
Introduction to Machine Learning Engineering in Production
이 포스트는 Coursera의 MLOps Specialization 강의 내용을 기반으로 작성되었습니다.
Overview
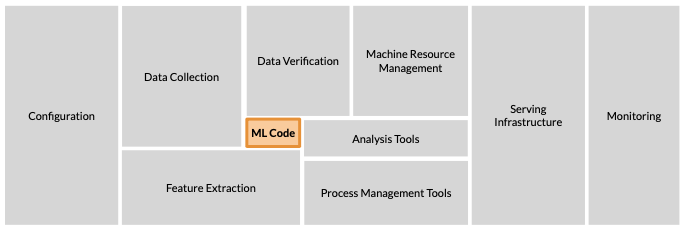
- 실제 머신러닝 시스템에서 ML Code가 차지하는 것은 매우 적은 부분
- 그 외에 처리하는 것들이 더 중요하고 많은 부분을 차지
- Academic 관점과 Production 관점에서 ML은 차이가 존재
| Academic/Research ML | Production ML | |
|---|---|---|
| Data | Static | Dynamic-Shifting |
| Priority for design | Highest overall accuracy | Fast inference, good interpretability |
| Model training | Optimal tunig and training | Continuously assess and retrain |
| Fairness | Very important | Crucial |
| Challenge | High accuracy algorithm | Entire system |
- Production ML에서의 과제
- ML 시스템 통합환경 구축
- 끊김없는 지속적인 배포
- 지속적으로 변화하는 데이터 핸들링
- 컴퓨팅 자원 최적화
ML Pipelines
- ML pipeline이란 모델의 자동화, 모니터링, 유지보수에 필요한 infrastructure
- ML Pipeline은 대체적으로 directed acyclic graph(DAG)구조
- DAG는 사이클이 없는 방향 그래프
- 좀 더 심화된 상황에는 사이클이 존재할 수도 있음
파이프라인 통합관리 프레임워크 (pipeline orchestration frameworks)
- DAG 기반의 ML pipeline의 다양한 구성요소들을 스케쥴링할 필요가 있음
- 파이프라인 자동화를 도와줌
- 예시로는 Airflow, Argo, Celery, Luigi, Kubeflow가 있음
TensorFlow Extended (TFX)
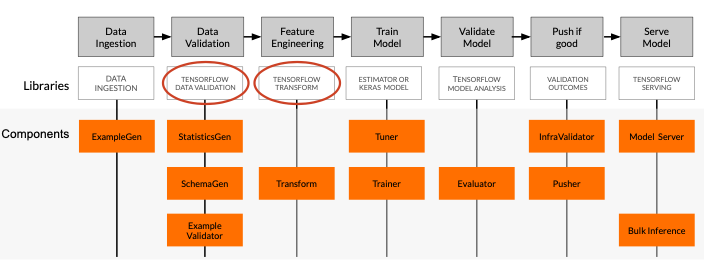
- 강의에서는 구글이 제공하는 TensorFlow Extended(TFX)는 ML pipeline 구축에 도움을 줌
- 큰 규모의 데이터 핸들링이 가능한 sequnce of scalable component
- 각 단계에 맞는 모듈들을 제공해주고 있음
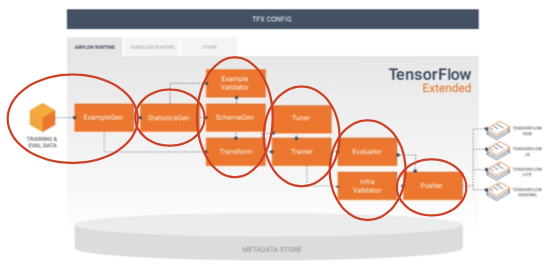
ExampleGen은 데이터 수집단계에 도움을 줌StatisticsGen은 데이터의 통계적 정보를 수집ExampleValidator은 데이터의 문제 상황을 볼 수 있음
SchemaGen는 피처의 스키마를 구성해줌
Transform은 feature engineering 역할을 함Tuner와Trainer는 학습과정과 조정단계에 사용Evaluator와InfraValidator는 각각 Deep Learning 분석과 실제로 측정하는 과정에 사용됨
이번 강의는 Andrew Ng이 아닌 Robert Crowe가 진행하였습니다. 전반적인 ML pipeline 구성과 관련된 내용을 다루고 있습니다.
주요 핵심적인 포인트는 서비스 배포를 위한 파이프라인은 자동화, 모니터링, end-to-end process의 유지보수입니다. 이때 ML 배포에서는 ML 코드가 차지하는 부분은 매우 적습니다.
이를 도와주는 도구로 오픈소스인 TFX를 활용할 수 있다고 합니다.
Comments powered by Disqus.