
시작하며
데이터베이스를 저장할 AWS 연결도 끝났고 이제 데이터베이스를 구축할 차례다.
데이터베이스 구축은 파이썬 크롤링을 통해서 만들 예정이다. 파이썬의 dictionary와 list를 적절히 잘 활용하면 단순히 코드로만 JSON형식의 파일을 만들 수 있다. 이번 프로젝트의 데이터베이스 MongoDB기반의 NoSQL이므로 총 2가지 document을 갖게된다. 환자의 정보를 저장하는 document인 patient와 의약품 정보를 저장하는 collection인 medicine document이다.
Database modeling
데이터베이스 구축 코딩 이전에 데이터베이스 모델링을 우선 작성해봤다. 앞에서 말했듯이 2가지 document를 모델링 해야한다.
아직 데이터베이스 모델링과 데이터베이스의 지식이 많이 부족해서 이해가 안되는 모델링 방식도 있을 수 있으니 양해바란다.
patient document modeling
초기 모델링
우선 환자정보를 저장할 patient document를 모델링해보자.
초기에 디자인한 patient document는 다음과 같았다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
{
_id: <ObjectId1>
patient_info: {
name: "patient_name",
SSN: "200825-1234567",
pregnant: false
},
take_med:[
{
prod_name: "medicine_name",
take_session: [true, true, false]
}
]
}
간단하게 데이터의 구조를 설명해보면 환자의 인적사항을 저장하는 patient_info document를 Embedded 형식으로 저장하려고 했다.
그리고 take_med는 현재 데이터를 갖는 환자가 복용하고 있는 의약품의 정보가 배열로 저장되는 document이다. prod_name은 의약품의 이름이다.
take_session은 크기가 3으로 고정인 배열로 유지가 되는데, 이유는 일반적으로 약국에서 약을 제공할 때 아침, 점심, 저녁으로 제공하는 경우가 많다. 각각의 배열 인덱스는 순서대로 아침, 점심, 저녁인지 아닌지를 저장하는 bool type 변수이다. 이렇게 초기 모델링을 진행했는데, 약사가 사용하는 환자정보 입력은 웹을 통해서 진행을 하게된다. 이때, 웹에서 입력받은 데이터를 묶어서 입력하는 과정에 문제가 발생해서 patient_info를 따로 Embedded document형식이 아닌 밖으로 분리하는 방식을 택했다.
나중에 생각해보면 굳이 해당 환자 인적정보를 다른 document에 입력할 이유가 없으므로 Embedded형식으로 만들 이유가 없었다.
최종 모델링
1
2
3
4
5
6
7
8
9
10
11
12
13
{
_id: <ObjectId1>
name: "patient_name",
SSN: "200825-1234567",
pregnant: false,
take_med:[
{
prod_name: "medicine_name",
take_session: [true, true, false]
},
...
]
}
medicine document modeling
이번 프로젝트에서 가장 큰 크기를 차지하게 될 document다.
사실 실전으로 들어가면 대한민국 국민이 5천만이라서 patient가 가장 큰 document겠지만, 임시구현에서는 의약품 정보를 담고있는 medicine document가 가장 크다.
최종 모델링
1
2
3
4
5
6
7
8
9
10
11
12
{
_id: <ObjectId2>
prodName: "medicine_name",
ingredient: ["ingr1", "ingr2", ...],
cautionInfo: [
{
ingr: "caution_ingr_name"
dur: "dur_type"
},
...
]
}
크롤링 사이트 탐색
medicine 도큐먼트는 웹 크롤링을 통해서 데이터를 구축하려고했다. 그래서 의약품 데이터를 찾던 도중 약학정보원을 크롤링 사이트로 선정을 했었다. 문제는 약학정보원의 의약품 검색 페이지 양식이 asp파일로 구성되었고 페이지 분석이 너무 어렵고 대부분이 jQuery의 형태를 띄고 있어서 beautifulsoup를 활용해서 크롤링이 너무 어려웠다.
