
Deployment
이 포스트는 Coursera의 MLOps Specialization 강의 내용을 기반으로 작성되었습니다.
Key challenges
- ML model의 배포에서 핵심과제 2가지
- ML & Statistical issues
- SW engine issues
- ML 배포에서는 detect change와 mange change가 중요
Concept drift and Data drift
- 실서비스에서는 데이터가 변하는 경우가 많은데, 크게 2가지 케이스가 존재
- 점진적 변화의 경우 새로운 단어가 나타나는 등의 변화를 말함
이런 변화는 자주 일어나진 않고 낮은 빈도로 발생 - 급격한 변화의 경우 COVID-19이 발생한 후 개인의 소비패턴이 급격히 변화하여 신용카드 사기 시스템이 제대로 동작하지 못한 것처럼 급격한 데이터 분포의 변화를 말함
- 점진적 변화의 경우 새로운 단어가 나타나는 등의 변화를 말함
- Concept Drift : $X\rightarrow Y$의 mapping 관계가 변하는 경우
- ex) COVID-19이후 online shopping 증가로 신용카드 사용량 급증
- 기존에 $X$에 따른 $Y$의 mapping 관계에서 변화가 나타난 경우
- Data Drift : input data의 분포가 변경되는 경우
- ex) 특정 영화, 인물이 갑작스러운 유명세를 타는 경우 / 주변 밝기의 변화
- deploy 후 데이터가 변경되는 경우
- 훈련데이터와 테스트 데이터 관점에서도 존재
- Training set
- purchased data, historical user data
- user data의 경우 privacy issue를 반드시 체크
- Test set
- 최근 데이터에서 잘 동작하지만 시간이 흐른뒤 성능이 떨어지는 경우가 발생할 수 있음
- Training set
Software engineering issues
- SW적 관점에서 확인해야 할 것 목록
- Realtime or Batch
- Realtime : 즉각적인 음성인식처리
- Batch : 하루동안 환자의 전반적 의료기록
- Cloud VS Edge/Browser
- 최근에는 Cloud 환경에서 자주 진행
- browser도 wifi 성능 향상등의 이유로 성능이 좋아짐
- Compute resource (CPU/GPU/memory)
- SW 구조 설계에 도움
- Latency, throughput(QPS)
- Logging
- system building시 데이터만큼 유용하게 활용
- analysis review, retraining algorithm 등…
- Security and Privacy
First deployment VS maintenance
- 서비스 배포에서는 소프트웨어적인 포인트가 중요
- 이후 모니터링 과정에서는 data drift, concept drift 처리가 중요
Deployment patterns
- 배포를 진행하는 경우는 3가지 정도가 있음
- 새로운 상품과 기술
- 수동진행 과업의 자동화
- 이전 ML 시스템 대체
- 배포과정에서 핵심 포인트
- 점진적으로 배포과정을 증가하면서 모니터링
- 검증이 덜된 algorithm이라면 적은 양의 traffic부터 시작해서 지속적 모니터링을 통한 트래픽 조절
- 롤백
- 알고리즘이 동작하지 않으면 이전 시스템으로 롤백
- 점진적으로 배포과정을 증가하면서 모니터링
배포 과정은 단순히 배포만하고 끝나지 않습니다. 이런 다양한 배포 과정에서 문제를 최소화하기 위해 다양한 방식으로 배포를 합니다.
