
AlexNet (2012)
GitHub : AlexNet Implementation
논문 소개
 출처 : NIPS2012 ImageNet Classification with Deep Convolutional Neural Networks (a.k.a AlexNet)
출처 : NIPS2012 ImageNet Classification with Deep Convolutional Neural Networks (a.k.a AlexNet)
AlexNet은 본격적으로 딥러닝이 실전적인 효과를 나타낸 대표적인 신경망 모델입니다. 논문에 따르면 AlexNet은 224 X 224의 이미지를 분류하는 대회인 ImageNet LSVRC(ILSVRC) 에 2010년과 2012년 총 2번 참가를 하였고 2012년 대회에서 우승을 차지하며 딥러닝의 시대를 열었습니다.
기존에도 CNN이 존재하였지만 이를 직접적으로 활용하기에 어려움이 있었습니다. 하지만 GPU를 활용한 CNN구조의 구현과 Dropout을 적용시킨 AlexNet이 등장하며 이미지 분류에서 CNN의 입지가 굉장히 뛰어올랐습니다. 이번 글에서는 AlexNet의 논문을 리뷰하며 자세한 내용을 공부해보도록 하겠습니다.
개인 공부의 목적도 포함하고 있어서 각 파트별로 나눠서 작성하였으므로 필요한 부분에 맞춰 우측의 목차를 클릭하셔서 이동해주시길 바랍니다.
우측 목차가 제대로 리스트업이 되지 않아 아래에 목차를 따로 두었습니다.
이 글에는 오타 및 오역이 존재할 수 있습니다. 참고하여 읽어주시고 번역이 부자연스러운 경우 원문 부분을 함께 작성하였습니다.
- Abstract
- 1. Introduction
- 2. The Dataset
- 3. The Architecture
- 4. Reducing Overfitting
- 5. Details of learning
- 6. Results
Abstract
- AlexNet은 120만개의 고해상도(224 X 224)이미지를 분류하는 ILSVRC 2012에서 error rate 16.4%를 기록하며 우승
- 총 6천만개의 parameter와 65만개의 뉴런으로 구성된 모델
- 5개의 convolution layer + 3 fully-connected layer로 구성
- 5개의 convolution layer 중 일부는 max-pooling layer가 연결되어있음
- 3개의 fully-connected layer는 최종 1000-way softmax로 구성되어있음
- 훈련 속도의 향상을 위해 비포화 뉴런과 GPU구현의 convolution 연산을 사용
- 과적합 방지를 위해 Dropout을 활용
1. Introduction
Chapter 요약
- 기존의 이미지 분류 문제들의 데이터 셋은 수만개 정도로 작은 크기의 데이터 셋이었고 학습을 통해 인식을 진행하는 데에 큰 무리가 없었음
- 기존에도 이미지를 변형하는 방식은 image augmentation이 존재해서 지정된 label을 지키는 선에서 데이터를 증폭하는 방식으로 학습을 했기 때문
- 현실의 데이터는 상당히 가변적인 환경(considerable variability)을 갖고 있기 때문에 이를 적용하기 위해서는 큰 규모의 데이터 셋이 필요
- 작은 데이터 셋의 문제점은 이미 알려졌지만 어쩔 수 없는 한계로 최근에서야 큰 규모의 데이터 셋을 만들 수 있었음
- 대표적인 예시가 ILSVRC의 ImageNet 데이터 셋
- 큰 규모의 데이터를 학습하기 위한 모델은 규모가 커져야 하는데, object recognition 작업은 매우 큰 복잡도를 갖는 작업이고 따라서 ImageNet에 적용하기 어렵다는 문제가 발생함
- 이를 해결하고자 모델은 갖고 있지 않은 데이터에 대해 많은 사전지식이 있어야 함
(원문: so our model should also have lots of prior knowledge to compensate for all the data we don’t have.)