그래서 약학정보원에 문의해서 데이터베이스를 제공받을 수 있는지 알아봤는데, 1년에 50만원으로 계약을 진행하는 것이라 이번 프로젝트에서 사용하기에 무리로 판단해서 다른 사이트로 선회했다.
약학정보원에 문의를 하던 도중에 식약처에서 제공하는 의약품정보 데이터가 있을 수 있다고 하여서 식약처에서 의약품을 관할하는 사이트인 의약품안전나라 웹 페이지를 분석했다.
다행히도 의약품안전나라에서 제공하는 의약품 상세정보는 페이지가 GET방식을 활용했다.
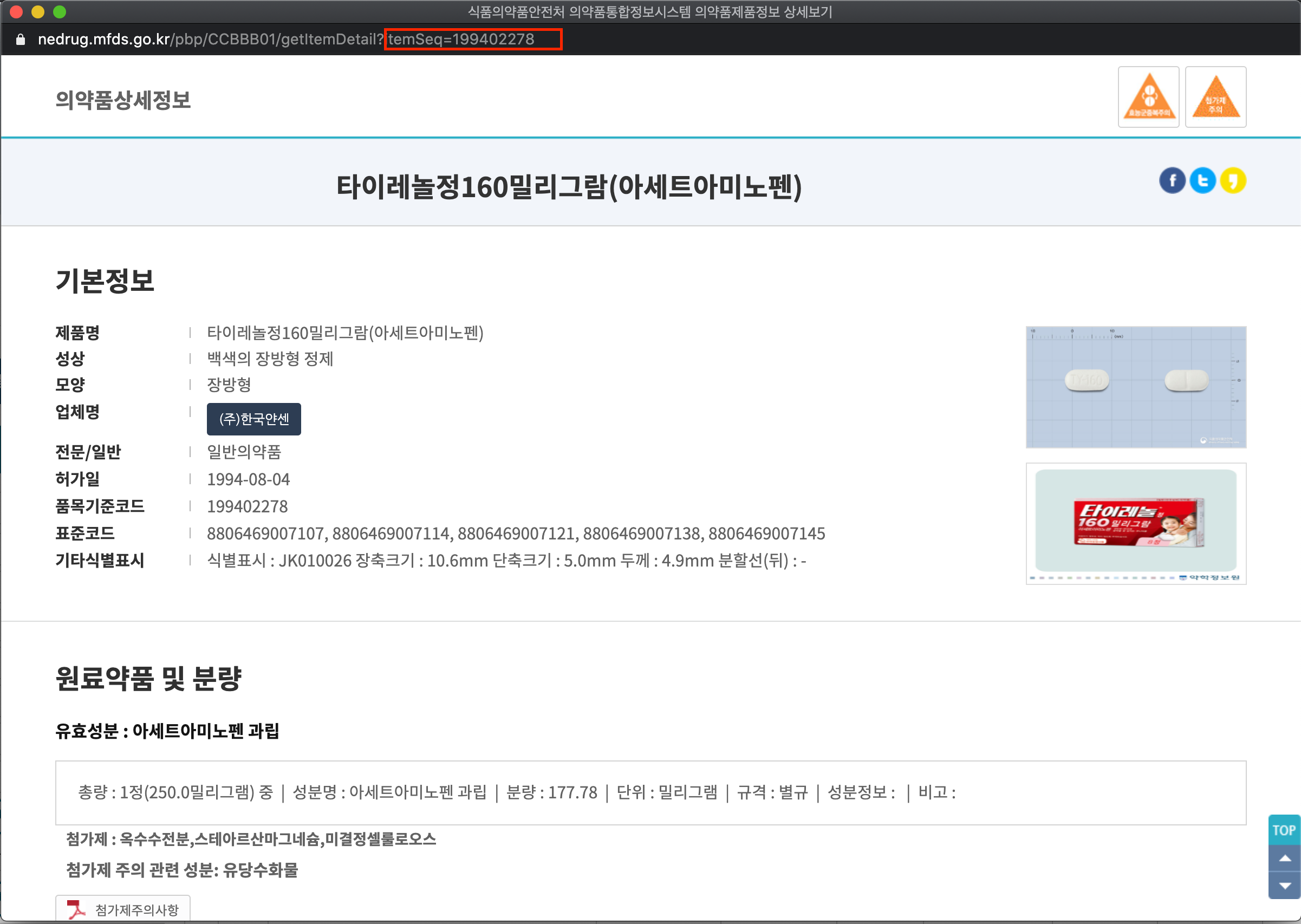 페이지의 링크를 자세히보면 itemSeq라는 변수로 페이지가 이동함을 알 수 있다. 여기서 itemSeq는 의약품안전나라 의약품검색에서 ‘품목기준코드’정보임을 쉽게 알 수 있었다.
