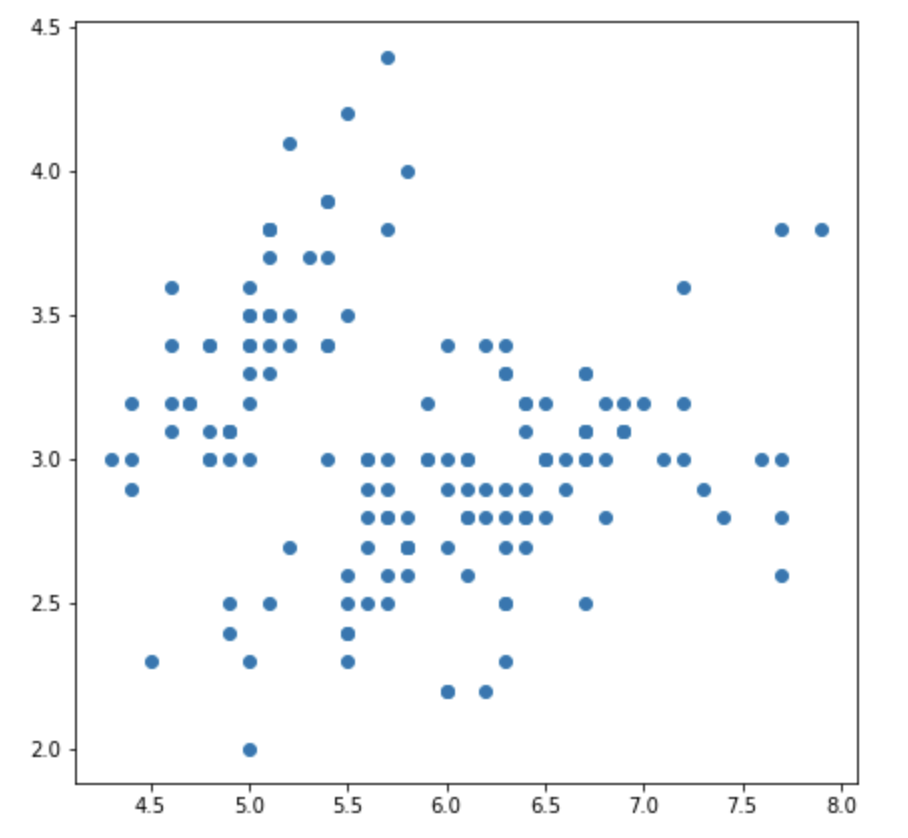
Scatter Plot은 점을 활용해 2~3가지의 feature의 관계를 알기 위해 사용하는 그래프이다. 한글 이름으로는 산점도라고도 한다.
보통 단순히 scatter plot만 사용하는 경우는 별로 없고 다양한 그래프를 섞어서 많이 사용한다. scatter plot에서 크게 주의할 것은 많이 없지만 데이터의 전반적인 관계성을 주로 보기때문에 추세선을 잘 활용하는 것도 좋다.
가장 많이 활용되는 부분은 데이터의 군집화를 시각화하는 과정에서 많이 사용한다.
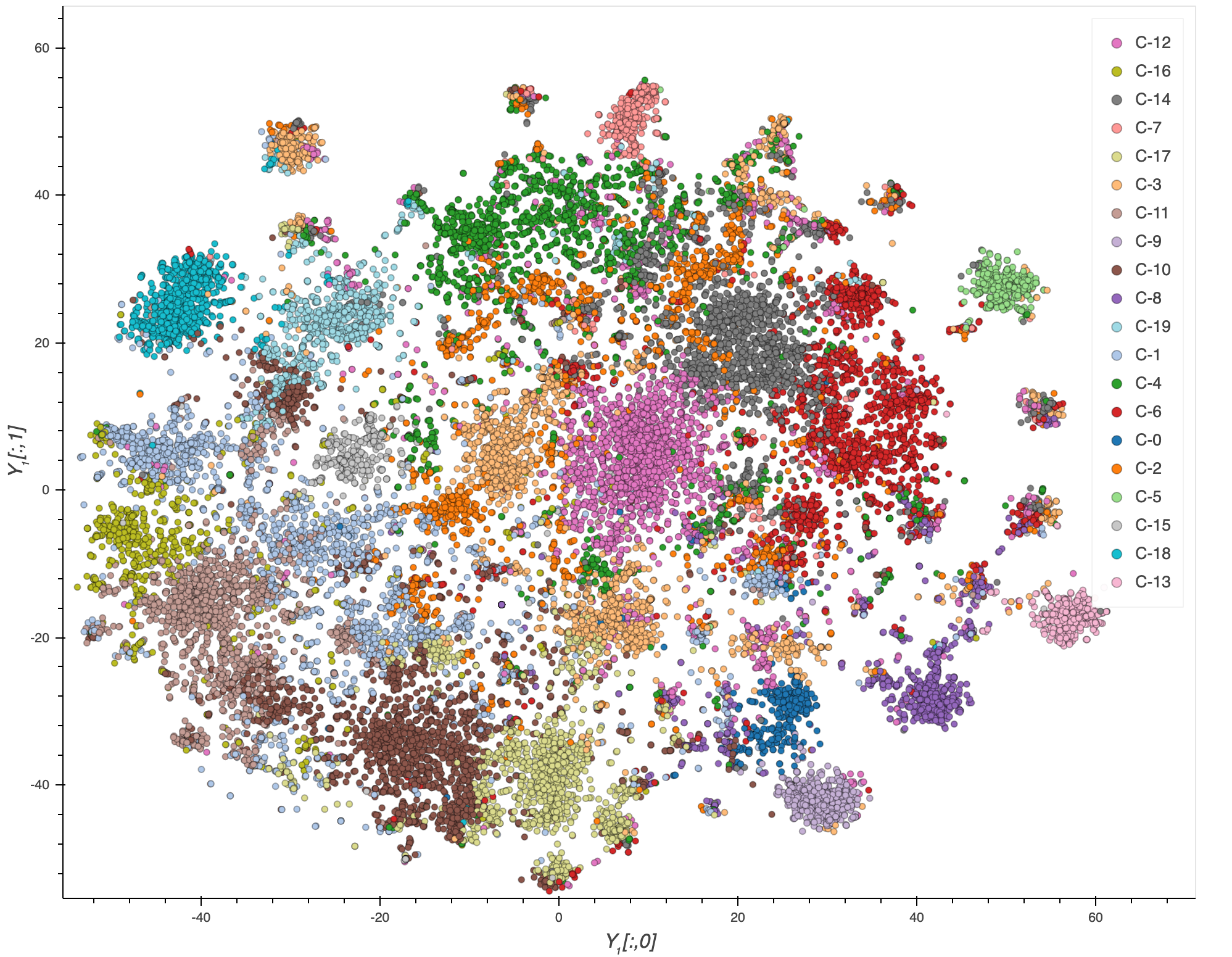 출처 : https://www.kaggle.com/maksimeren/covid-19-literature-clustering