- 이를 해결하고자 모델은 갖고 있지 않은 데이터에 대해 많은 사전지식이 있어야 함
- CNN의 가정에 따르면 이런 복잡도와 데이터의 사전지식 문제를 해결하기에 좋음
- CNN은 넓이와 폭에 의해 capacity가 결정되고 이미지의 특성에 대해 올바른 추정을 함
- CNN은 parameter와 connection의 수가 fully-connected layer에 비해 훨씬 적기 때문에 빠른 훈력속도와 성능의 보존이 가능
- 하지만 기존의 CNN은 적용에 있어서 대규모의 비용이 든다는 단점이 존재
- 2D convolution과 결합된 GPU로 인해 학습에 적용할 수 있게 되었음
- 이 논문에서는 2D convolution에 최적화된 GPU 연산구현, 성능 향상과 동시에 학습 시간을 줄이기 위한 새로운 feature와 자주 사용하지 않는 feature제시, 과적합 방지를 위한 Dropout의 적용에 대해 설명
- 최종 신경망의 구조는 5개의 convolution layer와 3개의 fully-connected layer이고 이 깊이는 성능자체제 중요한 영향을 미침
- 모델 학습 환경은 2개의 GTX 580 3GB GPU로 5~6일 정도 훈련을 진행했음
Chapter 분석
- CNN 가정에 나오는 이미지의 특성(nature of images)은 총 2가지가 언급됩니다.
내용 참고 : CNN과 이미지가 찰떡궁합인 이유- Stationary of statistics
- stationary란 확률론에서 시계열의 통계적인 속성이 시간의 영향을 받지 않는 것을 의미합니다. 대체적으로 일정한 패턴을 갖는 경우를 말합니다.
- 이미지는 특정 패턴을 갖고 있습니다. convolution 연산의 핵심 아이디어는 증폭 또는 축소를 통한 특징 및 패턴 추출입니다. 이런 관점에서 바라보면 stationary는 convolution 연산과 매우 좋은 시너지를 발휘합니다.
- Locality of pixel dependencies
- locality of pixel dependencies는 이미지는 작은 특징들의 구성이기 때문에 픽셀들은 주변의 일부 픽셀에 한해서만 영향을 받는다는 것입니다.
- 간단히 말하면 이미지는 여러개의 픽셀로 구성되는 데 특정 지역(locality)에 있는 픽셀은 이미지 전체에 영향을 받는 것이 아닌 해당 부분의 근처 픽셀들의 영향을 받는 것입니다. 즉 코 근처의 픽셀은 눈이나 입 부근의 픽셀의 영향을 받는 것이 아닌 코를 구성하는 콧볼, 콧대같은 픽셀의 영향을 받는다는 것입니다.
- 이러한 점은 stride에 따라 모든 이미지를 convolution하는게 아닌 부분적인 이미지에 convolution을 적용하는 CNN과 잘 맞는다는 것을 알 수 있습니다.
- Stationary of statistics
궁금증
- Introduction 파트를 읽으면서 큰 규모의 데이터 학습에 있어서 매우 큰 복잡도를 갖는 모델이 필요하여 ImageNet에 적용하기 어렵다는 부분이 있었습니다.
(원문 : However, the immense complexity of the object recognition task means that this prob- lem cannot be specified even by a dataset as large as ImageNet, so our model should also have lots of prior knowledge to compensate for all the data we don’t have.)
CNN의 가장 큰 장점은 이미지 해상도가 높아져도 kernel의 크기는 고정적으로 유지되므로 weight parameter의 크기에 대한 부담이 적다라는 것이라서 이 부분을 “기존의 Fully-connected만으로는 224 X 224의 고해상도 이미지는 각 픽셀 개수에 비례해서 layer의 weight가 필요해서 무리가 있다는 것” 으로 이해했는데 이게 맞는 이해인지가 확실치 않습니다.
2. The Dataset
Chapter 요약
- ImageNet 데이터 셋은 약 22000개의 카테고리에 속하는 총 1500만개의 라벨링 고해상도 이미지로 구성되어 있음
- ILSVRC에는 1000개의 카테고리에 각각 약 1000개의 이미지가 있는 ImageNet의 subset을 사용함
- 120만개의 train set, 5만개의 valid set, 15만개의 test set으로 구성
- 측정 기준은 top-1 error, top-5 error를 사용하였음
- ImageNet은 가변 해상도로 구성되어 있어 모델에 적용할 때는 256 X 256의 고정 해상도로 다운샘플링해야 했음
- 직사각형 이미지가 주어질 경우 짧은 변을 256이 되게 크기를 조정하고 중앙 256 X 256 패치를 사용했음
- 데이터 셋의 정규화 과정을 제외하고는 추가적인 데이터 전처리는 하지 않았음
(원문 : We did not pre-process the images in any other way, except for subtracting the mean activity over the training set from each pixel.) - 신경망은 raw RGB 값의 이미지로 훈련을 진행함
Chapter 분석
- top-1 error, top-5 error
내용 참고 : 이미지 분류 모델 평가에 사용되는 top-5 error와 top-1 error- top-n error는 일반적으로 이미지 분류(image classification)에서 많이 사용되는 평가 지표입니다. 일반적으로 top-1 error와 top-5 error를 많이 씁니다.