강의에서는 핸드폰 액정 기스 불량품 분류 모델 예시를 들었습니다.
배포 초기 과정
- ML 시스템은 인간과 함께 동작하며 인간의 결정을 대부분 따라함
(ML system shadows the human) - ML 시스템이 결정은 이 과정동안에는 사용되지 않음
- 이 과정에서는 인간의 판단과 비교 데이터를 수집가능
- 인간의 결정과 다른 ML 시스템의 결정을 기반으로 ML 시스템의 예측을 검증 가능
Canary deployment
- 모델의 실제 의사결정 과정이 준비가 된 경우 적용하는 배포방식
- 아주 약간의 트래픽 (약 5%정도)에 대해서만 algorithm을 적용
- 적용이후 지속적인 모니터링을 통해 성능에 확신이 드는 경우 트래픽을 점진적으로 증가적용
Blue Green deployment
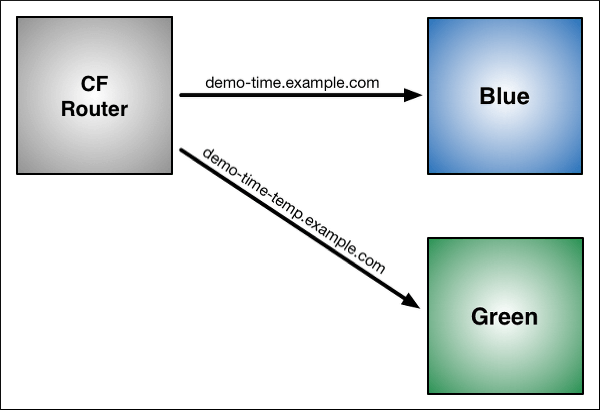
- 기존 배포 혹은 최초 배포된 버전을 Blue vesion(Old version)이라고 함
- 새로운 모델 및 버전(Green Version)이 나오면 배포를 진행
- 이때 기존에 있는 blue version이 사라지는 것이 아니고 특정 서비스에서는 사용될 수 있음
- Green version에서 문제가 발생하면 blue version으로 롤백 진행
Degree of automation

- 왼쪽으로 갈수록 인간, 오른쪽으로 갈수록 자동화 성능이 강화
- 전반적인 배포과정의 자동화 단계라고 볼 수 있음
- 중간단계인 AI assistance와 Partial automation 단계에서는 사람의 도움이 함께 존재(human in the loop)
Monitoring
Monitoring dashboard
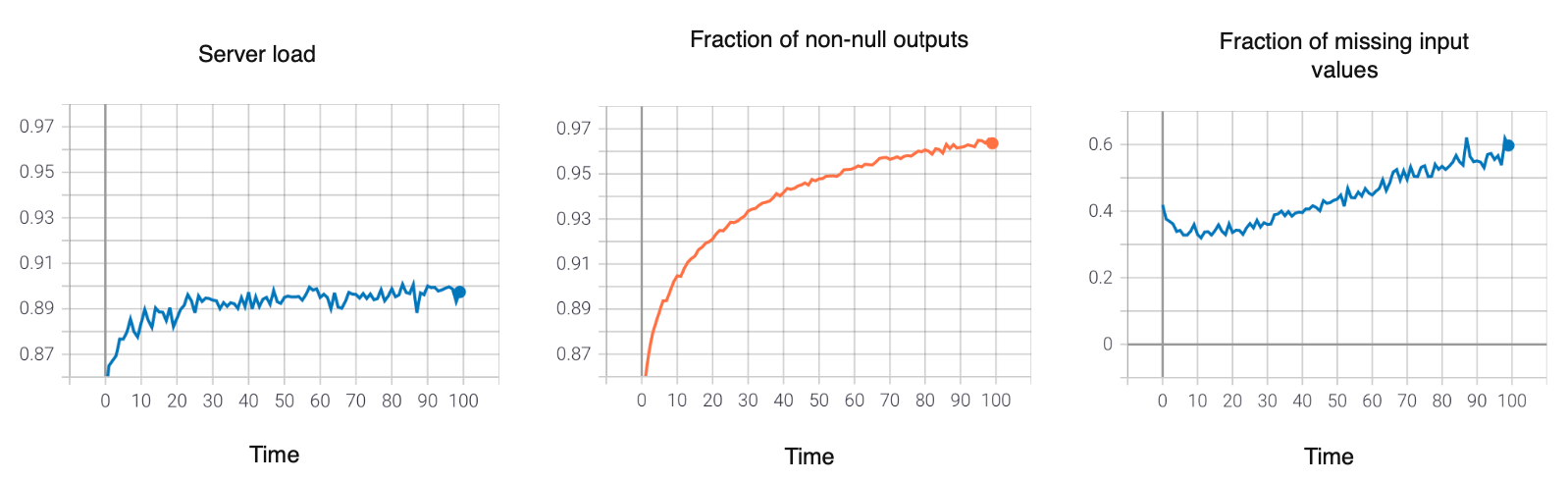
- 모니터링 dashboard에는 server load, non-null output, missing input 등의 정보를 보여줌
- 일반적으로 각 지표들의 상하한을 결정해서 기준점으로 삼음
- 무언가 잘못된 지표를 보인다면 brainstorm을 통해 해결책을 찾아야함
- 초기에 많은 metric을 쓰는 것은 괜찬지만 점진적으로 필요가 없는 것은 제거하는 것이 좋음
Example of metrics to track
- software metrics
- memory, compute, latency, throughput, server load
- Input metrics : distribution change를 측정
- Avg input length
- Avg input volume
- Num missing value
- Avg image brightness
- Output metrics
- # times return null
- # times user redoes search
- # times user switches to typing
- CTR (click thorough rate) $\rightarrow$ web search
지속적인 추적을 해야하는 지표는 다양하게 있습니다. SW적인 부분도 추적을 지속적으로 해야하며 Input과 Output에 대한 지표도 지속적으로 추척해야합니다.
Input에서 평균 길이나 볼륨이 변화하면 알고리즘의 성능저하에 직접적인 영향이 있을 수 있다고 합니다.
Output에서는 사용자의 입력이 없는 경우나 음성인식의 경우 음성인식을 포기하고 직접 입력하는 등과 같은 행위적인 추적을 할 필요도 있습니다.
두 경우 모두 팀원들과의 논의를 통해 MLOps 설계시 두 지표를 모두 추적하게 설계할 필요가 있습니다.