출처 : https://www.kaggle.com/maksimeren/covid-19-literature-clustering
Scatter plot의 목적
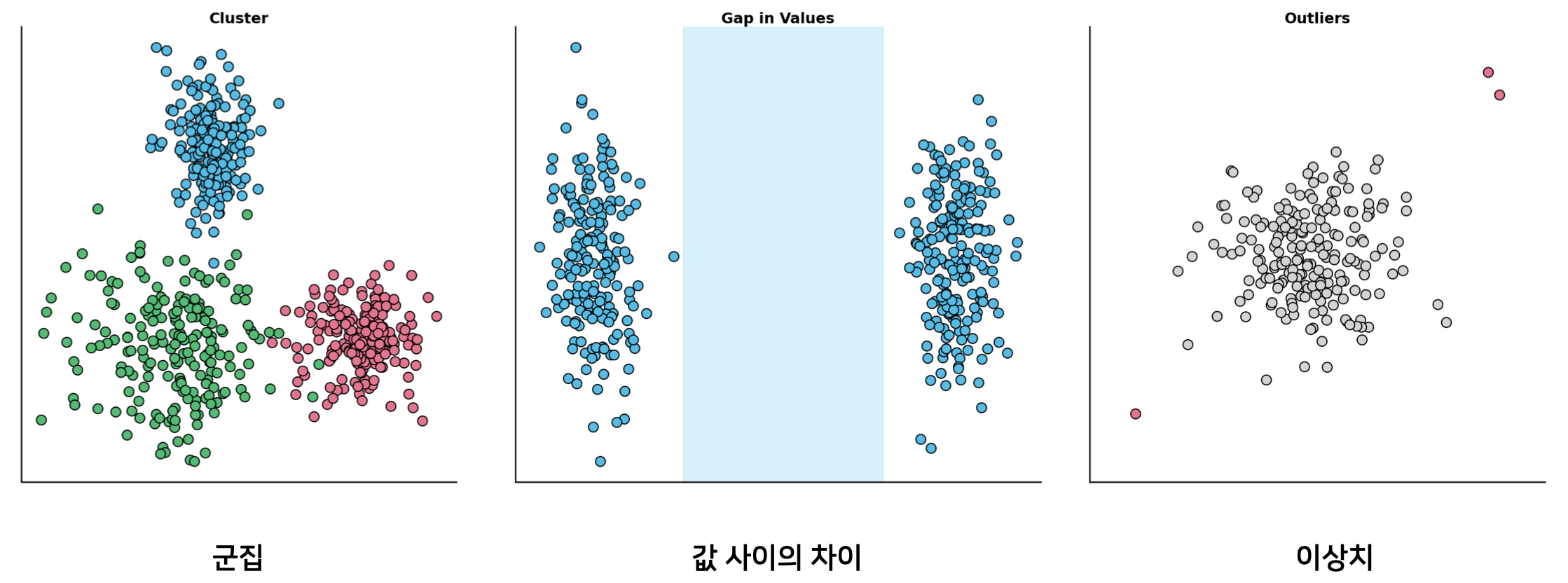
Scatter plot에서 확인할 필요가 있는 정보는 크게 3가지이다. 앞서 언급한 데이터 군집, 데이터간의 간격, 이상치(outlier) 이다.
특히 데이터 군집과 이상치는 주요하게 볼 가치가 있는 정보이다. 데이터 군집은 앞서 간단히 설명하였고 이상치 값은 데이터 전처리 과정에서 주로 처리하는 것 중 하나이고 이 데이터들은 전바적인 데이터의 경향성을 해치는 경우가 많다.
Comments powered by Disqus.