- top-1 error는 모델의 카테고리 분류 결과 중 상위 확률 1개의 카테고리가 정답과 같다면 top-1 error는 0%입니다. 만약 분류 카테고리가 5개인 상황에서 모델이
[0.1, 0.2, 0.25, 0.3, 0.15]라는 결과를 내면 정답 class는 3이라고 처리합니다. 이때 실제 정답이 3이 맞다면 top-1 error는 0%입니다. - 그렇다면 이를 활용하여 top-5 error를 이해해봅시다. top-1은 상위 1개의 class가 정답 클래스와 같은지를 확인합니다. top-5 error는 모델의 예측에서 상위 5개의 클래스를 확인합니다. 상위 5개의 class에 정답 class가 있는지 없는지를 확인 합니다.
![]()
- 픽셀 정규화
Why substracting dataset’s image mean?- 각 이미지의 pixel에 training set의 평균을 제거해서 normalize를 진행합니다.
- 이 전처리는 정형 데이터(tabular data)에서 feature별 정규화를 진행하는 것과 같은 역할을 합니다.

3. The Architecture
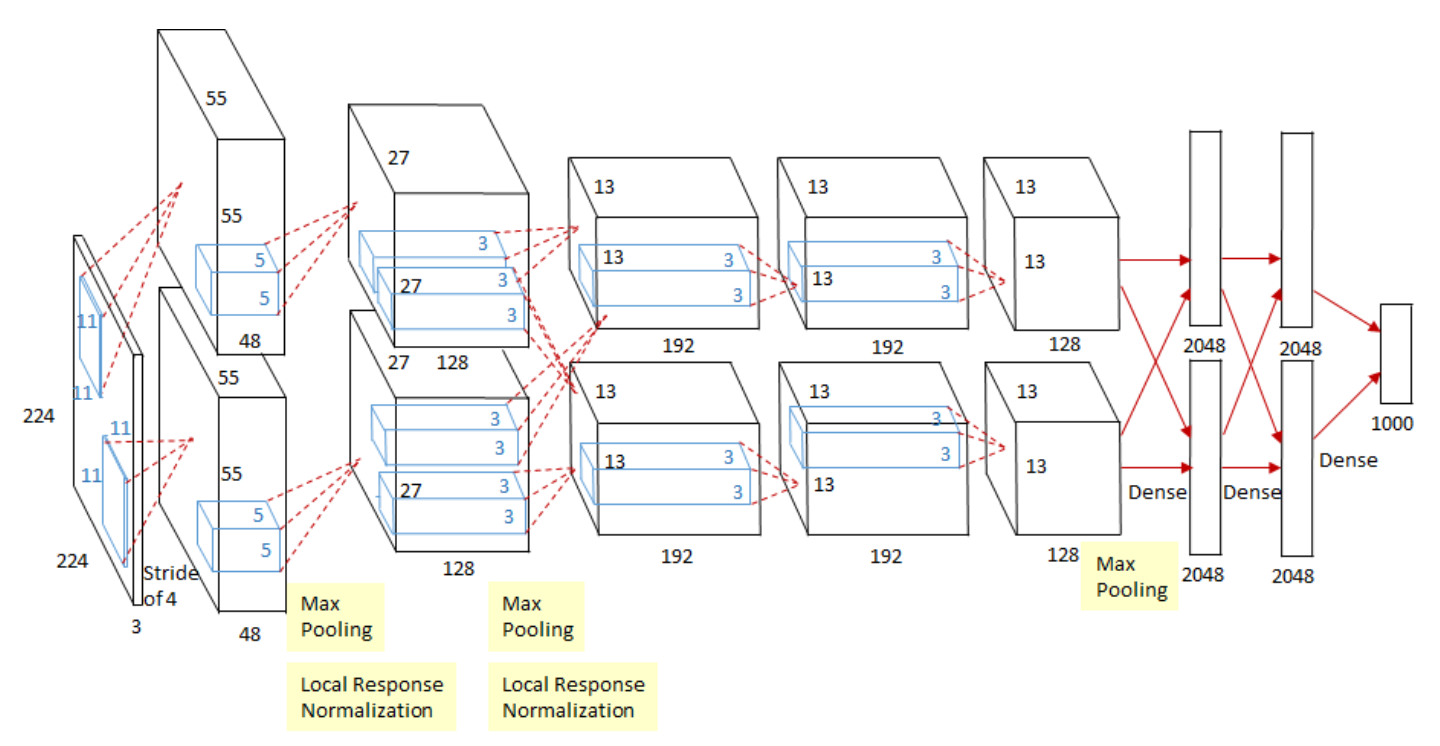 AlexNet 구조 | 출처 : Deep Learning’s Most Important Ideas - A Brief Historical Review
AlexNet 구조 | 출처 : Deep Learning’s Most Important Ideas - A Brief Historical Review
5개의 convolution layer와 3개의 fully-connected layer로 구성된 총 8개의 학습 layer로 구성
- 중요도에 따라 3.1 ~ 3.4 순서로 설명
3.1 ReLU Nonlinearity
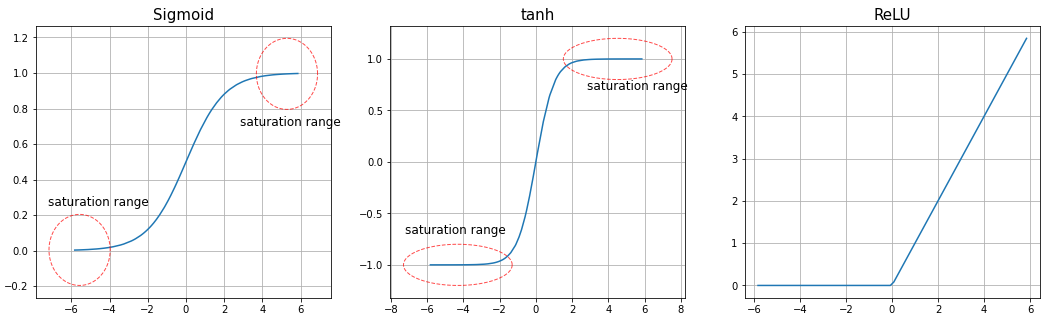
- 기존에 자주 쓰이던 비선형 함수인 $\tanh$, sigmoid는 포화 비선형성 함수(saturating nonlinearities)였음
- 기존 비선형 함수는 함수 특성상 saturation 지점이 발생하여 vanishing gradient 문제가 발생
- 이를 해결하고자 부분적 non-saturating nonlinearity인 $ReLU = \max(0, x)$ 를 사용
- 결과적으로 $\tanh$보다 몇 배 더 빠른 속도로 loss가 수렴
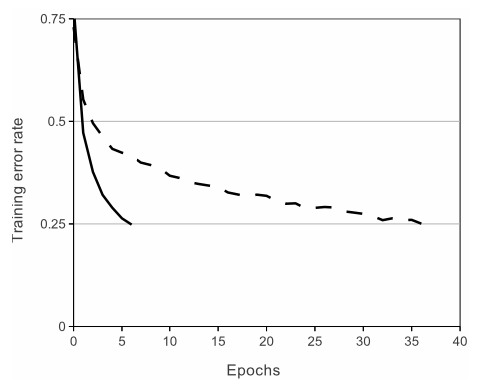 CIFAR-10 데이터셋의 25% training error 도달에 필요한 epochs 수
CIFAR-10 데이터셋의 25% training error 도달에 필요한 epochs 수