페이지의 링크를 자세히보면 itemSeq라는 변수로 페이지가 이동함을 알 수 있다. 여기서 itemSeq는 의약품안전나라 의약품검색에서 ‘품목기준코드’정보임을 쉽게 알 수 있었다.
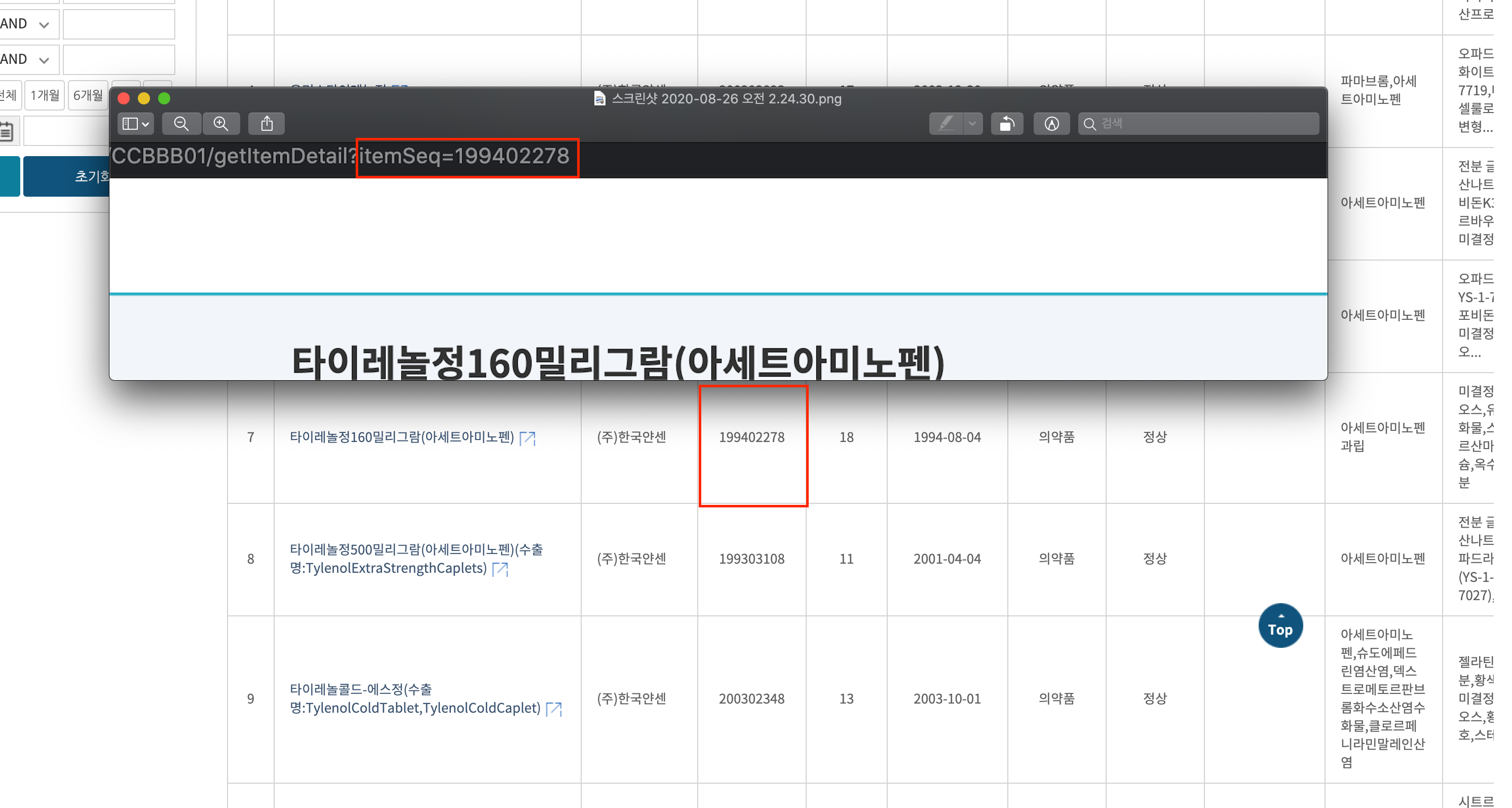 그래서 모든 데이터를 수집하기는 무리이므로 의약품 중에서 완제품만 품목코드를 크롤링했다. 품목코드 크롤링은 R을 활용해서 csv파일로 저장했다.
그래서 모든 데이터를 수집하기는 무리이므로 의약품 중에서 완제품만 품목코드를 크롤링했다. 품목코드 크롤링은 R을 활용해서 csv파일로 저장했다. (그 당시 코딩할땐 코딩한 기억이 있는데 좀 멀쩡한 상태로 코딩하려니 갑자기 안된다…. ㅠㅠ)
