
DKT : DKT 이해 및 DKT Trend
DKT란?
- 최근 연구가 활발히 이루어지고 있는 분야
- 기존에도 지식 상태를 추적하는 Knowledge Tracing(KT) 연구는 있었음
- 기존의 KT에 Deep Learning을 적용하는 방식이라고 해서 DKT라는 이름이 붙음
Knowledge Tracing
- Knowledge Tracing이란 교육을 진행하고 테스트를 통해 얻은 지식의 정도를 확인하는 것
- 예를 들어 사칙연산 퀴즈를 봤을 때 학생이 각 연산의 문제를 얼마나 잘 푸는지? 를 연구하는 것
- 문제의 정답률은 곧 해당 문제의 해결책에 대한 이해라고 볼 수 있음
- 지식이라는 것은 축적됨에 따라 상태가 계속 변화하므로 지속적인 추적이 중요함
- 결국 사용자의 문제 풀이 정보가 추가될수록 지식 상태 예측률이 높아짐
- 학습한 지식 상태를 기반으로 다음 문제를 맞출지 예측하는 task가 DKT
- 다음 문제의 정답 여부에 따라 지식 상태를 수정
- 문제점
- 문제 유형에 맞춰 어느정도 데이터 양이 확보된다면 충분히 정답률에 대한 신뢰성이 보장
- 하지만 유형에 대한 데이터 정보가 적으면 정답률의 신뢰성이 떨어짐 (= Overfitting 발생)
- ex) 빼기 문제 유형이 1개인데 맞출경우 정답률은 100%지만 학생이 빼기를 완전히 이해했다고 보기는 어려움
- 이런 문제점은 competition이냐 실제 서비스냐에 따라 해결책이 달라짐
- competition : 주어진 data이므로 feature engineering이나 skill에 달려있음
- 실제 서비스 : overfitting 문제는 data의 추가로 해결할 수 있고 문제를 새롭게 다시 정의하는 것도 도움이 됨
- DKT의 최종목적은 학생의 지식 이해도를 통해 문제를 추천하고 학업 성취도를 파악하는 것