- 전통적인 activation function을 사용했다면 큰 규모의 Neural Net 구성이 불가능했을 것
- 단, 최초로 전통적 CNN의 대안을 제안한 것은 아님
- 이전에 Improving neural networks by preventing co-adaptation of feature detectors에서 $|\tanh(x)|$을 사용한 적이 있음
- 하지만 이 논문의 관찰 포인트는 overfitting을 방지하는 것이므로 속도를 높이는 것과는 약간 다른 방향성을 가짐
- 빠른 학습 속도는 큰 데이터로 훈련된 큰 모델 성능에 큰 영향을 줌
3.2 Training on Multiple GPUS
- 모델 학습에 GTX 580 GPU를 사용하였지만 1개를 사용하면 네트워크 크기가 제한됨
- 이를 해결하고자 2개의 GPU로 학습을 하였는데, 이를 GPU parallelization이라 함
- GPU 병렬화를 사용한 방법에는 크게 2가지 기법이 사용됨
- 전체 커널을 절반씩 나눠 각각의 GPU에 할당함
- 특정 레이어에서 나눠진 GPU를 통합시켜 학습을 진행
- 논문에서는 3번째 Conv layer에서만 GPU를 통합
- 결과적으로 계산량의 허용가능한 부분까지 통신량을 정확하게 조정가능
 위의 48개 커널은 GPU1, 아래 48개 커널은 GPU2의 학습 kernel map
위의 48개 커널은 GPU1, 아래 48개 커널은 GPU2의 학습 kernel map
- 각 GPU는 독립적으로 학습하는 과정에서 이런 현상이 매번 발생함
- 논문에서는 Specialization이라고 함
- GPU를 분산해서 처리한 결과 top-1과 top-5 error를 1.7%, 1.2% 감소하는 효과를 보임
- 추가적으로 2개 GPU는 1개 GPU보다 약간 빠른 학습속도를 보임
3.3 Local Response Normalization (LRN)

- LRN은 generalization을 위해 진행
- 최근에는 LRN보다는 Batch Normalization으로 대체됨
- LRN을 진행하는 이유는 ReLU의 양수를 살리는 성질때문
- ReLU는 양수값을 그대로 받아 neuron에 전달하므로 image에 존재하는 매우 큰값이 존재하면 주변부 낮은 값의 정보를 neuron에 전달을 방해하는 later inhibition이 발생
- LRN은 later inhibition을 방지하는 형태로 구현
- 변수 설명
- $b_{x,y}^{i}$ : x, y 위치에 적용된 $i$번째 kernel의 정규화된 output
- $a_{x,y}^{i}$ : x, y 위치에 적용된 $i$번째 kernel의 output
- $N$ : 총 kernel의 수