사이트 분석
우선 의약품안전나라의 의약품 상세정보 사이트를 분석해보면
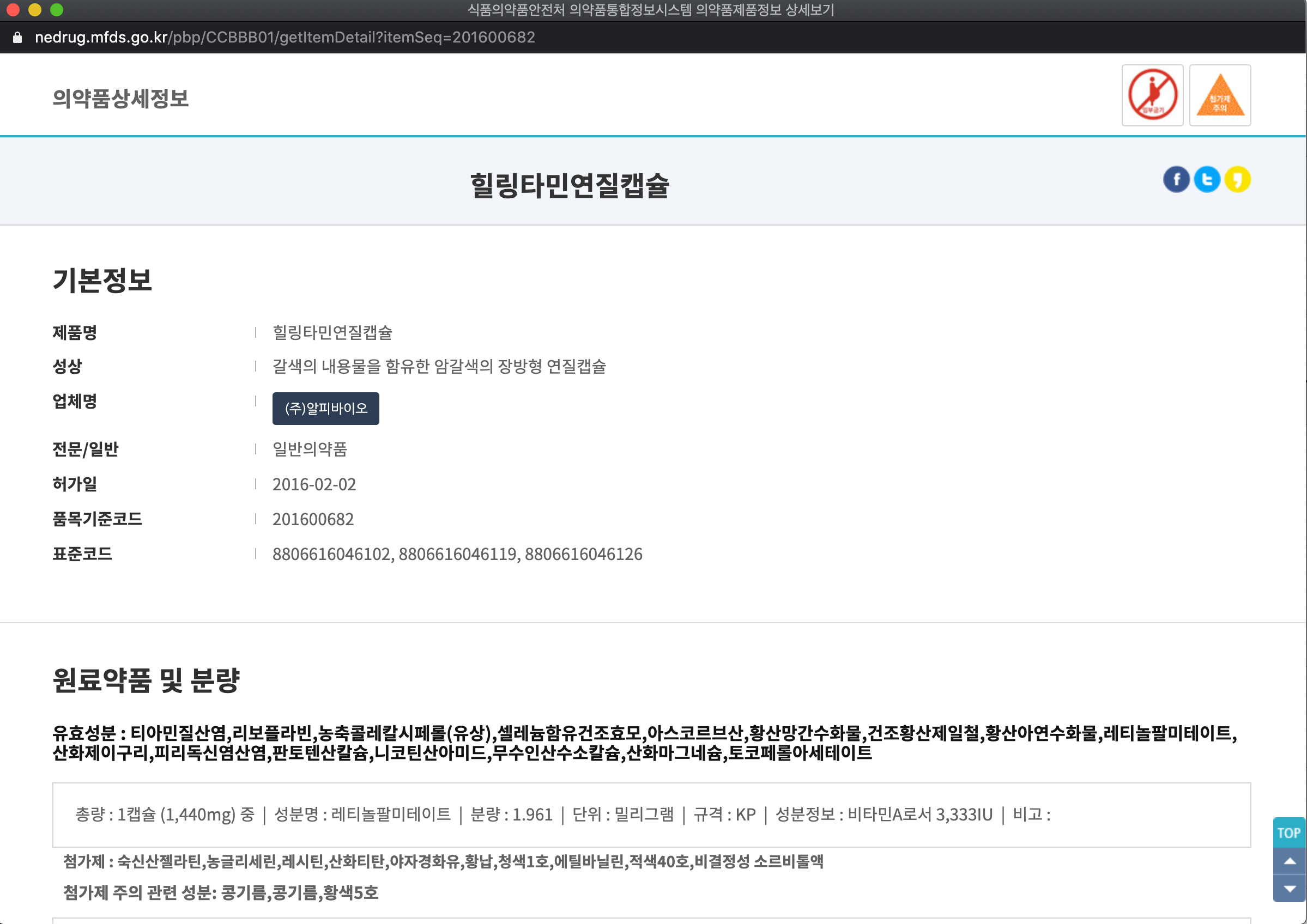 의약품 제품명과 유효성분을 가져올 수 있다. 이 정보는 의약품 정보에 저장하기엔 충분히 유효한 정보다.
의약품 제품명과 유효성분을 가져올 수 있다. 이 정보는 의약품 정보에 저장하기엔 충분히 유효한 정보다.
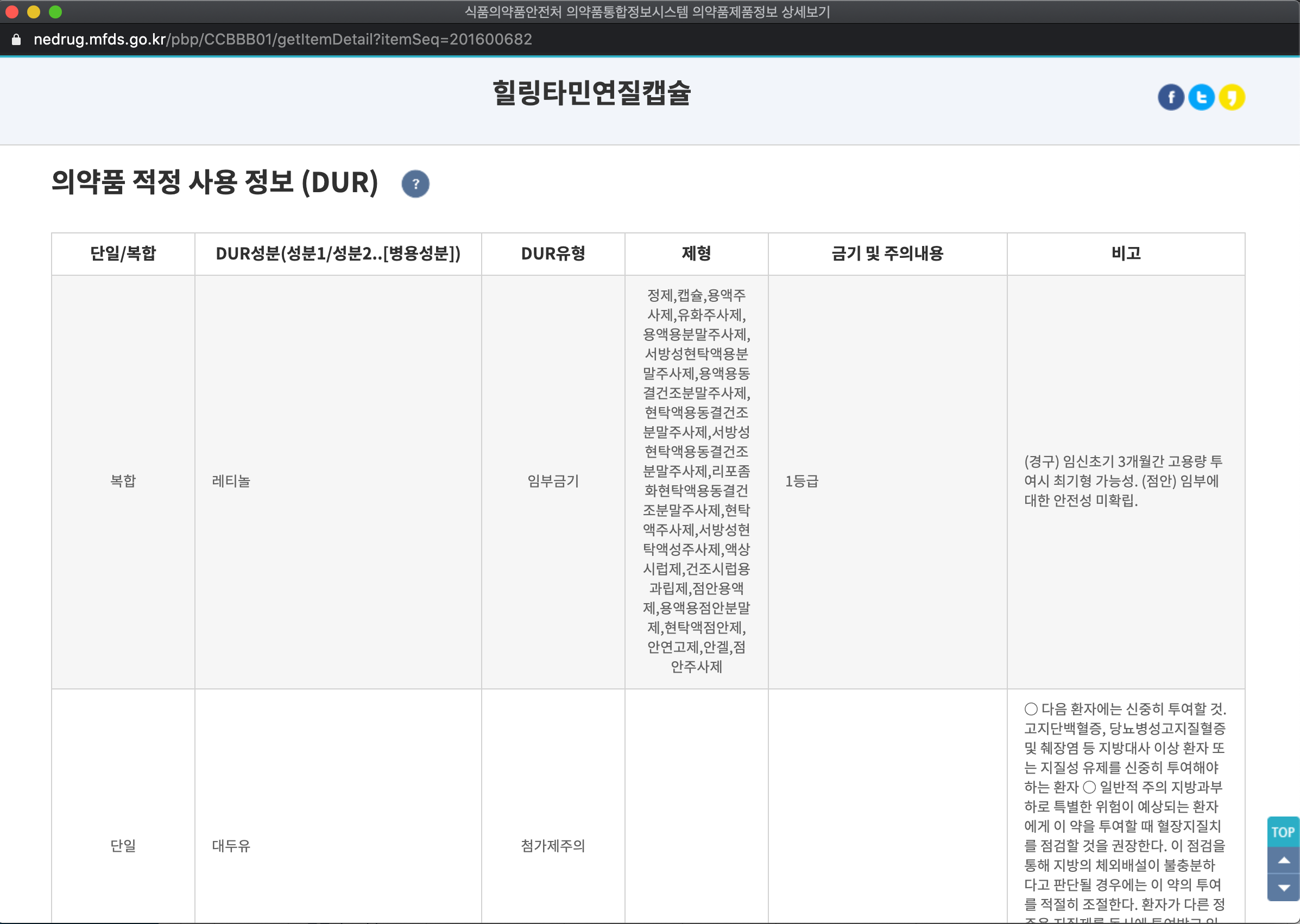 이 부분은 DUR이라고해서 의약품을 복용할 때 주의할 점을 말해주는 사용정보이다. 의약품 정보에 충분히 기록할만하다. 하지만 이 부분은 모든 의약품이 갖는 정보가 아니다. 그래서 조건문으로 이 부분이 존재하는 경우에만 데이터를 가져오기로 한다.
이 부분은 DUR이라고해서 의약품을 복용할 때 주의할 점을 말해주는 사용정보이다. 의약품 정보에 충분히 기록할만하다. 하지만 이 부분은 모든 의약품이 갖는 정보가 아니다. 그래서 조건문으로 이 부분이 존재하는 경우에만 데이터를 가져오기로 한다.
Crawling code
library and module import and connect AWS
1
2
3
4
5
6
7
8
9
10
11
12
13
14
import pymongo
import requests
import re
import csv
import urllib.parse
from bs4 import beautifulsoup
from urllib.request import urlopen
from multiprocessing import Pool, Manager
conn = pymongo.MongoClient('AWS IP address', uesrname='username',
password='password',
authMechanism='SCRAM-SHA-1')
medipush = conn.medipush
MongoDB를 연결하고 데이터를 넣을 라이브러리인 pymongo를 필요로한다. 그리고 크롤링을 위해서 beautifulsoup를 같이 연결해줘야한다. re와 parse는 페이지 분석 후 데이터를 넣기위해서 문자열 데이터를 정제할 때 사용한다.