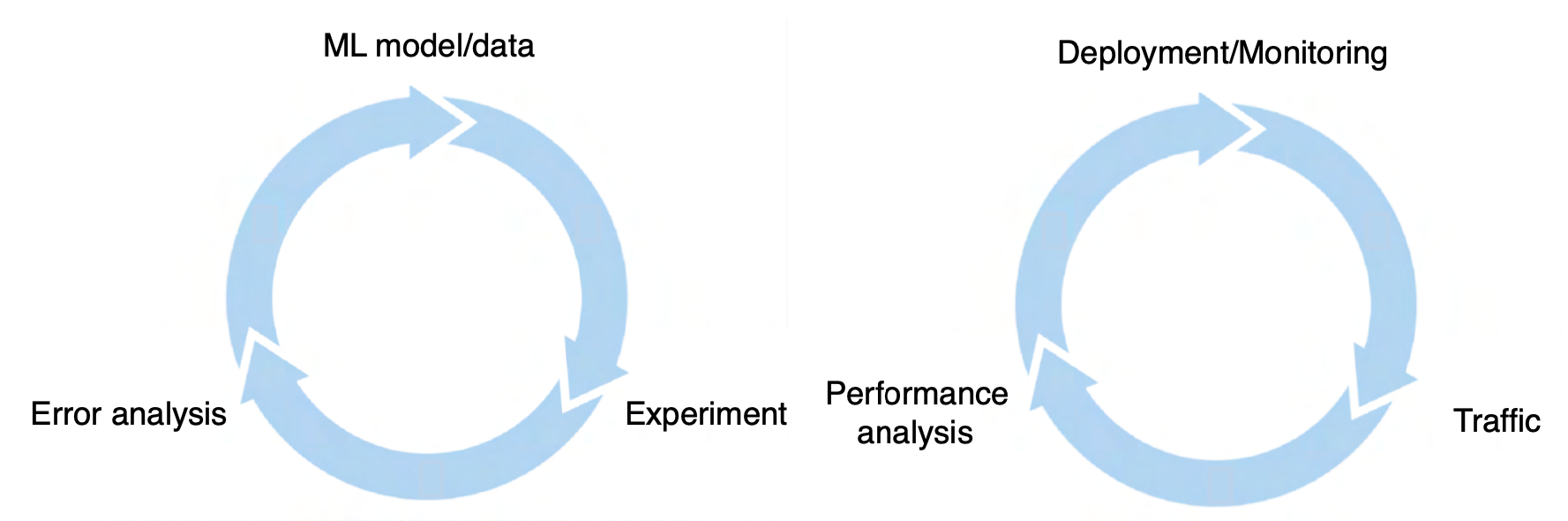
왼쪽은 모델 개발, 오른쪽은 모델의 서비스 배포 관점의 반복적 흐름입니다.
모델의 연구 개발관점에서는 학습과 성능 향상에 집중해서 반복적 학습을 진행합니다.
서비스 배포적 관점에서는 시스템의 동작과 성능분석을 진행하고 재배포를 진행합니다. 일반적으로 특정 metric monitoring $\rightarrow$ 지표결정 $\rightarrow$ 지표 고정 $\rightarrow$ 새로운 metric setting의 과정을 반복합니다.
Model maintenance
- 모델의 유지보수 과정에서는 개발자가 직접 컨트롤하는 Manual retraining과 Automatic retraining이 있음
- 대부분의 개발자는 직접 컨트롤 하는 manual retraining을 선호함
- 재학습과 새로운 방식의 적용을 완전 자동화하는 것을 개발자는 꺼린다고 함
Pipeline monitoring
Speech recognition example
- 음성인식 케이스에서 일반적으로 바로 음성인식 처리를 하는 경우도 있지만 일부 기기는 voice activity detection 모듈이 있는 경우가 존재
- 이런 경우 추가 모듈에 의해 성능이 감소할 수 있음
$\rightarrow$ 연결된 모듈은 하나가 다른 하나에 영향을 미치기 때문
User profile example
- user profile을 통해 추천목록을 작성하는 경우 유저 데이터 변경을 고려해야함
- 추천/비추천/알 수 없음으로 분류하는 ML system이었다고 가정하면 기존에는 알 수 없음의 비중은 높지 않음
- 시간이 흘러 user profile의 분포가 변경되면 y의 분류가 알 수 없음이 되는 경우가 많음
- 그 결과 성능자체에 영향을 미치게되고 이런 비정상적 비율 증가 사실을 알려줘야 성능에 영향이 덜 함
- pipeline에서는 위와 같은 cascading effect를 추적하기가 어려움
Metrics to monitor
- Monitor
- SW metrics
- Input metrics
- Output metrics
- pipeline의 개별구성요소 metric
- 여러 변화로 인한 unknown 증가와 같은 유지보수를 위한 사항을 알려줌
- 데이터 변화 속도 $\rightarrow$ problem dependent
- 유저 데이터는 일반적으로 천천히 변화함 ex) 얼굴인식 변화는 느림
- 기업 데이터는 빠르게 변화함 ex) 패션 데이터의 변화는 빠름
Comments powered by Disqus.