이번 주부터 DKT competition이 시작됩니다. 처음 만나보는 분야라 조금 낯설지만 생각보다 흥미로운 주제입니다. DKT에 대한 코멘트를 남기고 싶지만 강의를 통해 좀 더 공부를 해야 의문점들이 생길 것으로 보입니다.
대회 소개
대회 목적
- 특정 유저에 대한 문제에 따른 정답 상태가 주어졌고 sequential한 정답 case를 토대로 마지막 문제의 정답 확률을 예측
Metric 이해
- 대회에서 활용되는 평가 지표는 AUROC와 ACC
- ACC는 단순 정답률을 의미
AUROC
- AUROC란 Area Under the ROC Curve의 약자로 False Positive와 True Positive의 비율을 보여주는 그래프
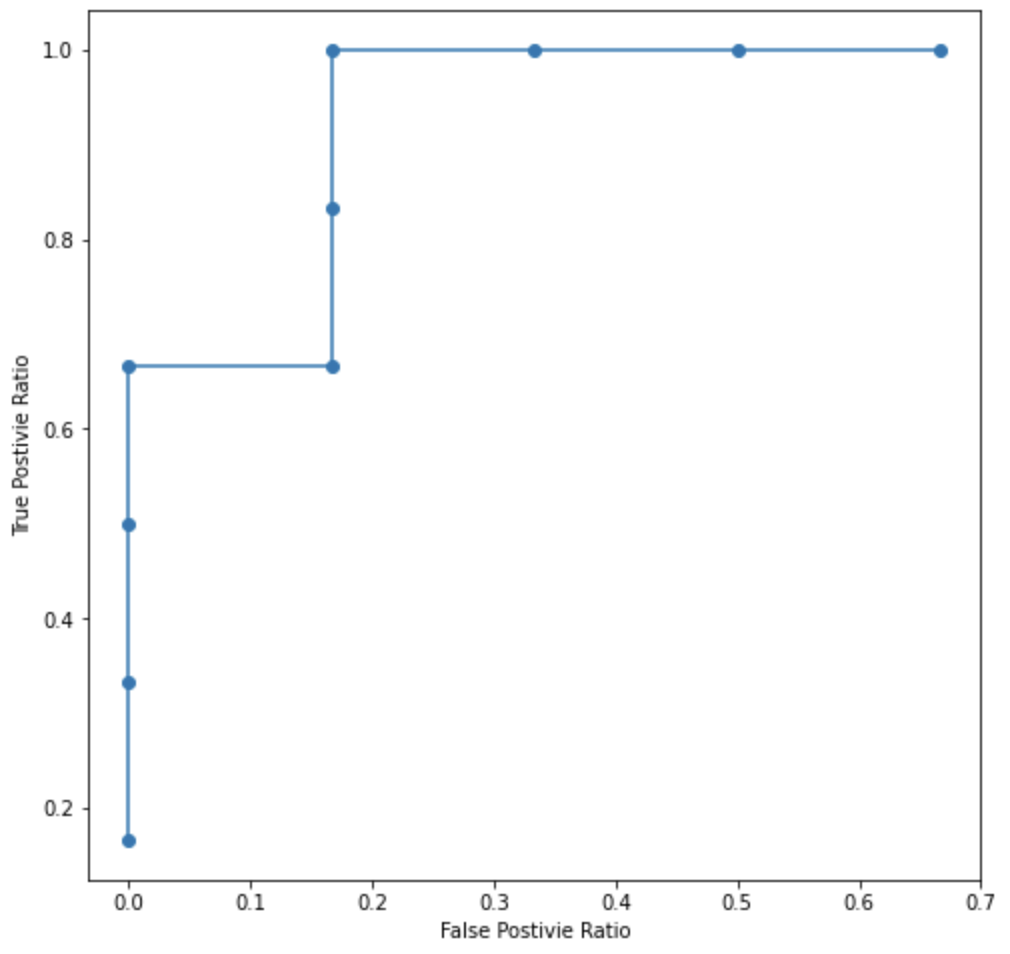 간단하게 10개 데이터를 통해 만든 그래프
간단하게 10개 데이터를 통해 만든 그래프
- 단순 Recall과 Precision, F1-Score과 같은 정보의 한계를 극복하고자 나타난 지표
- ROC curve 밑부분의 면적값을 AUROC라고 함
- 단순 ROC Curve는 thresh hold의 영향이 많이 미치기 때문
- 결과적으로 이진 분류 문제에서 0과 1의 분포가 얼마나 안 겹치는 지 정도를 보여주는 척도
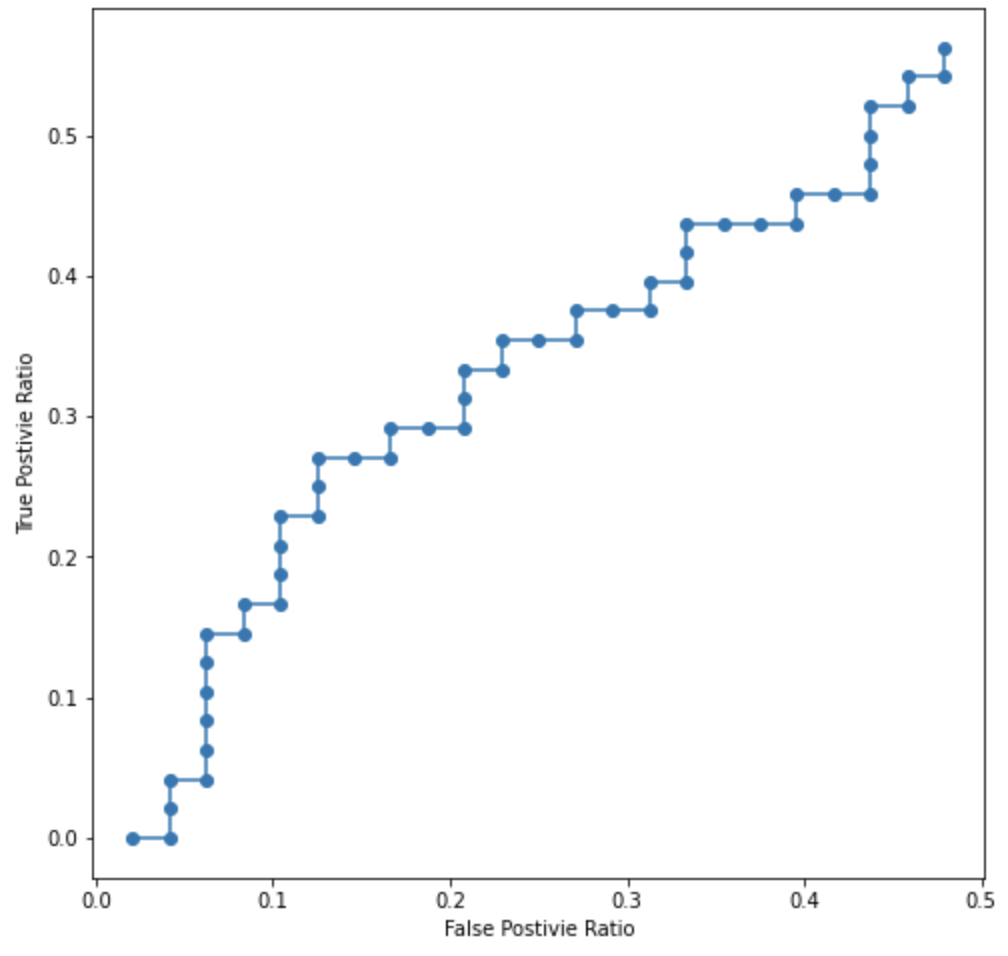 간단하게 100개 데이터를 랜덤으로 생성해 만든 그래프
간단하게 100개 데이터를 랜덤으로 생성해 만든 그래프
- 실제로 랜덤하게 AUROC 그래프를 그리면 대각선과 유사하게 나타남
- 장점
- AUROC는 척도 불변 성질이 있어서 예측이 얼마나 잘 되었는지 평가하기 좋음
- 분류 임계값(thresh hold)불변 성질때문에 임계값을 무시하고 모델 품질의 예측이 가능
- 문제점
- 잘 보정된 확률 결과를 필요로 하는 경우 AUROC는 알 수 없음
- imbalance data에 대해서 AUROC는 비교적으로 높게 측정되는 경향이 있음