- $n$ : 정규화 이웃의 수 (hyperparameter)
- $\alpha$, $\beta$, $k$ : hyperparameters
- hyperparameter는 $k=2, n=5, \alpha=10^{-4}, \beta-0.75$로 실험
- 특정 레이어에서 ReLU를 통과한 후 normalization 진행
- 정규화를 진행한 결과 top-1과 top-5 error가 1.4%, 1.2% 감소하는 효과를 보여줌
3.4 Overlapping Pooling
- 기존의 겹치지 않고 독립적으로 pooling을 하는 방식이 아닌 중첩하는 방식의 Pooling을 사용
- 이 과정은 과적합을 방지하는 방법으로 사용함
- pooling layer의 세팅은 kernel size=3, stride=2을 사용함
- 적용 결과 top-1, top-5 error는 0.4%, 0.3% 감소
3.5 Overall Architecture
AlexNet 구조 | 출처 : Deep Learning’s Most Important Ideas - A Brief Historical Review
- 전체 8개의 레이어 (5 Conv + 3 FC)
- output FC에는 1000-way softmax 활용
- output class는 1000개
- Convolution Layer Setting
- 2, 4, 5번째 레이어는 같은 GPU상의 이전 레이어에 있는 kernel map과 연결
- 3번째 레이어에서는 2번째 레이어의 모든 kernel map을 연결
- LRN layer는 1, 2번째 레이어에 적용
- Max-pooling 모든 LRN layer 이후에 적용하고 5번째 레이어에도 적용
- ReLU는 모든 레이어의 결과에 적용
- 그 외 다른 부분에 있는 내용도 추가해보면….
- pooling layer의 세팅은 kernel size=3, stride=2을 사용함
- LRN layer의 hyperparameter는 $k=2, n=5, \alpha=10^{-4}, \beta-0.75$로 실험
- init weight, bias참고해서 bias, weight 초기화
- 구현시 첫번째 CNN을 제외하고 padding, stride가 언급되지 않아서 직접 계산해야하는 것 같음
\(O = \frac{I - K + 2P}{S} + 1\)- $O$ : size of output image
- $I$ : size of input image
- $K$ : size of kernel in Conv layer
- $N$ : Number of kernels
- $S$ : Stride
- $P$ : padding
Chapter 분석
- 전반적인 AlexNet의 구조와 핵심 포인트들을 설명하고 있습니다.