MongoClient함수를 활용해서 연결해주면된다. 보안이 없으면 단순히 IP만 적으면 되지만 보안 연결이 된 경우에는 Robo 3T에 연결할 때 처럼 알맞은 정보를 입력해주면된다.
csv read
1
2
3
4
5
6
7
8
9
f = open('med_code.csv', 'r', encoding='utf-8')
rdr = csv.reader(f)
lists = []
for line in rdr:
lists.append(line)
f,close()
이 부분은 ‘품목기준코드’를 리스트로 저장해서 웹페이지 변동에 사용한다. lists의 내부 데이터를 보면 2차원 배열 형태라서 후에 조금 조절을 해줘야한다.
Crawling
총 품목코드 개수가 44469개인데 크롤링과정에서 너무 오랜시간이 걸려서 1만개 데이터베이스만 구축했다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
manager= Manager()
med_data_list = manager.list()
cnt = manager.list()
index = lists
medicine = medipush.medicine
error_index = manager.list()
def crawling(i):
cnt.append(i)
print('count : ', len(cnt))
print('Now data number : ', index[i][0])
url = "https://nedrug.mfds.go.kr/pbp/CCBBB01/getItemDetail?itemSeq=" + index[i][0]
res = requests.get(url)
soup = BeautifulSoup(res.content, 'html.parser')
med_basic = soup.select_one('div.r_sec tr')
# HTTPError인 경우 데이터 처리
if med_basic == None:
error_index.append(i)
return
# product name save
med_dict = dict()
med_name = med_basic.select_one('td').text
input_med = med_name.replace('\n', ' ')
med_dict['prodName'] = input_med.strip()
# 병용금기 전용 유효성분 저장 리스트
ingr_list = list()
# product ingredient save
if soup.select_one('#scroll_02 > h3'):
med_ingredient = soup.select_one('#scroll_02 > h3').text
med_ingredient = med_ingredient.replace('유효성분 : ', '')
ingredient = med_ingredient.split(',')
med_dict['ingredient'] = list(set(ingredient))
ingr_list = list(set(ingredient))
# product caution save
## dur info exist
if soup.select_one('#scroll_06 > table'):
temp = soup.select('#scroll_06 > table > tbody > tr > td')
dur_info = list()
tmp = list()
for item in temp:
tmp.append(item.text.split('\n'))
data_insert = False
name = list()
dur_list = list()
for item in tmp:
dur_data_input = False
input = dict()
if "DUR성분(성분1/성분2..[병용성분])" in item:
dur_ingredient = item[item.index('DUR성분(성분1/성분2..[병용성분])') + 1]
if "DUR유형" in item:
dur_type = item[item.index('DUR유형') + 1]
if item[item.index('DUR유형') + 1] == '병용금기':
dur_data_input = True
data_insert = True
# dur_mix를 저장하는 딕셔너리 생성
## 문자열 파싱 파트
dur_main = re.sub('\[\w*\]', '', dur_ingredient)
dur_mix = re.search('\[\w*\]', dur_ingredient)
dur_mix = dur_mix.group().replace('[','').replace(']','')
for t in ingr_list:
if dur_mix in t:
# 부분일치가 dur_mix에 있는 경우 dur_main을 넣어줘야함
mix = True
break
elif dur_main in t:
# 부분일치가 dur_main에 있는 경우 dur_mix에 넣어줘야함
mix = False
break
else:
mix = False
if mix:
if dur_main not in name:
name.append(dur_main)
input['ingr'] = dur_main
input['dur'] = '병용금기'
else:
continue
else:
if dur_mix not in name:
name.append(dur_mix)
input['ingr'] = dur_mix
input['dur'] = '병용금기'
else:
continue
elif item[item.index('DUR유형') + 1] != '분할주의':
data_insert = True
dur_data_input = True
input['ingr'] = dur_ingredient
input['dur'] = dur_type
if dur_data_input:
dur_list.append(input)
if data_insert:
med_dict['cautionInfo'] = dur_list
medicine.insert_one(med_dict)
if __name__ == '__main__':
med_data_list = manager.list()
start_time = time.time()
pool = Pool(processes = 10)
pool.map(crawling, range(0, 10000, 1))
pool.close()
conn.close()
print('----------------------------------------\n')
print(' \n')
print('All data search end and Make a database!\n')
print('total time : ',time.time() - start_time)
print('error product code list : ', error_index)
print(' \n')
print('----------------------------------------\n')
프로젝트 진행하면서 가장 많이 수정된 코드다. 우선 최종적인 코드를 간단하게 리뷰해보면 다음과 같이 구성되어 있다.