- 예를 들어 FPR에 대해서 정보가 많아서 폭이 촘촘한 경우 TPR 증가 비율과 FPR 증가비율이 다르기 때문에 그래프의 넓이에 영향을 줌
DKT History
- DKT는 task의 특성상 sequential modeling의 특성을 띄고 있음
- 따라서 NLP의 발전사가 크게 영향을 미침
- 모델의 자세한 설명이 크게 관심 있지는 않아서 적당히 변화만 짚고 넘어갈 것
RNN
- 기본적인 MLP를 재귀순환 형태로 구조화한 모델
- BPTT 방식으로 back propagation 진행
- 장문장의 경우 멀리 떨어진 단어와의 관계가 소멸되는 short-term memory 문제 발생
LSTM, GRU
- RNN의 문제인 short-term memory 문제를 해결하고자 나타난 모델
- 기억할 부분들과 불필요한 부분들을 설정하는 LSTM 모델 등장
- Forget Gate, Input Gate, Output Gate 총 3개의 Gate를 통해 cell state 내용을 조절함
- Gate를 감소한 GRU도 탄생
Seq2Seq
- 다른 언어 도메인끼리의 연결을 만들고자 나타난 아이디어
- Encoder와 Decoder로 표현되는 context vector를 통해 서로 다른 언어 도메인을 연결
- 문장이 길어지는 경우 한 개의 context vector에 표현하는 과정에 한계가 발생
Attention
- Seq2Seq의 문제를 해결하고자 context vector + encoder data를 decoder에 전달하는 attention이 개발
- 하지만 RNN 방식을 사용하는 sequential 연결 방식의 문제인 학습 속도 문제가 발생
Transformer
- Attention 아이디어를 활용하되 sequential을 제거하는 방식을 도입
- 문제는 순서 정보를 어떻게 활용해야하는가?
- 각 단어의 순서 정보는 Positional Encoding을 진행
- 현재는 Positional Embedding
Comments powered by Disqus.