- 현재 CV 분야에서는 이미 많이 사용된 내용들이라 자세하게 다룰 내용이 크게 없었습니다.
- 실제 구현시 최종 구조에 적힌 레이어별 특성을 참고하면 좋을 것 같습니다.
4. Reducing Overfitting
- AlexNet은 6천만개의 parameter를 가짐
- 많은 수의 parameter 때문에 1000개의 class를 분류하는 과정에서 overfitting이 필연적으로 발생함
- overfitting을 줄이고자 2가지 방식을 사용
4.1 Data Augmentation
- ovefitting을 가장 쉽게 줄이는 방법은 label을 보존하는 변환 방식을 활용하여 많은 데이터 셋을 구성하는 것
- 이미지를 생성하고 수평반전(horizontal reflections) 을 수행
- 256 X 256 이미지를 224 X 224로 잘라내는데, 중앙, 좌상단, 좌하단, 우상단, 우하단 기준으로 총 5 case로 분류해서 crop
- 이후 각 이미지를 수평반전을 수행
- 이 과정이 없는 경우 network는 상당한 과적합을 보여주었음
- Image RGB의 변화
\([\mathbf{p}_{1},\mathbf{p}_{2},\mathbf{p}_{3}][\alpha_{1}\lambda_{1}, \alpha_{2}\lambda_{2}, \alpha_{3}\lambda_{3}]^{\intercal}\)- tarining set의 RGB pixel에 PCA를 적용했음
- PCA로 나온 각 RGB에 대한 eigen value와 평균이 0, 분산이 0.1인 가우시안 분포에서 추출한 random variable을 곱해 RGB값에 더해줌
- 이 과정은 마치 조명의 영향과 색의 intensity 변화에 대한 불변성을 지내게 함
- 이 기법으로 top-1 error를 1% 감소시킴
4.2 Dropout
- 서로 다른 모델을 결합하는 앙상블 기법은 test error를 감소시키기 효과적인 방법
- AlexNet의 학습 시간 문제로 앙상블 기법을 활용하기엔 무리가 있었음
- 비슷한 효과를 주는 Dropout을 모델에 적용
- probability = 0.5로 설정
- 입력마다 dropout을 적용하면 가중치는 공유되지만 신경망의 구조는 변화됨
- neuron은 특정한 다른 neuron의 존재성에 영향을 받지 않음
- train에서 dropout을 적용하고 test 과정에서는 모든 neuron을 활용하는 대신 neuro의 결과에 0.5를 곱해서 사용함
- Dropout은 첫 2개의 FC layer에만 적용
- 수렴에 필요한 iteration은 2배 증가하였음
5. Details of learning
- 전반적인 실험에 사용한 Hyper-parameters 정보
- SGD(momentum=0.9, batch_size=128, weightdecay=0.0005)를 사용
- 각 layer의 weight는 평균이 0, 분산이 0.01인 가우시안 분포 사용하여 초기롸
- 2, 4, 5번째 conv layer의 bias와 FC의 bias는 모두 1로 초기화
- 그 외 나머지 bias는 0으로 초기화
- 모든 layer에 동일한 learning rate를 적용하였음
- 0.01로 시작해서 validation error가 상향되지 않으면 10으로 나눠주었고 학습 종료전에 3번의 감소과정이 있었음
6. Results

- ILSVRC-2012에서 top-5 error의 test error를 16.4%를 기록하며 우승
- 일부 라벨링이 굉장히 애매한 케이스를 제외하고 대부분 정답을 나타냄
- 또한 top-5 class의 분류도 실제 답과 매우 유사한 클래스들이 많이 나타남
- Euclidean distance를 계산해서 거리가 짧을수록 유사한 사물로 인지한다는 점에서 놀라운 성과를 기록
- 당시에는 인간의 뉸의 정확도를 따라가기엔 아직 멀었다고 하지만 CNN 발전의 초석이 된 AlexNet은 충분히 혁신적인 모델이라고 할 수 있음
Comments powered by Disqus.