- 제품 이름 설정
- 제품 성분 설정
- 제품 주의 내용 설정
- 병렬 연산으로 크롤링 속도 증가
- 1번 코드
- 1번과 2번은 모든 의약품 대상으로 처리를 해준다. 이때 일부 페이지가 서버 로드가 느려서 HTTPError가 뜨는 경우가 있어서 1번 데이터에서 None 값이 잡히게 된다. 이 부분이 None값이 되면 insert_one에서 오류가 나서 프로세스가 종료가 된다. 그래서 해당 부분이 None일 때는 따로 개별 처리 단계로 넘기기 위해서 데이터 인덱스를 저장시키고 스킵시켰다.
- 3번 코드 3번 코드는 굉장히 길다. 그래서 자세히 리뷰를 해보겠다.
- 우선 크롤링 페이지에는 우리가 크롤링 하려는 위험 정보 즉, DUR정보가 있는 의약품이 있고 없는 의약품이 있다. 그래서 무조건적으로 해당 부분을 select_one을 하면 에러가 나서 프로세스 종료가 난다. 그래서 조건문 처리를 진행했다.
- 크롤링으로 가져온 데이터를 보면 ‘\n’으로 데이터가 구분되어 있음을 알 수 있다. 그래서 수집 데이터 중에서 필요한 부분만 인덱스를 가져오기 위해서 문자열 파싱을 진행했다.
- 변수의 역할을 설명해보면 data_insert는 이후에 자세히 설명을 하겠지만 DUR중에 유일하게 데이터 양식이 다른 데이터가 있는데, 그 데이터를 구분하기 위한 bool타입 변수다. name은 DUR성분을 보면 중복된 값들이 존재하는데, 중복데이터 처리를 위한 리스트다.
- 서버관리 파트 팀원의 요구로 자신이 가진 성분을 제외하고 병용금기 데이터를 가져와달라고 요청했다. 우선 병용금기 데이터를 보면 ‘성분1[성분2]’와 같은 방식으로 구성되어있는데, 성분1과 성분2의 문자열을 분리하는 작업을 진행해야했다.
- 그 후 성분을 저장한 리스트의 데이터를 탐색하면서
if ~ in문으로 성분1이 일치하는지, 성분2가 일치하는지를 확인해본다. 그 후에는 각주 설명처럼 코드를 연결해주면된다.
- 4번 코드
- multiprocessing을 활용해서 병렬 연산처리를 진행했다. 기존의 크롤링으로 진행하면 100개 데이터 처리시 210초 정도 걸린 반면 8개 pool을 사용해서 크롤링할 경우 30초까지 줄일 수 있다. 그래서 10개 정도로 데이터 연산을 진행했다.
이 방식을 상대방 입장에선 서버 공격으로 느낄 수 있으므로 주의해야한다.
- multiprocessing을 활용해서 병렬 연산처리를 진행했다. 기존의 크롤링으로 진행하면 100개 데이터 처리시 210초 정도 걸린 반면 8개 pool을 사용해서 크롤링할 경우 30초까지 줄일 수 있다. 그래서 10개 정도로 데이터 연산을 진행했다.
Comments powered by Disqus.